Achtung! Attention!
Aufmerksamkeit ist in den letzten Jahren ein ziemlich beliebtes Konzept und ein nützliches Werkzeug in der Deep-Learning-Community. In diesem Beitrag werden wir uns ansehen, wie die Aufmerksamkeit erfunden wurde, und verschiedene Aufmerksamkeitsmechanismen und -modelle wie Transformer und SNAIL.
Aufmerksamkeit ist bis zu einem gewissen Grad dadurch motiviert, wie wir verschiedenen Regionen eines Bildes visuelle Aufmerksamkeit schenken oder Wörter in einem Satz miteinander in Beziehung setzen. Nehmen wir das Bild eines Shiba Inu in Abb. 1 als Beispiel.

Abb. 1. Ein Shiba Inu in einem Herrenoutfit. Das Originalfoto stammt von Instagram @mensweardog.
Die menschliche visuelle Aufmerksamkeit ermöglicht es uns, uns auf einen bestimmten Bereich mit „hoher Auflösung“ zu konzentrieren (z. B. auf das spitze Ohr im gelben Kasten), während wir das umgebende Bild mit „niedriger Auflösung“ wahrnehmen (z. B. was ist jetzt mit dem verschneiten Hintergrund und dem Outfit?), und dann den Fokuspunkt anzupassen oder die Schlussfolgerung entsprechend zu ziehen. Bei einem kleinen Bildausschnitt geben die Pixel im Rest des Bildes Hinweise darauf, was dort angezeigt werden sollte. Wir erwarten ein spitzes Ohr im gelben Kästchen, weil wir eine Hundenase, ein weiteres spitzes Ohr auf der rechten Seite und die geheimnisvollen Augen des Shiba (in den roten Kästchen) gesehen haben. Der Pullover und die Decke unten wären jedoch nicht so hilfreich wie diese hündischen Merkmale.
In ähnlicher Weise können wir die Beziehung zwischen Wörtern in einem Satz oder engen Zusammenhang erklären. Wenn wir „essen“ sehen, erwarten wir, dass wir sehr bald auf ein Wort für Essen stoßen werden. Der Farbbegriff beschreibt das Essen, aber wahrscheinlich nicht so sehr mit „essen“ direkt.
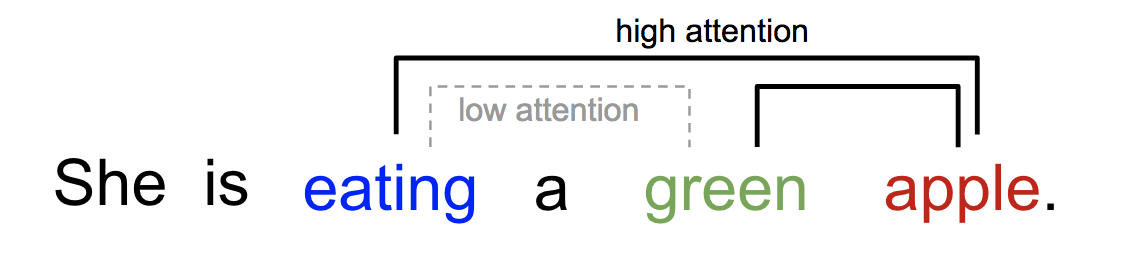
Abb. 2. Ein Wort „widmet“ sich anderen Wörtern im selben Satz auf unterschiedliche Weise.
Auf den Punkt gebracht, kann man Aufmerksamkeit beim Deep Learning im Großen und Ganzen als einen Vektor von Wichtigkeitsgewichten interpretieren: Um ein Element, z. B. ein Pixel in einem Bild oder ein Wort in einem Satz, vorherzusagen oder abzuleiten, schätzen wir mithilfe des Aufmerksamkeitsvektors ab, wie stark es mit anderen Elementen korreliert (oder „widmet“, wie Sie vielleicht in vielen Veröffentlichungen gelesen haben), und nehmen die Summe ihrer Werte, gewichtet mit dem Aufmerksamkeitsvektor, als Annäherung an das Ziel.
- Was ist falsch am Seq2Seq-Modell?
- Geboren für die Übersetzung
- Definition
- Eine Familie von Aufmerksamkeitsmechanismen
- Zusammenfassung
- Self-Attention
- Soft vs. Hard Attention
- Globale vs. lokale Aufmerksamkeit
- Neuronale Turingmaschinen
- Lesen und Schreiben
- Aufmerksamkeitsmechanismen
- Zeigernetzwerk
- Transformer
- Schlüssel, Wert und Abfrage
- Multi-Head Self-Attention
- Encoder
- Alle Unterschichten geben Daten derselben Dimension \(d_\text{model} = 512\) aus. Decoder
- Vollständige Architektur
- SNAIL
- Self-Attention GAN
Was ist falsch am Seq2Seq-Modell?
Das seq2seq-Modell wurde im Bereich der Sprachmodellierung entwickelt (Sutskever, et al. 2014). Grob gesagt, zielt es darauf ab, eine Eingabesequenz (Quelle) in eine neue (Ziel) zu transformieren, wobei beide Sequenzen beliebig lang sein können. Beispiele für Transformationsaufgaben sind die maschinelle Übersetzung zwischen mehreren Sprachen in Text oder Audio, die Generierung von Frage-Antwort-Dialogen oder sogar das Parsen von Sätzen in Grammatikbäume.
Das seq2seq-Modell hat normalerweise eine Encoder-Decoder-Architektur, die sich wie folgt zusammensetzt:
- Ein Encoder verarbeitet die Eingabesequenz und komprimiert die Informationen in einen Kontextvektor (auch bekannt als Satzeinbettung oder „Gedanken“-Vektor) mit einer festen Länge. Von dieser Repräsentation wird erwartet, dass sie eine gute Zusammenfassung der Bedeutung der gesamten Quellsequenz darstellt.
- Ein Decoder wird mit dem Kontextvektor initialisiert, um die transformierte Ausgabe auszugeben. In frühen Arbeiten wurde nur der letzte Zustand des Encodernetzes als Anfangszustand des Decoders verwendet.
Beide, Encoder und Decoder, sind rekurrente neuronale Netze, d.h. sie verwenden LSTM- oder GRU-Einheiten.
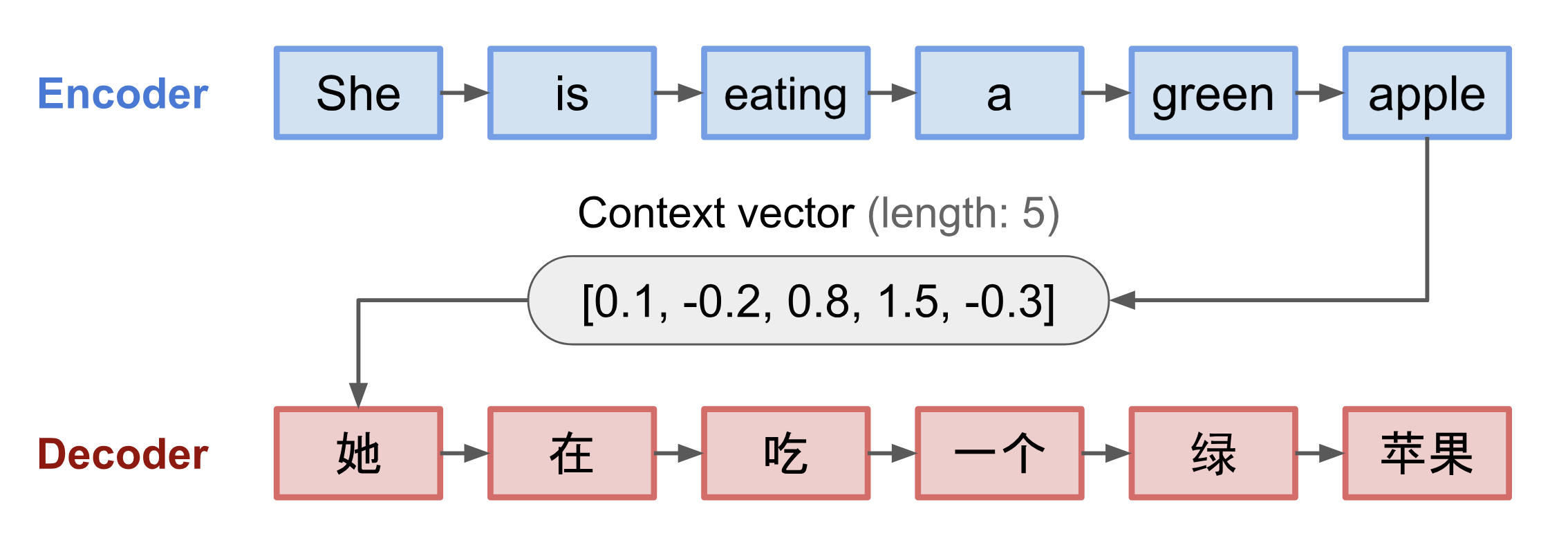
Abb. 3. Das Encoder-Decoder-Modell, das den Satz „sie isst einen grünen Apfel“ ins Chinesische übersetzt. Die Visualisierung sowohl des Encoders als auch des Decoders wird in der Zeit abgerollt.
