¿Atención? Atención.
La atención ha sido un concepto bastante popular y una herramienta útil en la comunidad del aprendizaje profundo en los últimos años. En este post, vamos a ver cómo se inventó la atención, y varios mecanismos y modelos de atención, como el transformador y SNAIL.
La atención está, en cierta medida, motivada por cómo prestamos atención visual a diferentes regiones de una imagen o correlacionamos palabras en una frase. Tomemos como ejemplo la imagen de un Shiba Inu en la Fig. 1.

Fig. 1. Un Shiba Inu en un traje de hombre. El crédito de la foto original es de Instagram @mensweardog.
La atención visual humana nos permite centrarnos en una determinada región con «alta resolución» (es decir, mirar la oreja puntiaguda en el recuadro amarillo) mientras percibimos la imagen circundante en «baja resolución» (es decir, ¿ahora qué tal el fondo nevado y el traje?), y luego ajustar el punto focal o hacer la inferencia en consecuencia. Dado un pequeño fragmento de una imagen, los píxeles del resto proporcionan pistas sobre lo que debería aparecer allí. Esperamos ver una oreja puntiaguda en el recuadro amarillo porque hemos visto la nariz de un perro, otra oreja puntiaguda a la derecha y los misteriosos ojos de Shiba (cosas de los recuadros rojos). Sin embargo, el jersey y la manta del fondo no serían tan útiles como esos rasgos caninos.
De forma similar, podemos explicar la relación entre palabras en una frase o contexto cercano. Cuando vemos «comer», esperamos encontrarnos con una palabra de comida muy pronto. El término color describe la comida, pero probablemente no tanto con «comer» directamente.
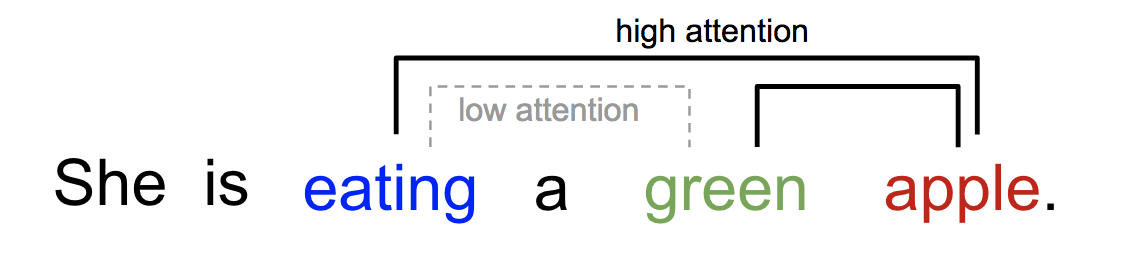
Fig. 2. Una palabra «atiende» a otras palabras en la misma frase de forma diferente.
En pocas palabras, la atención en el aprendizaje profundo puede interpretarse a grandes rasgos como un vector de pesos de importancia: para predecir o inferir un elemento, como un píxel en una imagen o una palabra en una frase, estimamos mediante el vector de atención la intensidad con la que está correlacionado (o «atiende», como habrás leído en muchos artículos) con otros elementos y tomamos la suma de sus valores ponderados por el vector de atención como la aproximación del objetivo.
- ¿Qué tiene de malo el modelo seq2seq?
- Nacido para la traducción
- Definición
- Una familia de mecanismos de atención
- Resumen
- Autoatención
- Atención suave frente a atención dura
- Atención global vs local
- Máquinas neuronales de Turing
- Lectura y escritura
- Mecanismos de atención
- Red de punteros
- Transformador
- Clave, valor y consulta
- Autoatención multicabezal
- Codificador
- Decodificador
- Arquitectura completa
- SNAIL
- Self-Attention GAN
¿Qué tiene de malo el modelo seq2seq?
El modelo seq2seq nació en el campo del modelado del lenguaje (Sutskever, et al. 2014). A grandes rasgos, su objetivo es transformar una secuencia de entrada (origen) a una nueva (destino) y ambas secuencias pueden ser de longitudes arbitrarias. Algunos ejemplos de tareas de transformación son la traducción automática entre varios idiomas, ya sea en texto o en audio, la generación de diálogos de pregunta-respuesta o incluso el análisis sintáctico de oraciones en árboles gramaticales.
El modelo seq2seq tiene normalmente una arquitectura de codificador-decodificador, compuesta por:
- Un codificador procesa la secuencia de entrada y comprime la información en un vector de contexto (también conocido como incrustación de oraciones o vector «pensamiento») de una longitud fija. Se espera que esta representación sea un buen resumen del significado de toda la secuencia de origen.
- Un decodificador se inicializa con el vector de contexto para emitir la salida transformada. Los primeros trabajos sólo utilizaban el último estado de la red del codificador como estado inicial del decodificador.
Tanto el codificador como el decodificador son redes neuronales recurrentes, es decir, que utilizan unidades LSTM o GRU.