Ein kritischer und offensichtlicher Nachteil dieses Kontextvektor-Designs mit fester Länge ist die Unfähigkeit, sich lange Sätze zu merken. Oft hat es den ersten Teil vergessen, sobald es die gesamte Eingabe verarbeitet hat. Der Aufmerksamkeitsmechanismus wurde geboren (Bahdanau et al., 2015), um dieses Problem zu lösen.
Geboren für die Übersetzung
Der Aufmerksamkeitsmechanismus wurde geboren, um bei der neuronalen maschinellen Übersetzung (NMT) das Einprägen langer Ausgangssätze zu unterstützen. Anstatt einen einzelnen Kontextvektor aus dem letzten verborgenen Zustand des Encoders zu erstellen, besteht die geheime Soße der Aufmerksamkeit darin, Verknüpfungen zwischen dem Kontextvektor und der gesamten Quelleingabe herzustellen. Die Gewichte dieser Verknüpfungen sind für jedes Ausgabeelement anpassbar.
Da der Kontextvektor Zugriff auf die gesamte Eingabesequenz hat, müssen wir uns nicht um das Vergessen kümmern. Die Ausrichtung zwischen Quelle und Ziel wird vom Kontextvektor gelernt und kontrolliert. Im Wesentlichen verbraucht der Kontextvektor drei Informationen:
- versteckte Encoder-Zustände;
- versteckte Decoder-Zustände;
- Ausrichtung zwischen Quelle und Ziel.
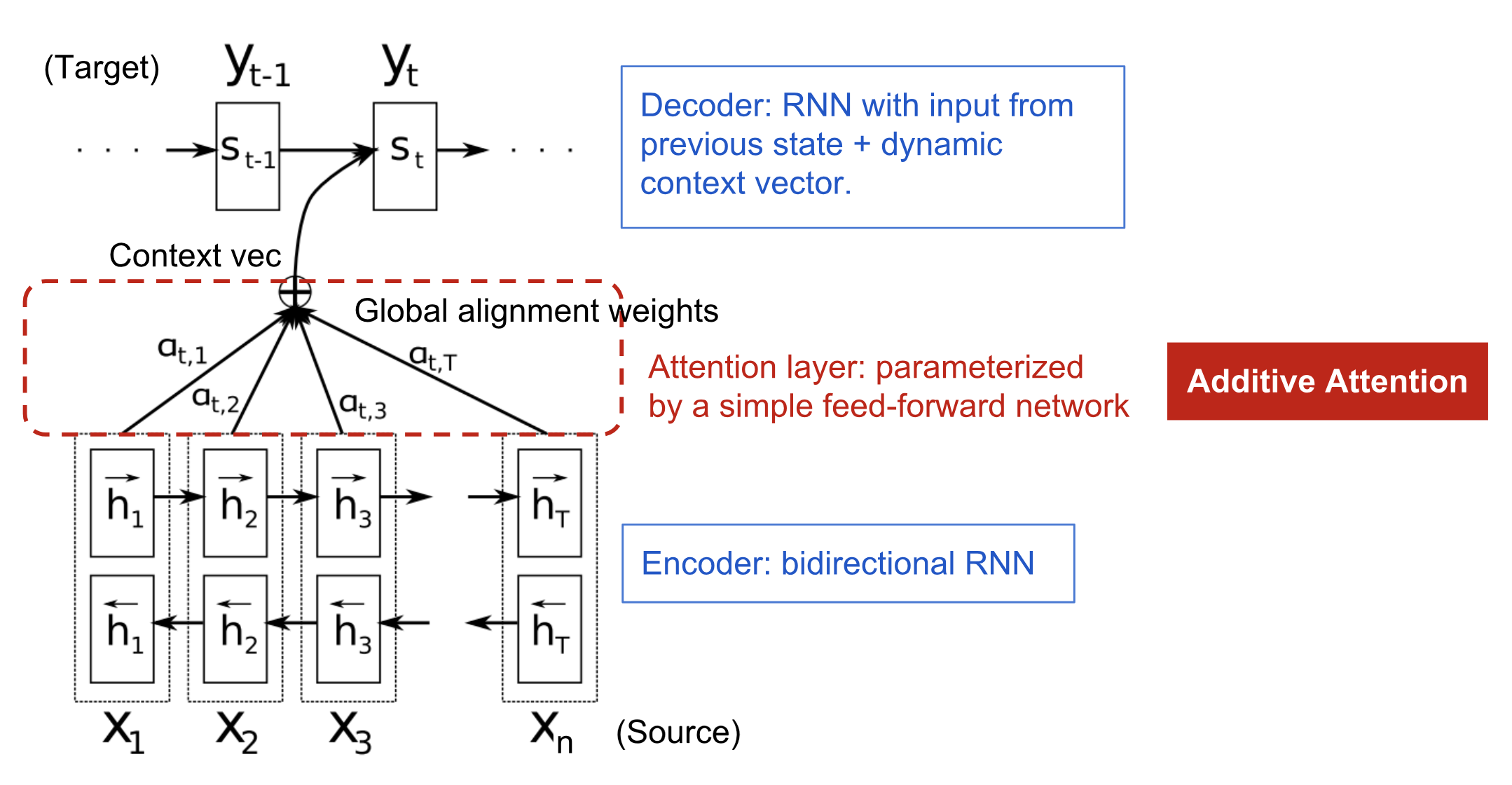
Abbildung 4. Das Encoder-Decoder-Modell mit additivem Aufmerksamkeitsmechanismus aus Bahdanau et al. (2015).
Definition
\\mathbf{y} &= \end{aligned}\]
(Fettgedruckte Variablen zeigen an, dass es sich um Vektoren handelt; dasselbe gilt für alles andere in diesem Beitrag.)
Der Encoder ist ein bidirektionales RNN (oder eine andere rekurrente Netzwerkeinstellung Ihrer Wahl) mit einem vorwärts gerichteten versteckten Zustand \(\overrightarrow{\boldsymbol{h}}_i\) und einem rückwärts gerichteten \(\overleftarrow{\boldsymbol{h}}_i\). Eine einfache Verkettung der beiden stellt den Zustand des Encoders dar. Die Motivation besteht darin, sowohl das vorangehende als auch das nachfolgende Wort in die Annotation eines Wortes einzubeziehen.
\^\top, i=1,\dots,n\]\\)\]
wobei sowohl \(\mathbf{v}_a\) als auch \(\mathbf{W}_a\) Gewichtsmatrizen sind, die im Alignment-Modell gelernt werden.
Die Matrix der Alignment Scores ist ein schönes Nebenprodukt, um die Korrelation zwischen Quell- und Zielwörtern explizit darzustellen.

Abb. 5. Alignment-Matrix von „L’accord sur l’Espace économique européen a été signé en août 1992“ (Französisch) und seiner englischen Übersetzung „The agreement on the European Economic Area was signed in August 1992“. (Bildquelle: Abb. 3 in Bahdanau et al., 2015)
Sehen Sie sich dieses nette Tutorial des Tensorflow-Teams an, um weitere Implementierungsanweisungen zu erhalten.
Eine Familie von Aufmerksamkeitsmechanismen
Mit Hilfe der Aufmerksamkeit werden die Abhängigkeiten zwischen Quell- und Zielsequenzen nicht mehr durch den Zwischenabstand eingeschränkt! Angesichts der großen Fortschritte, die die Aufmerksamkeit in der maschinellen Übersetzung erzielt hat, wurde sie bald auf den Bereich des Computersehens ausgeweitet (Xu et al. 2015) und man begann, verschiedene andere Formen von Aufmerksamkeitsmechanismen zu erforschen (Luong, et al., 2015; Britz et al., 2017; Vaswani, et al, 2017).
Zusammenfassung
Nachfolgend finden Sie eine zusammenfassende Tabelle mit verschiedenen populären Aufmerksamkeitsmechanismen und entsprechenden Alignment-Score-Funktionen:
Hier finden Sie eine Zusammenfassung der breiteren Kategorien von Aufmerksamkeitsmechanismen:
| Name | Definition | Zitat |
|---|---|---|
| Selbstaufmerksamkeit(&) | Vergleichen verschiedener Positionen derselben Eingabesequenz. Theoretisch kann die Selbstaufmerksamkeit jede der obigen Bewertungsfunktionen übernehmen, aber nur die Zielsequenz durch dieselbe Eingabesequenz ersetzen. | Cheng2016 |
| Global/Soft | Aufmerksamkeit für den gesamten Eingabezustandsraum. | Xu2015 |
| Lokal/Hart | Aufmerksam auf einen Teil des Eingangszustandsraums, d.h. einen Ausschnitt des Eingangsbildes. | Xu2015; Luong2015 |
(&) Auch als „intra-attention“ in Cheng et al, 2016 und einigen anderen Arbeiten.
Self-Attention
Self-Attention, auch bekannt als Intra-Attention, ist ein Aufmerksamkeitsmechanismus, der verschiedene Positionen einer einzelnen Sequenz in Beziehung setzt, um eine Repräsentation derselben Sequenz zu berechnen. Sie hat sich beim maschinellen Lesen, bei der abstrakten Zusammenfassung und bei der Erstellung von Bildbeschreibungen als sehr nützlich erwiesen.
In der Arbeit über das Netzwerk des Kurzzeitgedächtnisses wurde die Selbstaufmerksamkeit für das maschinelle Lesen verwendet. Im folgenden Beispiel ermöglicht uns der Mechanismus der Selbstaufmerksamkeit, die Korrelation zwischen den aktuellen Wörtern und dem vorherigen Teil des Satzes zu lernen.

Abbildung 6. Das aktuelle Wort ist rot und die Größe des blauen Schattens zeigt den Aktivierungsgrad an. (Bildquelle: Cheng et al., 2016)
Soft vs. Hard Attention
In der Arbeit Show, attend and tell wird der Aufmerksamkeitsmechanismus auf Bilder angewendet, um Bildunterschriften zu erzeugen. Das Bild wird zunächst von einem CNN kodiert, um Merkmale zu extrahieren. Dann verarbeitet ein LSTM-Decoder die Faltungsmerkmale, um ein beschreibendes Wort nach dem anderen zu erzeugen, wobei die Gewichte durch Aufmerksamkeit gelernt werden. Die Visualisierung der Aufmerksamkeitsgewichte zeigt deutlich, auf welche Bereiche des Bildes das Modell achtet, um ein bestimmtes Wort auszugeben.

Abb. 7. „Eine Frau wirft ein Frisbee in einem Park.“ (Bildquelle: Abb. 6(b) in Xu et al. 2015)
In dieser Arbeit wurde erstmals die Unterscheidung zwischen „weicher“ und „harter“ Aufmerksamkeit vorgeschlagen, basierend darauf, ob die Aufmerksamkeit Zugriff auf das gesamte Bild oder nur auf einen Fleck hat:
- Weiche Aufmerksamkeit: die Ausrichtungsgewichte werden gelernt und „weich“ über alle Flecken im Quellbild gelegt; im Wesentlichen die gleiche Art von Aufmerksamkeit wie in Bahdanau et al., 2015.
- Pro: das Modell ist glatt und differenzierbar.
- Contra: teuer, wenn der Quell-Input groß ist.
- Hard Attention: wählt jeweils nur einen Fleck des Bildes zur Aufmerksamkeit aus.
- Pro: weniger Berechnungen zum Zeitpunkt der Inferenz.
- Contra: das Modell ist nicht differenzierbar und erfordert kompliziertere Techniken wie Varianzreduktion oder Verstärkungslernen zum Training. (Luong, et al., 2015)
Globale vs. lokale Aufmerksamkeit
Luong, et al., 2015 haben die „globale“ und „lokale“ Aufmerksamkeit vorgeschlagen. Die globale Aufmerksamkeit ähnelt der weichen Aufmerksamkeit, während die lokale eine interessante Mischung aus harter und weicher Aufmerksamkeit ist, eine Verbesserung gegenüber der harten Aufmerksamkeit, um sie differenzierbar zu machen: Das Modell sagt zunächst eine einzelne ausgerichtete Position für das aktuelle Zielwort voraus und ein Fenster, das um die Ausgangsposition zentriert ist, wird dann verwendet, um einen Kontextvektor zu berechnen.
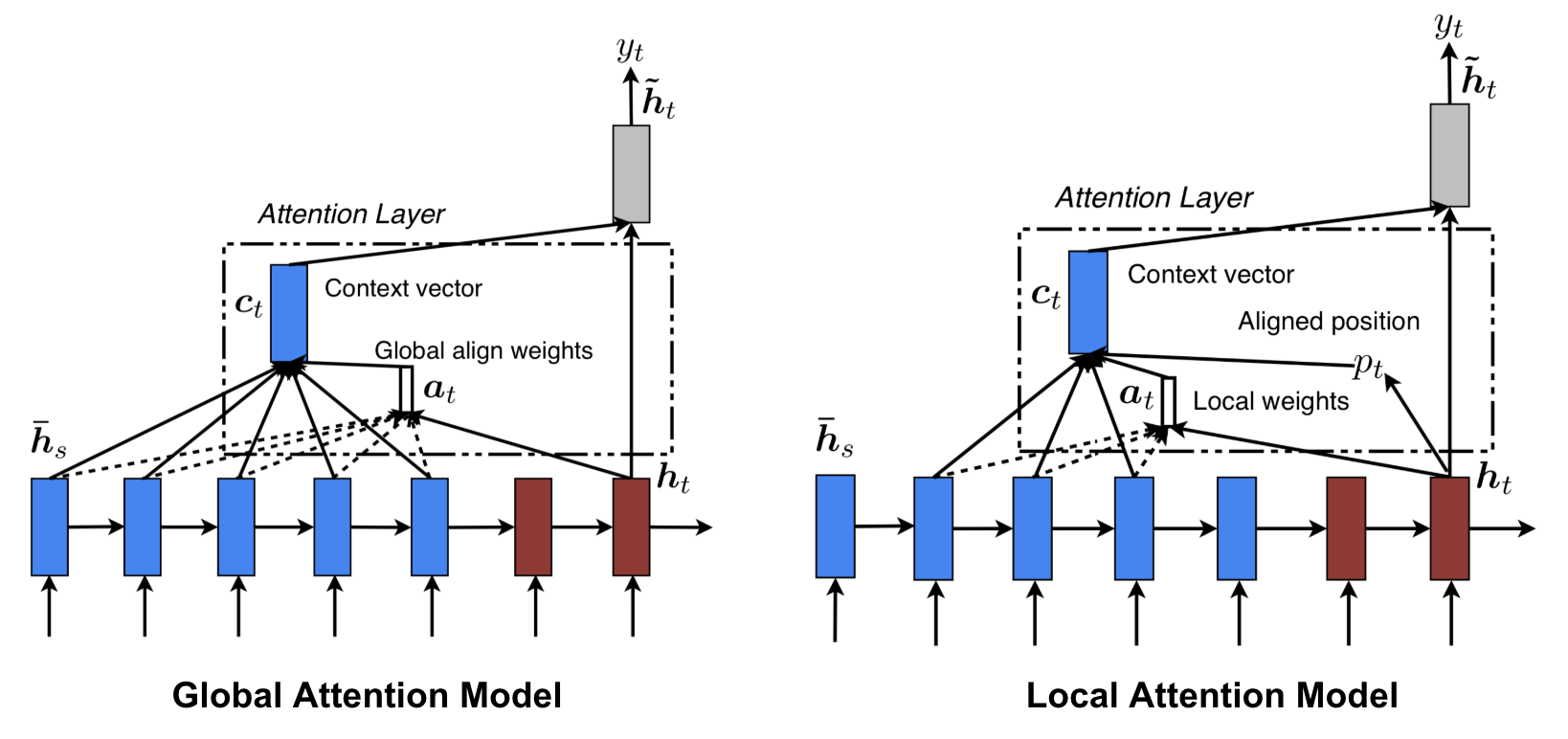
Abb. 8. Globale vs. lokale Aufmerksamkeit (Bildquelle: Abb. 2 & 3 in Luong, et al., 2015)
Neuronale Turingmaschinen
Alan Turing schlug 1936 ein minimalistisches Modell der Berechnung vor. Es besteht aus einem unendlich langen Band und einem Kopf, der mit dem Band interagiert. Auf dem Band befinden sich unzählige Zellen, die jeweils mit einem Symbol gefüllt sind: 0, 1 oder leer (“ „). Der Operationskopf kann Symbole lesen, bearbeiten und sich auf dem Band nach links/rechts bewegen. Theoretisch kann eine Turing-Maschine jeden Computeralgorithmus simulieren, unabhängig davon, wie komplex oder teuer das Verfahren sein mag. Der unendliche Speicher gibt einer Turing-Maschine den Vorteil, mathematisch unbegrenzt zu sein. Allerdings ist ein unendlicher Speicher in realen modernen Computern nicht realisierbar, so dass wir die Turingmaschine nur als mathematisches Modell der Berechnung betrachten.