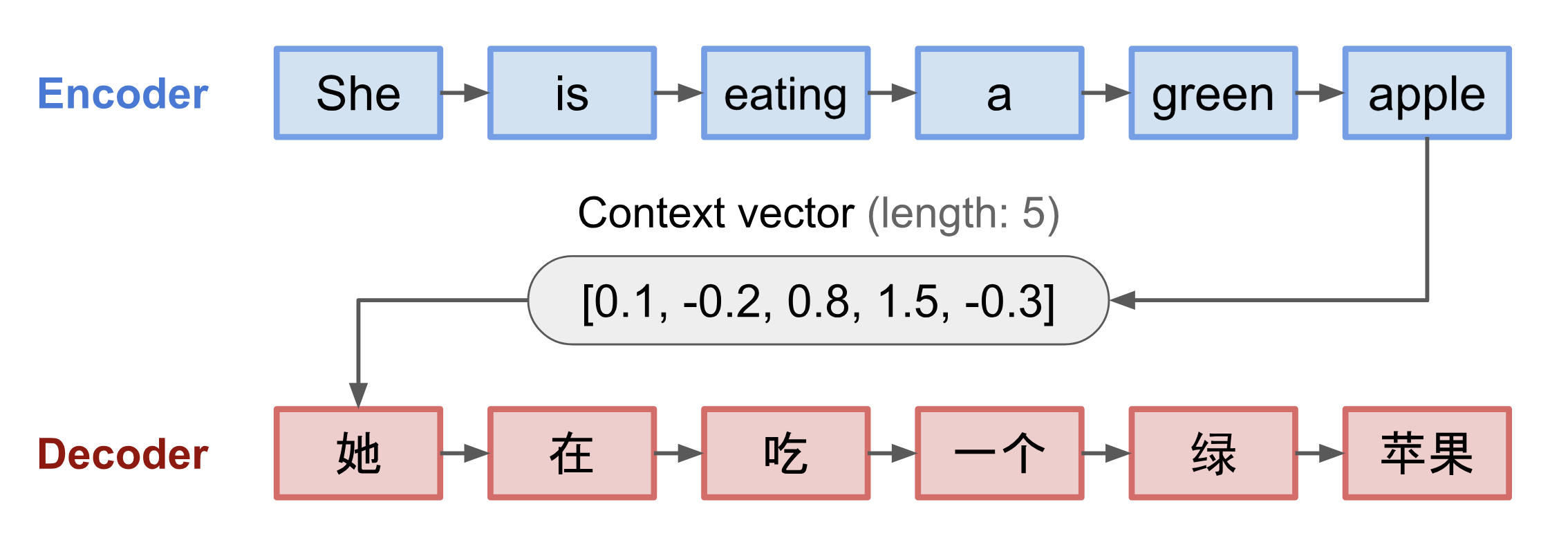
Fig. 3. El modelo codificador-decodificador, traduciendo la frase «ella está comiendo una manzana verde» al chino. La visualización tanto del codificador como del decodificador se desenrolla en el tiempo.
Una desventaja crítica y aparente de este diseño de vector de contexto de longitud fija es la incapacidad de recordar frases largas. A menudo ha olvidado la primera parte una vez que ha completado el procesamiento de toda la entrada. El mecanismo de atención nació (Bahdanau et al., 2015) para resolver este problema.
Nacido para la traducción
El mecanismo de atención nació para ayudar a memorizar frases largas de origen en la traducción automática neural (NMT). En lugar de construir un único vector de contexto a partir del último estado oculto del codificador, la salsa secreta inventada por la atención consiste en crear atajos entre el vector de contexto y toda la entrada de la fuente. Los pesos de estas conexiones de atajo son personalizables para cada elemento de salida.
Mientras que el vector de contexto tiene acceso a toda la secuencia de entrada, no necesitamos preocuparnos por el olvido. La alineación entre la fuente y el objetivo es aprendida y controlada por el vector de contexto. Esencialmente, el vector de contexto consume tres piezas de información:
- estados ocultos del codificador;
- estados ocultos del decodificador;
- alineación entre la fuente y el objetivo.
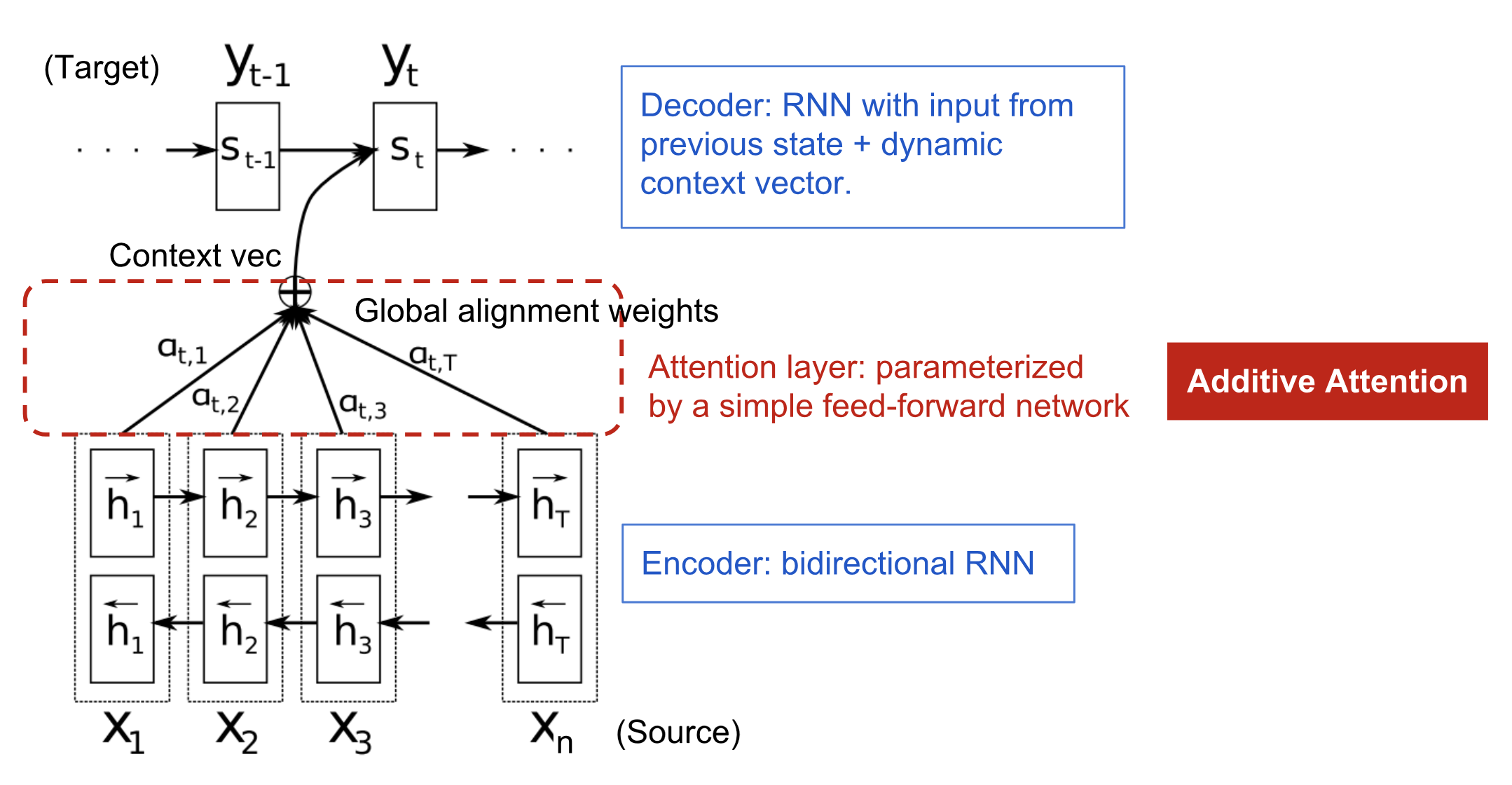
Fig. 4. El modelo de codificador-decodificador con mecanismo de atención aditiva en Bahdanau et al., 2015.
Definición
\\N de la atención de la fuente. &= \end{aligned}]
(Las variables en negrita indican que son vectores; lo mismo para todo lo demás en este post.)
El codificador es una RN bidireccional (u otra configuración de red recurrente de su elección) con un estado oculto hacia adelante \(\overrightarrow{boldsymbol{h}_i) y otro hacia atrás \(\overleftarrow{boldsymbol{h}_i). Una simple concatenación de dos representa el estado del codificador. La motivación es incluir tanto las palabras anteriores como las siguientes en la anotación de una palabra.
^\\top, i=1,\dots,n\]\\t]
donde tanto \(\mathbf{v}_a) como \(\mathbf{W}_a) son matrices de pesos que se aprenderán en el modelo de alineación.
La matriz de puntuaciones de alineación es un buen subproducto para mostrar explícitamente la correlación entre las palabras de origen y las de destino.

Fig. 5. Matriz de alineación de «L’accord sur l’Espace économique européen a été signé en août 1992» (francés) y su traducción al inglés «The agreement on the European Economic Area was signed in August 1992». (Fuente de la imagen: Fig 3 en Bahdanau et al., 2015)