Abb. 9. So sieht eine Turing-Maschine aus: ein Band + ein Kopf, der das Band verarbeitet. (Bildquelle: http://aturingmachine.com/)
Die Neuronale Turingmaschine (NTM, Graves, Wayne & Danihelka, 2014) ist eine Modellarchitektur zur Kopplung eines neuronalen Netzes mit einem externen Speicher. Der Speicher ahmt das Band der Turing-Maschine nach und das neuronale Netz steuert die Operationsköpfe, um vom Band zu lesen oder darauf zu schreiben. Allerdings ist der Speicher in der NTM endlich, so dass sie wahrscheinlich eher einer „Neuronalen von Neumann-Maschine“ ähnelt.
Die NTM enthält zwei Hauptkomponenten, ein neuronales Netzwerk mit Controller und eine Speicherbank. Controller: ist verantwortlich für die Ausführung von Operationen auf dem Speicher. Es kann jede Art von neuronalem Netz sein, feed-forward oder rekurrent.Speicher: speichert verarbeitete Informationen. Er ist eine Matrix der Größe \(N \mal M\), die N Vektorzeilen enthält und jeweils \(M\) Dimensionen hat.
In einer Aktualisierungsiteration verarbeitet der Controller die Eingabe und interagiert entsprechend mit der Speicherbank, um die Ausgabe zu erzeugen. Die Interaktion wird durch eine Reihe von parallelen Lese- und Schreibköpfen durchgeführt. Sowohl die Lese- als auch die Schreiboperationen sind „unscharf“, da alle Speicheradressen sanft behandelt werden.
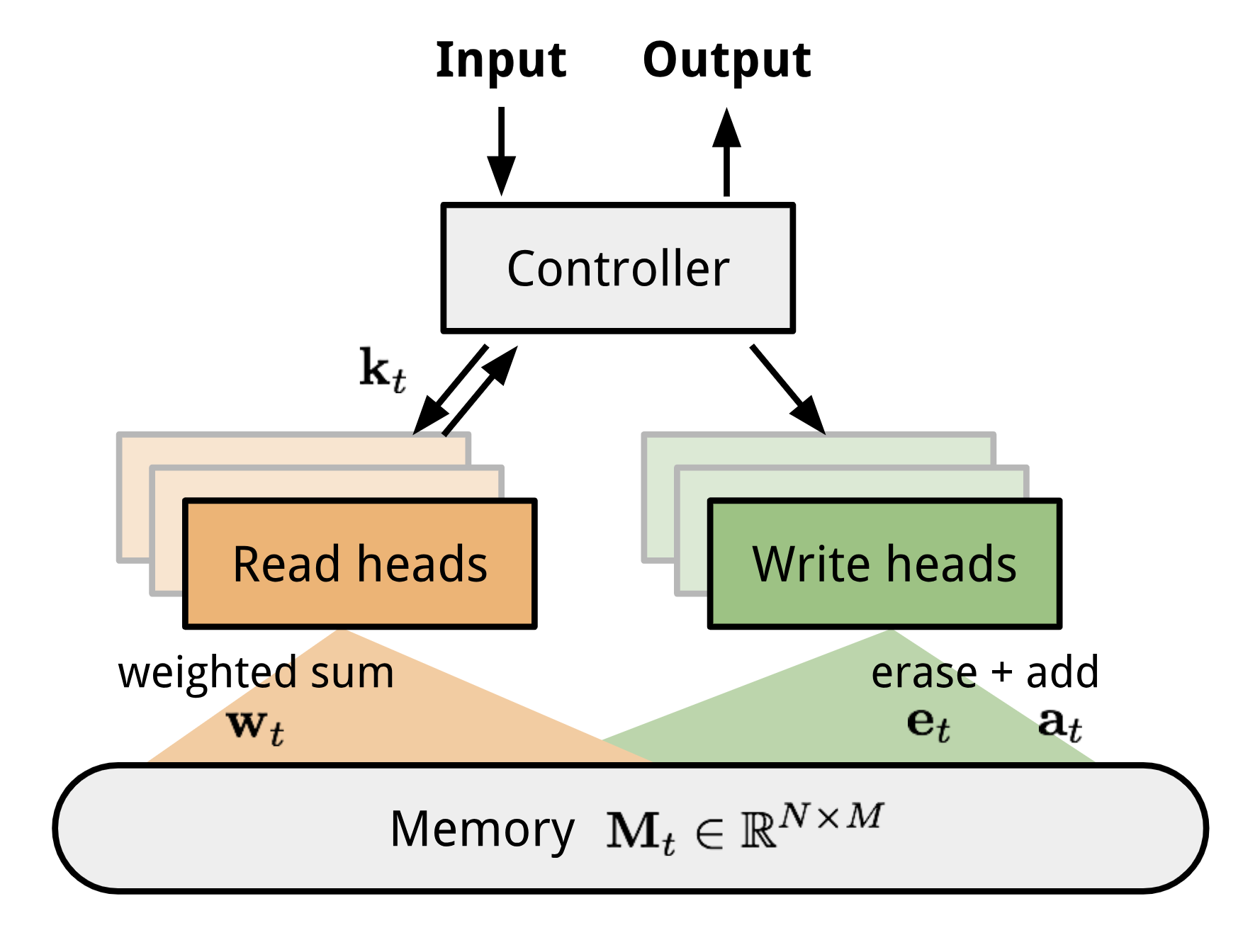
Abbildung 10. Neuronale Turingmaschinenarchitektur.
Lesen und Schreiben
\
wobei \(w_t(i)\) das \(i\)-te Element in \(\mathbf{w}_t\) und \(\mathbf{M}_t(i)\) der \(i\)-te Zeilenvektor im Speicher ist.
\ &\scriptstyle{\text{; erase}}\\mathbf{M}_t(i) &= \tilde{\mathbf{M}}_t(i) + w_t(i) \mathbf{a}_t &\scriptstyle{\text{; add}}end{aligned}\]
Aufmerksamkeitsmechanismen
In der Neural Turing Machine hängt es von den Adressierungsmechanismen ab, wie die Aufmerksamkeitsverteilung \(\mathbf{w}_t\) erzeugt wird: NTM verwendet eine Mischung aus inhaltsbasierter und ortsbezogener Adressierung.
Inhaltsbasierte Adressierung
Die inhaltsbasierte Adressierung erzeugt Aufmerksamkeitsvektoren auf der Grundlage der Ähnlichkeit zwischen dem Schlüsselvektor \(\mathbf{k}_t\), den der Controller aus den Eingabe- und Speicherzeilen extrahiert. Die inhaltsbasierten Aufmerksamkeitswerte werden als Cosinus-Ähnlichkeit berechnet und dann mit Softmax normalisiert. Darüber hinaus fügt NTM einen Stärkemultiplikator \(\beta_t\) hinzu, um den Fokus der Verteilung zu verstärken oder abzuschwächen.
\)= \frac{\exp(\beta_t \frac{\mathbf{k}_t \cdot \mathbf{M}_t(i)}{\|\mathbf{k}_t\| \cdot \|\mathbf{M}_t(i)\|})}{\sum_{j=1}^N \exp(\beta_t \frac{\mathbf{k}_t \cdot \mathbf{M}_t(j)}{\|\mathbf{k}_t\| \cdot \|\mathbf{M}_t(j)\|})}\]
Interpolation
Dann wird ein Interpolationsgatterskalar \(g_t\) verwendet, um den neu generierten inhaltsbasierten Aufmerksamkeitsvektor mit den Aufmerksamkeitsgewichten des letzten Zeitschritts:
\
Ortsbezogene Adressierung
Die ortsbezogene Adressierung summiert die Werte an verschiedenen Positionen im Aufmerksamkeitsvektor, gewichtet durch eine Gewichtungsverteilung über zulässige ganzzahlige Verschiebungen. Sie ist äquivalent zu einer 1-d-Faltung mit einem Kernel \(\mathbf{s}_t(.)\), einer Funktion des Positionsoffsets. Es gibt mehrere Möglichkeiten, diese Verteilung zu definieren. Siehe Abb. 11. als Anregung.
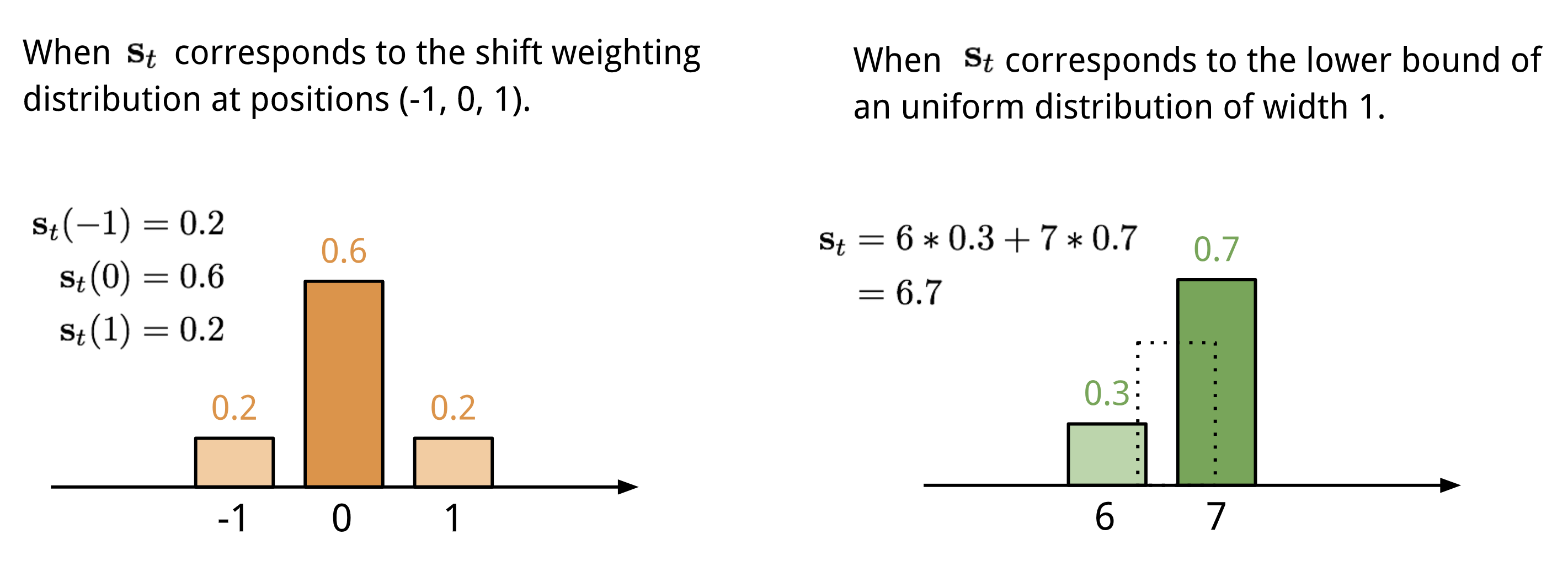
Abb. 11. Zwei Möglichkeiten, die Verschiebungsgewichtsverteilung \(\mathbf{s}_t\) darzustellen.
Schließlich wird die Aufmerksamkeitsverteilung durch einen Schärfungsskalar \(\gamma_t \geq 1\) verstärkt.
\
Der vollständige Prozess der Erzeugung des Aufmerksamkeitsvektors \(\mathbf{w}_t\) zum Zeitschritt t ist in Abb. 12 dargestellt. Alle vom Controller erzeugten Parameter sind für jeden Kopf eindeutig. Wenn es mehrere Lese- und Schreibköpfe parallel gibt, würde der Controller mehrere Sätze ausgeben.
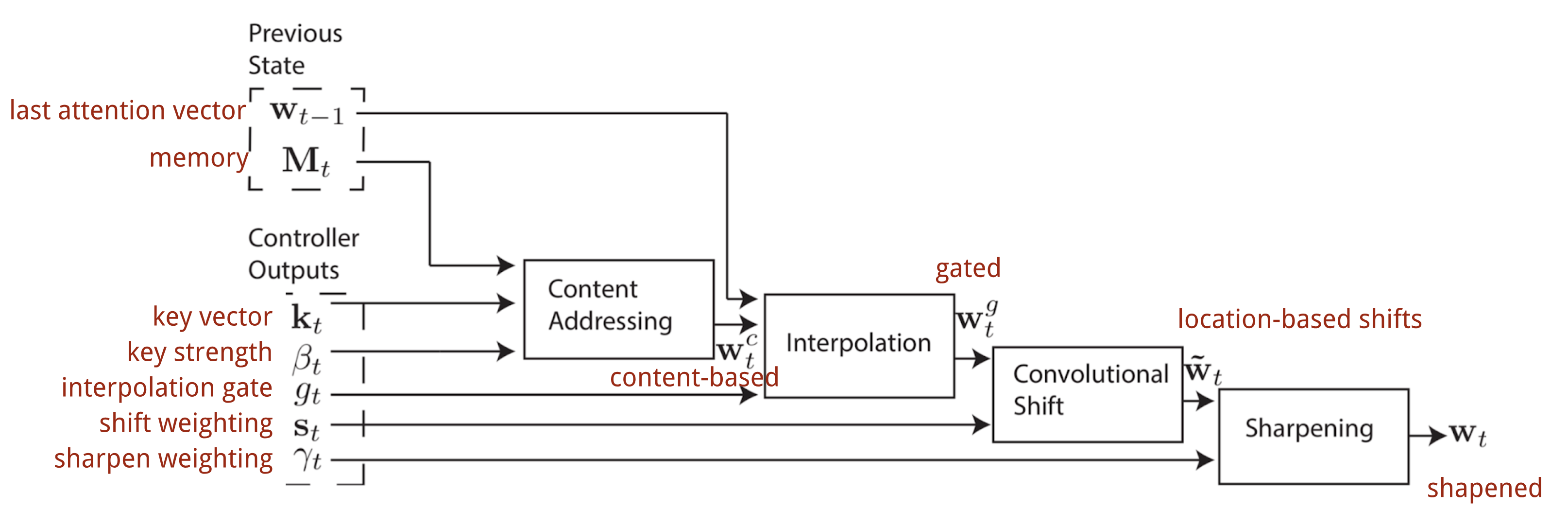
Abb. 12. Flussdiagramm der Adressierungsmechanismen in der Neuronalen Turingmaschine. (Bildquelle: Graves, Wayne & Danihelka, 2014)
Zeigernetzwerk
Bei Problemen wie Sortierung oder Handlungsreisender sind sowohl Eingabe als auch Ausgabe sequentielle Daten. Leider lassen sie sich mit klassischen seq-2-seq- oder NMT-Modellen nicht leicht lösen, da die diskreten Kategorien der Ausgangselemente nicht im Voraus festgelegt werden, sondern von der variablen Eingabegröße abhängen. Das Pointer-Netz (Ptr-Netz; Vinyals, et al. 2015) wird vorgeschlagen, um diese Art von Problemen zu lösen: Wenn die Ausgangselemente den Positionen in einer Eingabesequenz entsprechen. Anstatt Aufmerksamkeit zu verwenden, um versteckte Einheiten eines Encoders zu einem Kontextvektor zu verschmelzen (siehe Abb. 8), wendet das Pointer-Netz Aufmerksamkeit auf die Eingabeelemente an, um bei jedem Decoderschritt eines als Ausgabe auszuwählen.