Consulta este bonito tutorial del equipo de Tensorflow para obtener más instrucciones de implementación.
Una familia de mecanismos de atención
¡Con la ayuda de la atención, las dependencias entre las secuencias de origen y destino ya no están restringidas por la distancia intermedia! Dada la gran mejora de la atención en la traducción automática, pronto se extendió al campo de la visión por ordenador (Xu et al. 2015) y la gente comenzó a explorar varias otras formas de mecanismos de atención (Luong, et al., 2015; Britz et al., 2017; Vaswani, et al., 2017).
Resumen
A continuación se muestra una tabla resumen de varios mecanismos de atención populares y las correspondientes funciones de puntuación de alineación:
Aquí hay un resumen de categorías más amplias de mecanismos de atención:
| Nombre | Definición | Citación |
|---|---|---|
| Autoatención(&) | Relacionar diferentes posiciones de la misma secuencia de entrada. Teóricamente la autoatención puede adoptar cualquier función de puntuación anterior, pero basta con sustituir la secuencia objetivo por la misma secuencia de entrada. | Cheng2016 |
| Global/Soft | Atendiendo a todo el espacio de estados de entrada. | Xu2015 |
| Local/Duro | Atendiendo a la parte del espacio de estado de entrada; es decir, un parche de la imagen de entrada. | Xu2015; Luong2015 |
(&) También, referido como «intra-atención» en Cheng et al, 2016 y algunos otros trabajos.
Autoatención
La autoatención, también conocida como intraatención, es un mecanismo de atención que relaciona diferentes posiciones de una misma secuencia para computar una representación de la misma. Se ha demostrado que es muy útil en la lectura automática, el resumen abstracto o la generación de descripciones de imágenes.
El artículo sobre la red de memoria a corto plazo utilizó la autoatención para realizar la lectura automática. En el ejemplo siguiente, el mecanismo de autoatención permite aprender la correlación entre las palabras actuales y la parte anterior de la frase.

Fig. 6. La palabra actual está en rojo y el tamaño de la sombra azul indica el nivel de activación. (Fuente de la imagen: Cheng et al., 2016)
Atención suave frente a atención dura
En el trabajo Mostrar, atender y contar, se aplica el mecanismo de atención a las imágenes para generar pies de foto. La imagen es codificada primero por una CNN para extraer características. A continuación, un decodificador LSTM consume las características de la convolución para producir palabras descriptivas una por una, donde los pesos se aprenden a través de la atención. La visualización de los pesos de atención demuestra claramente a qué regiones de la imagen presta atención el modelo para producir una determinada palabra.

Fig. 7. «Una mujer lanza un frisbee en un parque». (Fuente de la imagen: Fig. 6(b) en Xu et al. 2015)
Este trabajo propuso por primera vez la distinción entre atención «suave» vs. «dura», basada en si la atención tiene acceso a toda la imagen o solo a un parche:
- Atención suave: los pesos de alineación se aprenden y se colocan «suavemente» sobre todos los parches de la imagen de origen; esencialmente el mismo tipo de atención que en Bahdanau et al., 2015.
- Pro: el modelo es suave y diferenciable.
- Contra: costoso cuando la entrada de la fuente es grande.
- Atención dura: solo selecciona un parche de la imagen para atender a la vez.
- Pro: menos cálculos en el momento de la inferencia.
- Contra: el modelo es indiferenciable y requiere técnicas más complicadas como la reducción de la varianza o el aprendizaje por refuerzo para entrenar. (Luong, et al., 2015)
Atención global vs local
Luong, et al., 2015 propuso la atención «global» y «local». La atención global es similar a la atención blanda, mientras que la local es una interesante mezcla entre la dura y la blanda, una mejora sobre la atención dura para hacerla diferenciable: el modelo predice primero una única posición alineada para la palabra objetivo actual y una ventana centrada alrededor de la posición de origen se utiliza entonces para calcular un vector de contexto.
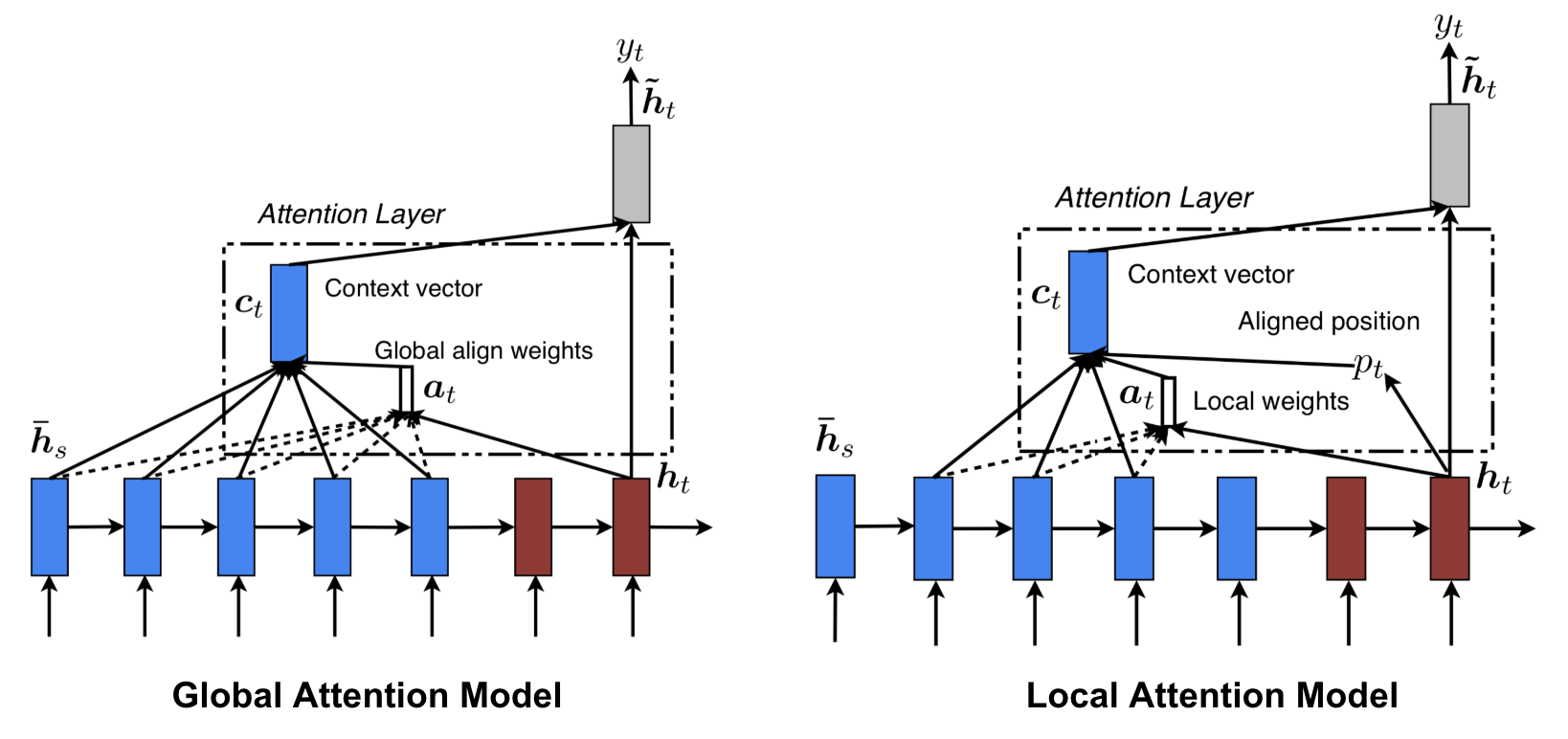
Fig. 8. Atención global vs local (Fuente de la imagen: Fig 2 & 3 en Luong, et al., 2015)
Máquinas neuronales de Turing
Alan Turing en 1936 propuso un modelo minimalista de computación. Se compone de una cinta infinitamente larga y una cabeza para interactuar con la cinta. La cinta tiene innumerables celdas, cada una de las cuales está llena de un símbolo: 0, 1 o en blanco (» «). El cabezal de operación puede leer símbolos, editar símbolos y moverse a la izquierda/derecha en la cinta. En teoría, una máquina de Turing puede simular cualquier algoritmo informático, independientemente de lo complejo o caro que sea el procedimiento. La memoria infinita da a una máquina de Turing la ventaja de ser matemáticamente ilimitada. Sin embargo, la memoria infinita no es factible en los ordenadores modernos reales y entonces sólo consideramos la máquina de Turing como un modelo matemático de computación.