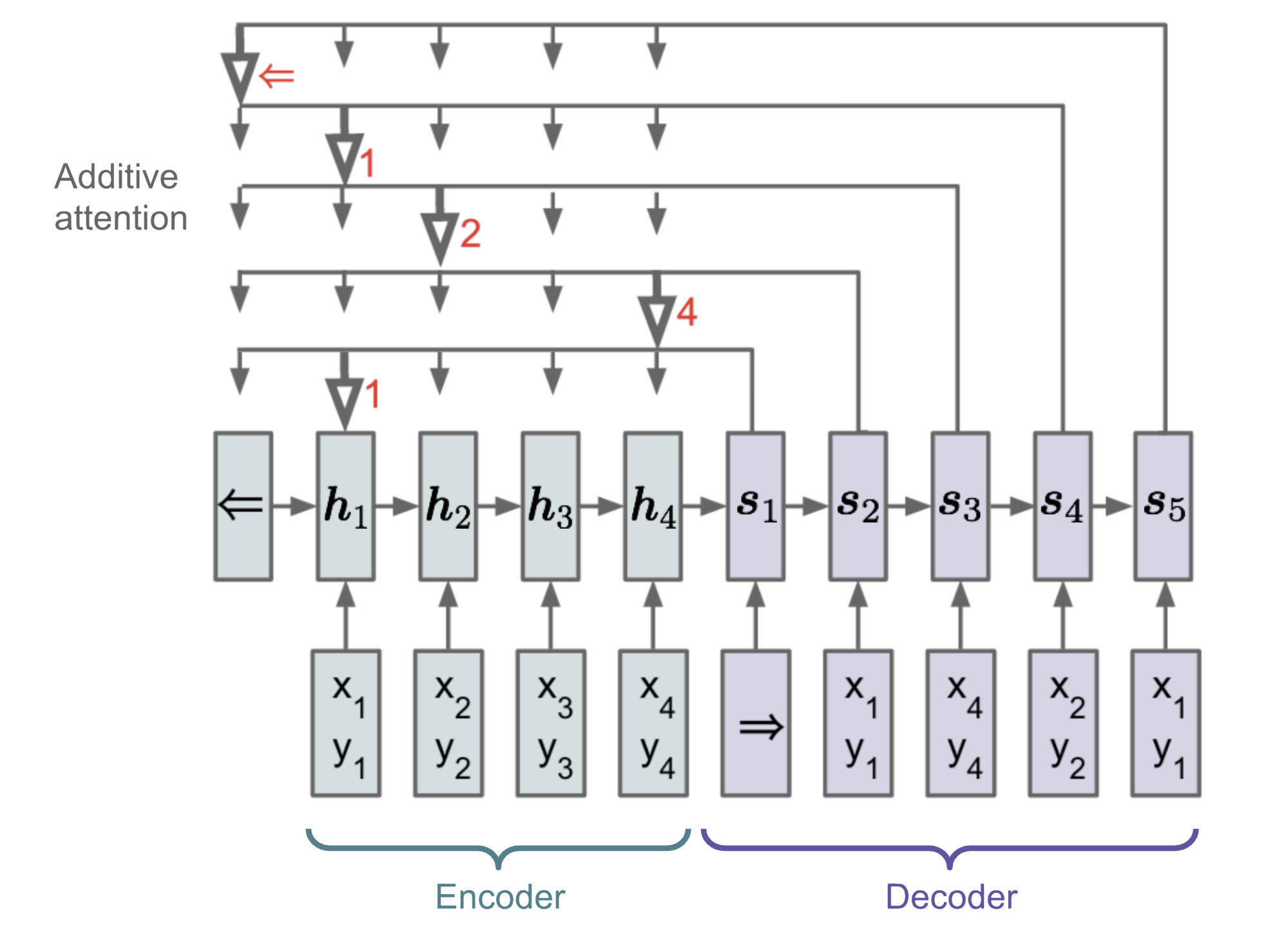
Abb. 13. Die Architektur eines Zeigernetzmodells. (Bildquelle: Vinyals, et al. 2015)
\))\end{aligned}\]
Der Aufmerksamkeitsmechanismus ist vereinfacht, da Ptr-Net die Encoder-Zustände nicht mit Aufmerksamkeitsgewichten in die Ausgabe einblendet. Auf diese Weise reagiert die Ausgabe nur auf die Positionen, nicht aber auf den Eingabeinhalt.
Transformer
„Attention is All you Need“ (Vaswani, et al., 2017) ist zweifellos eine der einflussreichsten und interessantesten Arbeiten des Jahres 2017. Darin werden zahlreiche Verbesserungen der weichen Aufmerksamkeit vorgestellt, die eine seq2seq-Modellierung ohne rekurrente Netzeinheiten ermöglichen. Das vorgeschlagene „Transformator“-Modell baut vollständig auf den Mechanismen der Selbstaufmerksamkeit auf, ohne eine sequenzorientierte rekurrente Architektur zu verwenden.
Das Geheimrezept steckt in seiner Modellarchitektur.
Schlüssel, Wert und Abfrage
Der Transformator verwendet die skalierte Punktprodukt-Attention: Die Ausgabe ist eine gewichtete Summe der Werte, wobei das jedem Wert zugewiesene Gewicht durch das Punktprodukt der Abfrage mit allen Schlüsseln bestimmt wird:
\
Multi-Head Self-Attention
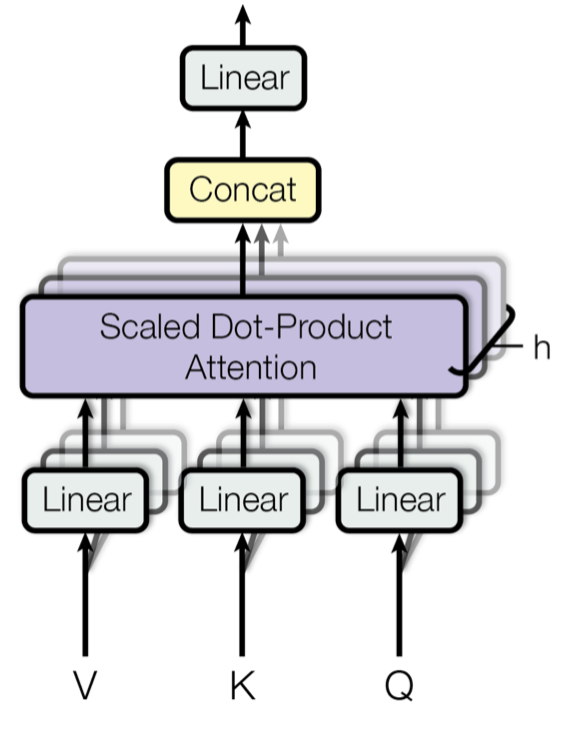
Abb. 14. Mehrköpfiger skalierter Punkt-Produkt-Aufmerksamkeitsmechanismus. (Bildquelle: Abb. 2 in Vaswani, et al., 2017)
Anstatt die Aufmerksamkeit nur einmal zu berechnen, durchläuft der Multi-Head-Mechanismus die skalierte Punkt-Produkt-Aufmerksamkeit mehrfach parallel. Die unabhängigen Aufmerksamkeitsausgaben werden einfach verkettet und linear in die erwarteten Dimensionen transformiert. Ich nehme an, die Motivation liegt darin, dass Ensembling immer hilft 😉 In dem Papier heißt es: „Aufmerksamkeit mit mehreren Köpfen ermöglicht es dem Modell, Informationen aus verschiedenen Repräsentationsunterräumen an verschiedenen Positionen gemeinsam zu beachten. Bei einem einzelnen Aufmerksamkeitskopf wird dies durch die Mittelwertbildung behindert.“
\mathbf{W}^O \\\text{wobei Kopf}_i &= \text{Aufmerksamkeit}(\mathbf{Q}\mathbf{W}^Q_i, \mathbf{K}\mathbf{W}^K_i, \mathbf{V}\mathbf{W}^V_i)\end{aligned}\]
wobei \(\mathbf{W}^Q_i\), \(\mathbf{W}^K_i\), \(\mathbf{W}^V_i\) und \(\mathbf{W}^O\) zu lernende Parametermatrizen sind.
Encoder
![]()
Abbildung 15. Der Kodierer des Transformators. (Bildquelle: Vaswani, et al, 2017)
Der Encoder erzeugt eine aufmerksamkeitsbasierte Repräsentation mit der Fähigkeit, eine bestimmte Information aus einem potenziell unendlich großen Kontext zu lokalisieren.
- Ein Stapel von N=6 identischen Schichten.
- Jede Schicht hat eine mehrköpfige Selbstaufmerksamkeitsschicht und ein einfaches positionsweise voll verbundenes Feed-Forward-Netz.
- Jede Unterschicht nimmt eine Restverbindung und eine Schichtnormalisierung an.
Alle Unterschichten geben Daten derselben Dimension \(d_\text{model} = 512\) aus.
Decoder
![]()
Abb. 16. Der Decoder des Transformators. (Bildquelle: Vaswani, et al, 2017)
Der Decoder ist in der Lage, die kodierte Repräsentation abzurufen.
- Ein Stapel von N = 6 identischen Schichten
- Jede Schicht hat zwei Unterschichten von Mehrkopf-Aufmerksamkeitsmechanismen und eine Unterschicht von vollverknüpften Vorwärtsnetzwerken.
- Ähnlich wie beim Kodierer verwendet jede Unterschicht eine Restverbindung und eine Schichtnormalisierung.
- Die erste Unterschicht mit mehrköpfigen Aufmerksamkeitsmechanismen wird modifiziert, um zu verhindern, dass Positionen auf nachfolgende Positionen achten, da wir nicht in die Zukunft der Zielsequenz schauen wollen, wenn wir die aktuelle Position vorhersagen.
Vollständige Architektur
Schließlich hier die vollständige Ansicht der Architektur des Transformators:
- Beide, die Quell- und die Zielsequenz, durchlaufen zunächst Einbettungsschichten, um Daten der gleichen Dimension zu erzeugen \(d_\text{model} =512\).
- Um die Positionsinformationen zu erhalten, wird eine auf Sinuswellen basierende Positionskodierung angewendet und mit der Einbettungsausgabe summiert.
- Eine Softmax- und eine lineare Schicht werden zur endgültigen Decoderausgabe hinzugefügt.