Fig. 9. Aspecto de una máquina de Turing: una cinta + un cabezal que maneja la cinta. (Fuente de la imagen: http://aturingmachine.com/)
La máquina neuronal de Turing (NTM, Graves, Wayne & Danihelka, 2014) es una arquitectura modelo para acoplar una red neuronal con un almacenamiento de memoria externo. La memoria imita la cinta de la máquina de Turing y la red neuronal controla los cabezales de operación para leer o escribir en la cinta. Sin embargo, la memoria en la NTM es finita, por lo que probablemente se parezca más a una «Máquina Neural von Neumann».
La NTM contiene dos componentes principales, una red neuronal controladora y un banco de memoria. Controlador: es el encargado de ejecutar las operaciones en la memoria. Puede ser cualquier tipo de red neuronal, feed-forward o recurrente.Memoria: almacena la información procesada. Es una matriz de tamaño \(N \times M\), que contiene N filas de vectores y cada una tiene \(M\) dimensiones.
En una iteración de actualización, el controlador procesa la entrada e interactúa con el banco de memoria en consecuencia para generar la salida. La interacción es manejada por un conjunto de cabezas de lectura y escritura paralelas. Tanto las operaciones de lectura como de escritura son «borrosas» atendiendo suavemente a todas las direcciones de memoria.
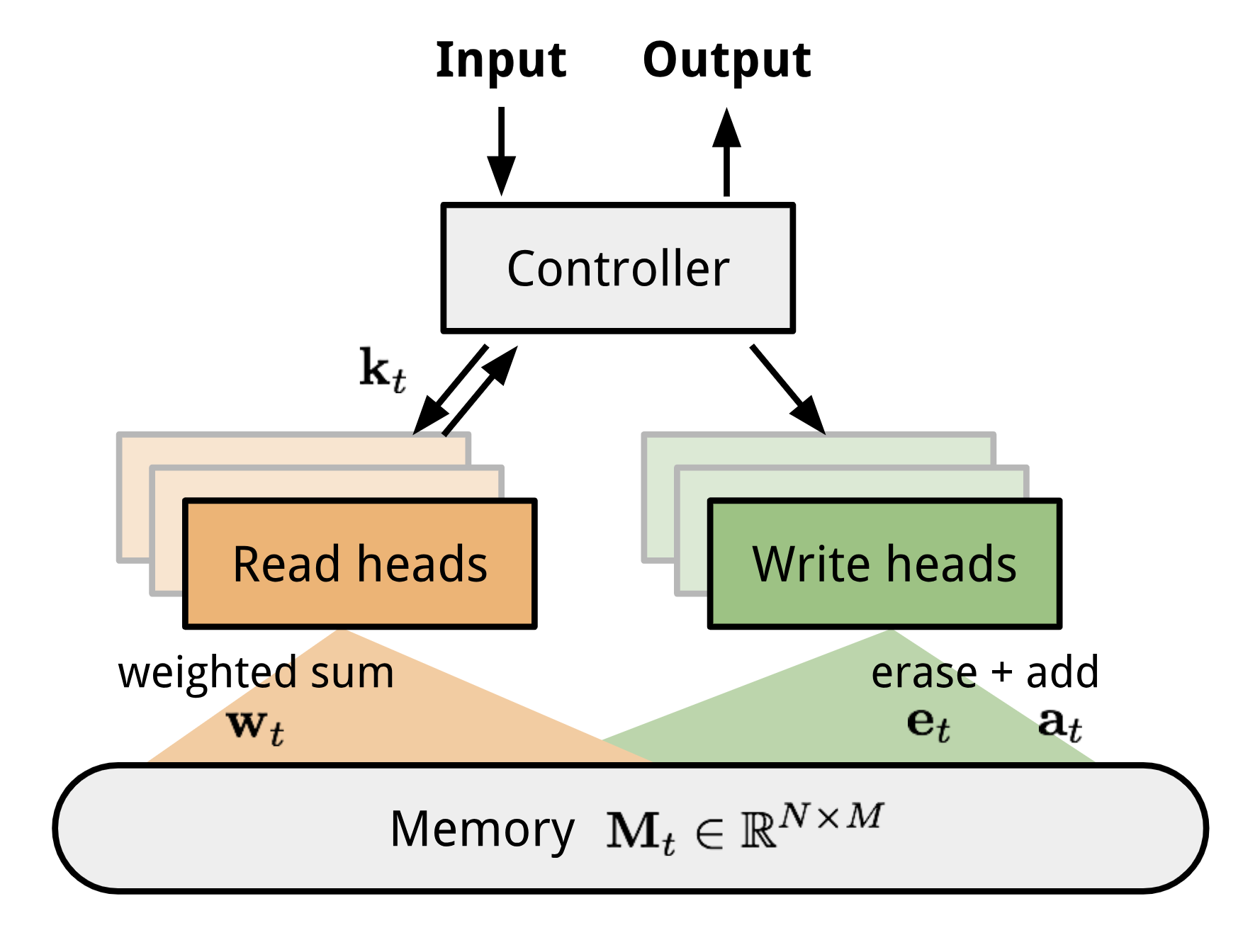
Fig 10. Arquitectura de la máquina neuronal de Turing.
Lectura y escritura
donde \(w_t(i)\) es el elemento \(i)-ésimo en \(\mathbf{w}_t\) y \(\mathbf{M}_t(i)\Nes el vector de la fila \(i)-ésima en la memoria.
&Estilo de escritura{{; borrar}} {\a}mathbf{M}_t(i) &= \tilde{mathbf{M}_t(i) + w_t(i) &Estilo de escritura{{;}texto{; add}{end}{aligned}]
Mecanismos de atención
En la Máquina de Turing Neural, la forma de generar la distribución de la atención \(\mathbf{w}_t\) depende de los mecanismos de direccionamiento: NTM utiliza una mezcla de direccionamientos basados en el contenido y en la localización.
El direccionamiento basado en el contenido
El direccionamiento basado en el contenido crea vectores de atención basados en la similitud entre el vector clave \(\mathbf{k}_t) extraído por el controlador de las filas de entrada y de memoria. Las puntuaciones de atención basadas en el contenido se calculan como similitud coseno y luego se normalizan mediante softmax. Además, NTM añade un multiplicador de fuerza \(\beta_t\) para amplificar o atenuar el foco de la distribución.
)= \frac{exp(\beta_t \frac{mathbf{k}_t \cdot \mathbf{M}_t(i)}{||mathbf{k}_t|\cdot ||mathbf{M}_t(i)|)}{{suma_{j=1}^N \exp(\beta_t \frac{mathbf{k}_t \cdot \mathbf{M}_t(j)}{||mathbf{k}_t|||||mathbf{M}_t(j)|})}]
Interpolación
A continuación, se utiliza un escalar de puerta de interpolación \(g_t\) para mezclar el vector de atención basado en el contenido recién generado con las ponderaciones de atención.con los pesos de atención en el último paso de tiempo:
\
Direccionamiento basado en la localización
El direccionamiento basado en la localización suma los valores en diferentes posiciones del vector de atención, ponderados por una distribución de ponderación sobre los desplazamientos enteros permitidos. Equivale a una convolución 1-d con un kernel \(\mathbf{s}_t(.)\Nde una función del desplazamiento de posición. Hay múltiples formas de definir esta distribución. Véase la Fig. 11. para inspirarse.
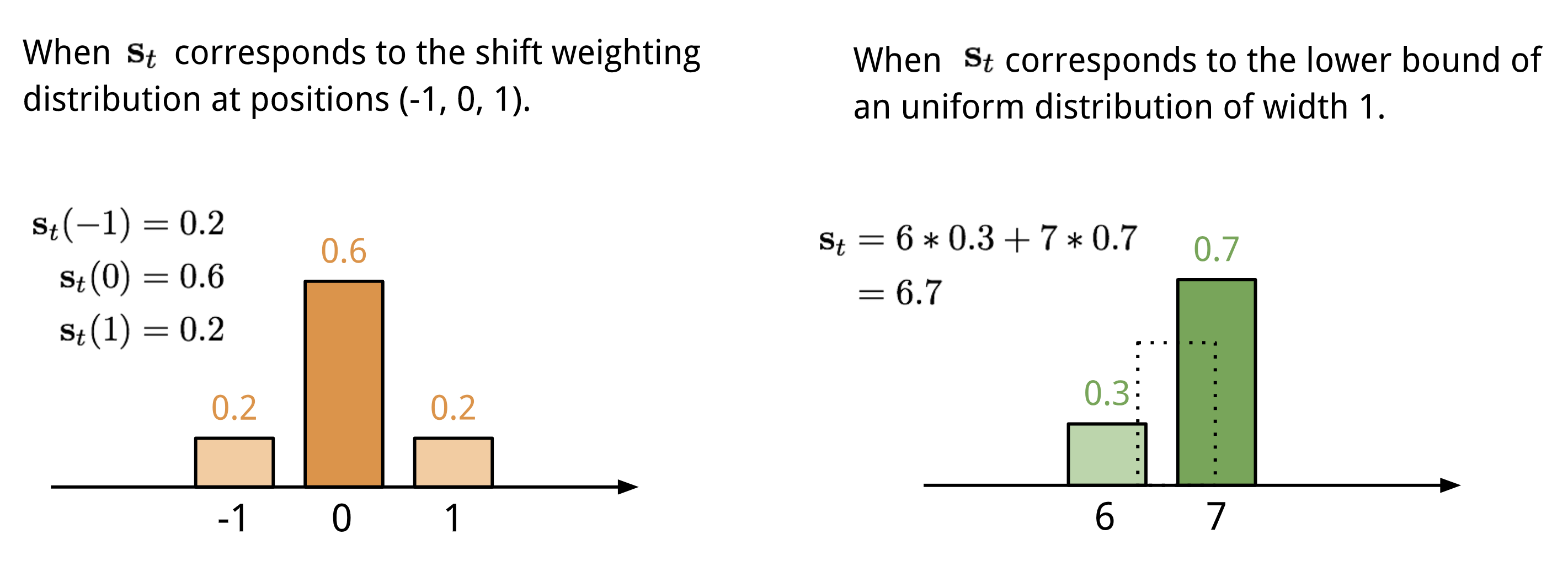
Fig. 11. Dos formas de representar la distribución de ponderación de turnos \(\mathbf{s}_t\).