![]()
Abbildung 17. Die vollständige Modellarchitektur des Transformators. (Bildquelle: Abb. 1 & 2 in Vaswani, et al., 2017.)
Versuchen Sie, das Transformatormodell zu implementieren, ist eine interessante Erfahrung, hier ist meine: lilianweng/transformer-tensorflow. Lesen Sie die Kommentare im Code, wenn Sie daran interessiert sind.
SNAIL
Der Transformator hat keine rekurrente oder konvolutionäre Struktur, selbst mit der Positionskodierung, die dem Einbettungsvektor hinzugefügt wird, wird die sequentielle Reihenfolge nur schwach berücksichtigt. Für Probleme, die empfindlich auf die Positionsabhängigkeit reagieren, wie z. B. das Verstärkungslernen, kann dies ein großes Problem darstellen.
Der Simple Neural Attention Meta-Learner (SNAIL) (Mishra et al., 2017) wurde entwickelt, um das Problem der Positionierung im Transformatormodell teilweise zu lösen, indem der Selbstaufmerksamkeitsmechanismus im Transformator mit zeitlichen Faltungen kombiniert wurde. Es hat sich gezeigt, dass es sowohl bei Aufgaben des überwachten Lernens als auch beim Reinforcement Learning gut ist.
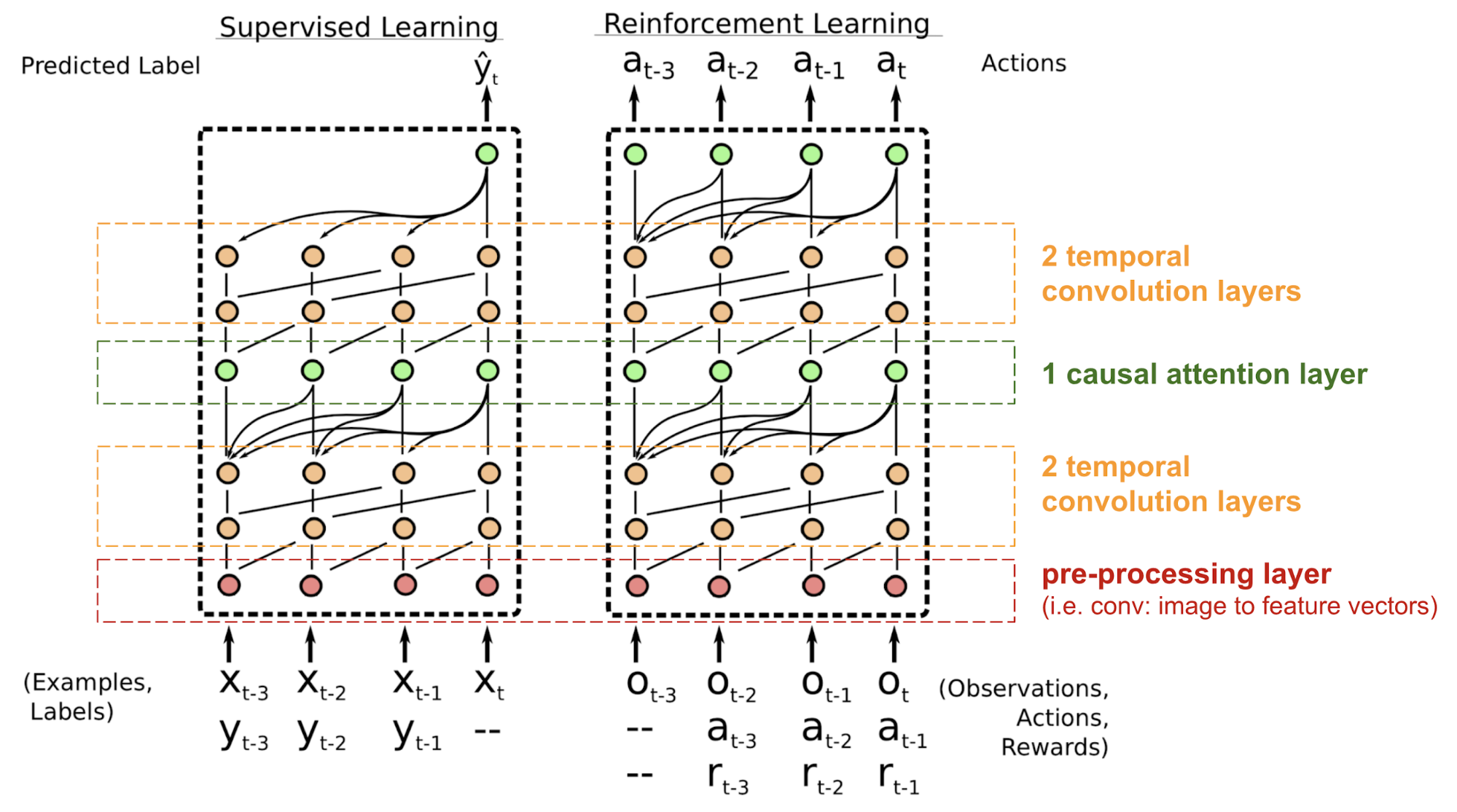
Abb. 18. SNAIL-Modellarchitektur (Bildquelle: Mishra et al., 2017)
SNAIL wurde im Bereich des Meta-Learnings geboren, was ein weiteres großes Thema ist, das einen eigenen Beitrag wert ist. Aber in einfachen Worten: Es wird erwartet, dass das Meta-Lernmodell auf neuartige, ungesehene Aufgaben in ähnlicher Verteilung verallgemeinerbar ist. Lesen Sie diese schöne Einführung, wenn Sie daran interessiert sind.
Self-Attention GAN
Self-Attention GAN (SAGAN; Zhang et al., 2018) fügt dem GAN Selbstaufmerksamkeitsschichten hinzu, um sowohl den Generator als auch den Diskriminator in die Lage zu versetzen, Beziehungen zwischen räumlichen Regionen besser zu modellieren.
Das klassische DCGAN (Deep Convolutional GAN) stellt sowohl den Diskriminator als auch den Generator als mehrschichtige Faltungsnetzwerke dar. Allerdings wird die Darstellungskapazität des Netzes durch die Filtergröße eingeschränkt, da das Merkmal eines Pixels auf eine kleine lokale Region beschränkt ist. Um weit voneinander entfernte Regionen zu verbinden, müssen die Merkmale durch Schichten von Faltungsoperationen verdünnt werden, und die Abhängigkeiten sind nicht garantiert.
Da die (weiche) Selbstbeobachtung im Kontext der Bildverarbeitung so konzipiert ist, dass sie explizit die Beziehung zwischen einem Pixel und allen anderen Positionen lernt, selbst wenn diese weit voneinander entfernt sind, kann sie leicht globale Abhängigkeiten erfassen. Daher wird erwartet, dass ein GAN, das mit Selbstaufmerksamkeit ausgestattet ist, Details besser handhaben kann, hurra!