Por último, la distribución de atención se mejora mediante un escalar de agudización \(\gamma_t \geq 1\).
El proceso completo de generación del vector de atención (\mathbf{w}_t\) en el paso de tiempo t se ilustra en la Fig. 12. Todos los parámetros producidos por el controlador son únicos para cada cabeza. Si hay múltiples cabezas de lectura y escritura en paralelo, el controlador produciría múltiples conjuntos.
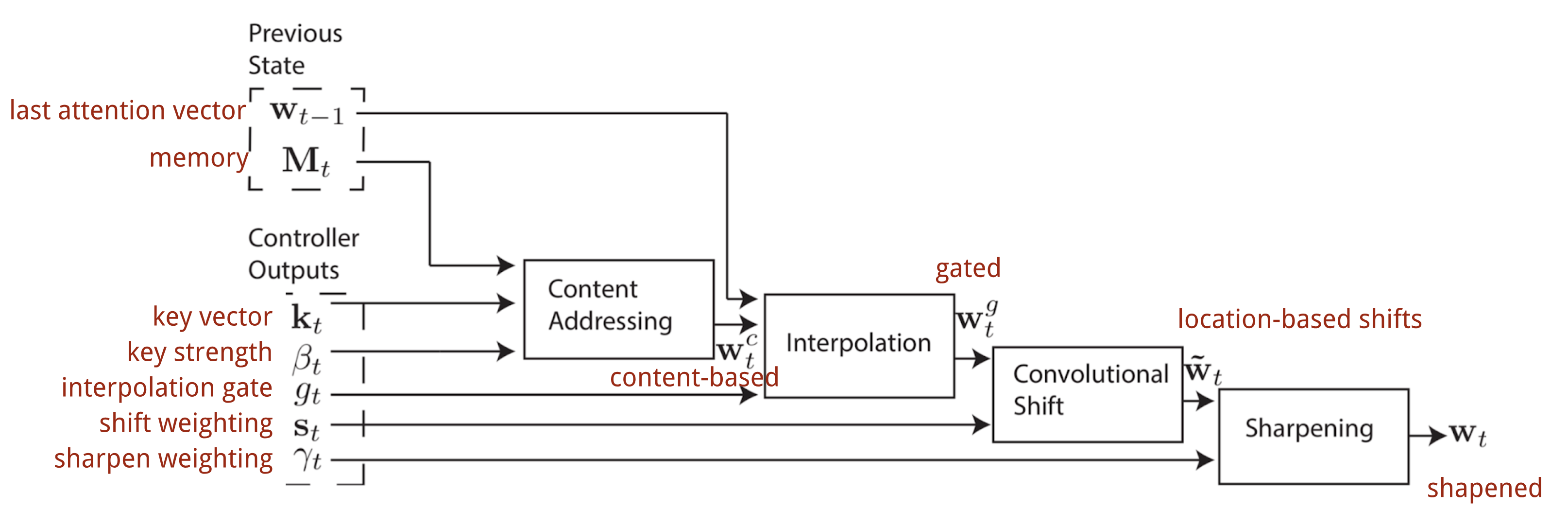
Fig. 12. Diagrama de flujo de los mecanismos de direccionamiento en la Máquina de Turing Neural. (Fuente de la imagen: Graves, Wayne & Danihelka, 2014)
Red de punteros
En problemas como la clasificación o el viajante de comercio, tanto la entrada como la salida son datos secuenciales. Desgraciadamente, no se pueden resolver fácilmente con los modelos clásicos seq-2-seq o NMT, dado que las categorías discretas de los elementos de salida no están determinadas de antemano, sino que dependen del tamaño variable de la entrada. Para resolver este tipo de problemas se propone la red de punteros (Ptr-Net; Vinyals, et al. 2015): Cuando los elementos de salida corresponden a posiciones en una secuencia de entrada. En lugar de utilizar la atención para mezclar las unidades ocultas de un codificador en un vector de contexto (Ver Fig. 8), la Pointer Net aplica la atención sobre los elementos de entrada para elegir uno como salida en cada paso del decodificador.