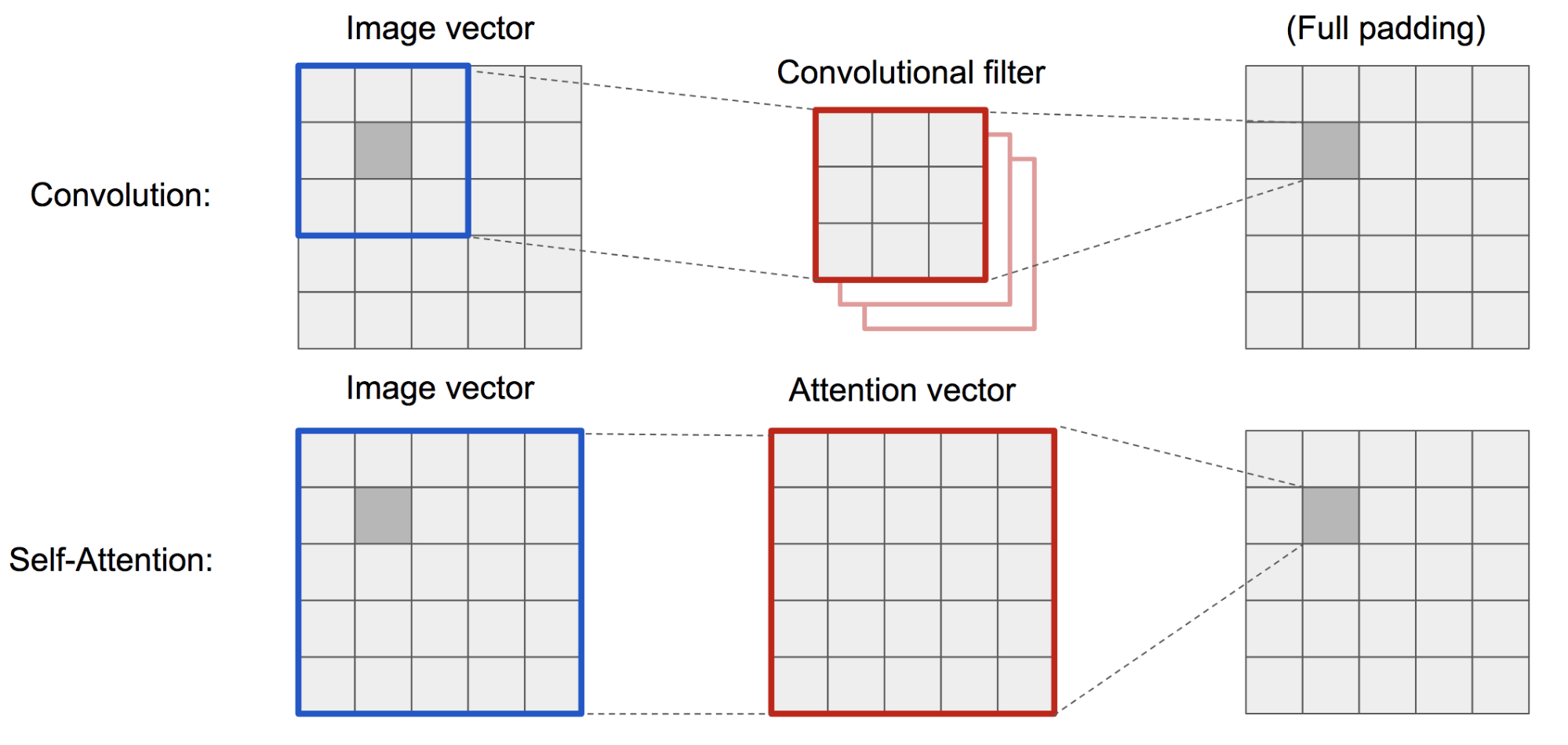
Abb. 19. Die Faltungsoperation und die Selbstaufmerksamkeit haben Zugang zu Regionen sehr unterschiedlicher Größe.
Das SAGAN verwendet das nicht-lokale neuronale Netz zur Anwendung der Aufmerksamkeitsberechnung. Die Faltungsbild-Merkmalskarten \(\mathbf{x}\) werden in drei Kopien verzweigt, die den Konzepten von Schlüssel, Wert und Abfrage im Transformator entsprechen:
- Schlüssel: \(f(\mathbf{x}) = \mathbf{W}_f \mathbf{x}\)
- Query: \(g(\mathbf{x}) = \mathbf{W}_g \mathbf{x}\)
- Wert: \(h(\mathbf{x}) = \mathbf{W}_h \mathbf{x}\)
Dann wenden wir die Punkt-Produkt-Attention an, um die Selbstaufmerksamkeits-Merkmalskarten auszugeben:
\
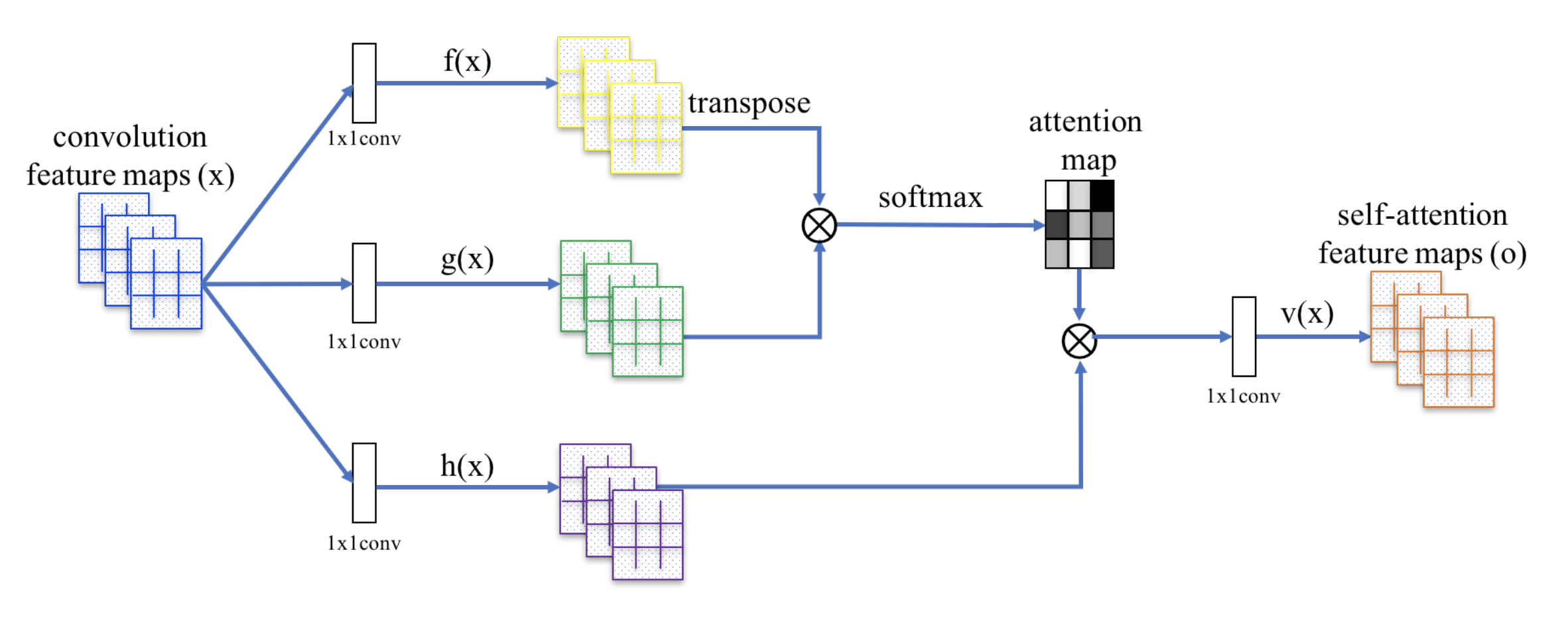
Abb. 20. Der Mechanismus der Selbstaufmerksamkeit in SAGAN. (Bildquelle: Abb. 2 in Zhang et al, 2018)
Darüber hinaus wird die Ausgabe der Aufmerksamkeitsschicht mit einem Skalierungsparameter multipliziert und wieder zur ursprünglichen Eingabe-Merkmalskarte hinzugefügt:
\
Während der Skalierungsparameter \(\gamma\) während des Trainings schrittweise von 0 erhöht wird, ist das Netzwerk so konfiguriert, dass es sich zunächst auf die Hinweise in den lokalen Regionen verlässt und dann schrittweise lernt, den weiter entfernten Regionen mehr Gewicht zuzuweisen.

Abb. 21. 128×128 Beispielbilder, die von SAGAN für verschiedene Klassen erzeugt wurden. (Bildquelle: Partial Fig. 6 in Zhang et al., 2018)
Zitiert als:
Wenn Sie Fehler und Irrtümer in diesem Beitrag bemerken, zögern Sie nicht, mich zu kontaktieren, und ich würde mich sehr freuen, sie sofort zu korrigieren!
See you in the next post 😀
„Attention and Memory in Deep Learning and NLP.“ – Jan 3, 2016 by Denny Britz
„Neural Machine Translation (seq2seq) Tutorial“
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. „Neuronale maschinelle Übersetzung durch gemeinsames Lernen für Alignment und Übersetzung“. ICLR 2015.
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. „Zeigen, bedienen und erzählen: Neural image caption generation with visual attention.“ ICML, 2015.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. „Sequence to sequence learning with neural networks.“ NIPS 2014.
Thang Luong, Hieu Pham, Christopher D. Manning. „Effective Approaches to Attention-based Neural Machine Translation.“ EMNLP 2015.
Denny Britz, Anna Goldie, Thang Luong, and Quoc Le. „Massive exploration of neural machine translation architectures.“ ACL 2017.
Ashish Vaswani, et al. „Attention is all you need.“ NIPS 2017.
Jianpeng Cheng, Li Dong, and Mirella Lapata. „Long short-term memory-networks for machine reading.“ EMNLP 2016.
Xiaolong Wang, et al. „Non-local Neural Networks.“ CVPR 2018
Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, and Pieter Abbeel. „A simple neural attentive meta-learner.“ ICLR 2018.
„WaveNet: A Generative Model for Raw Audio“ – Sep 8, 2016 by DeepMind.
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. „Pointer networks.“ NIPS 2015.
Alex Graves, Greg Wayne, and Ivo Danihelka. „Neural turing machines.“ arXiv preprint arXiv:1410.5401 (2014).