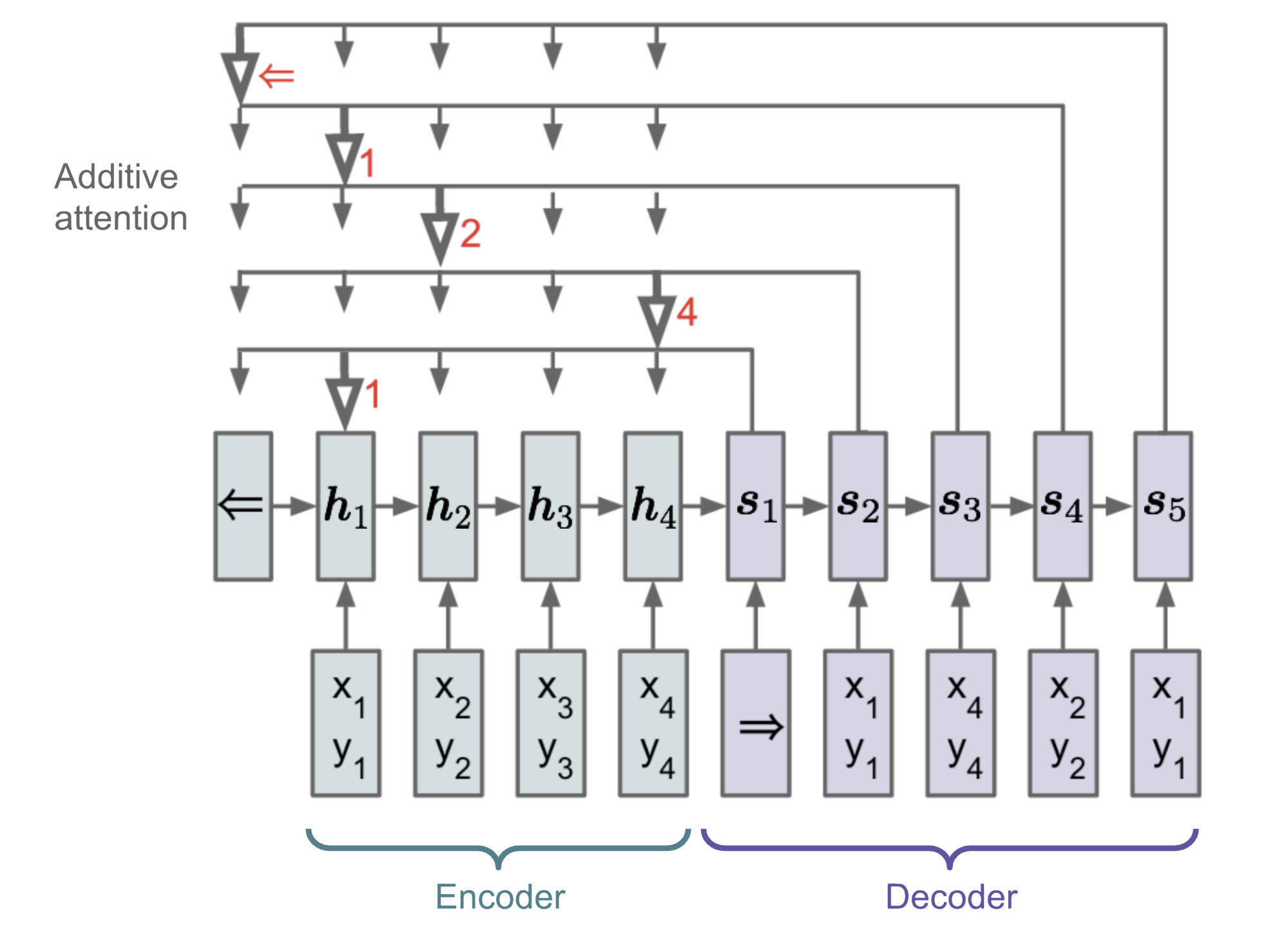
Fig. 13. La arquitectura de un modelo de Red de Apuntadores. (Fuente de la imagen: Vinyals, et al. 2015)
|end{aligned}]
El mecanismo de atención se simplifica, ya que Ptr-Net no mezcla los estados del codificador en la salida con pesos de atención. De esta manera, la salida solo responde a las posiciones pero no al contenido de entrada.
Transformador
«Attention is All you Need» (Vaswani, et al., 2017), sin duda, es uno de los paper más impactantes e interesantes de 2017. Presentó un montón de mejoras en la atención blanda y hace posible el modelado seq2seq sin unidades de red recurrentes. El modelo «transformador» propuesto se construye enteramente sobre los mecanismos de autoatención sin utilizar la arquitectura recurrente alineada con la secuencia.
La receta secreta se lleva en su arquitectura del modelo.
Clave, valor y consulta
El transformador adopta la atención de producto-punto escalado: la salida es una suma ponderada de los valores, donde el peso asignado a cada valor está determinado por el producto-punto de la consulta con todas las claves:
Autoatención multicabezal
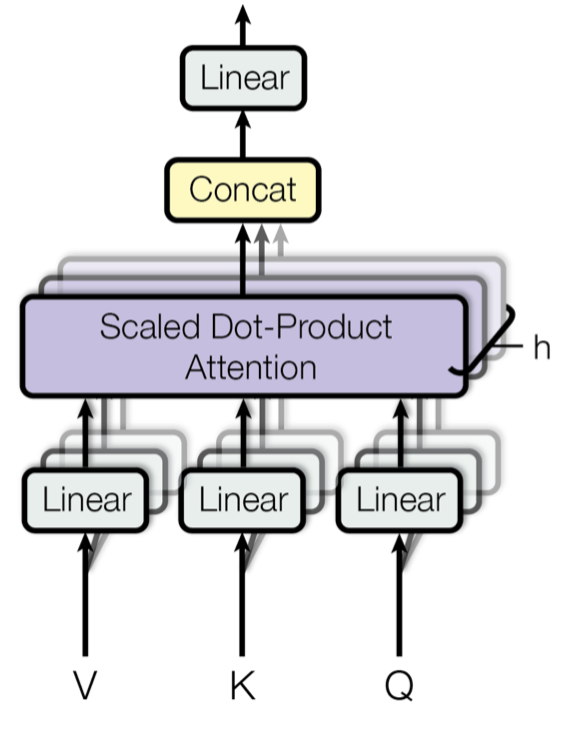
Fig. 14. Mecanismo de atención de múltiples cabezas a escala de producto de puntos. (Fuente de la imagen: Fig 2 en Vaswani, et al., 2017)
En lugar de calcular la atención una sola vez, el mecanismo multicabezal ejecuta la atención de producto de punto escalado múltiples veces en paralelo. Las salidas de atención independientes simplemente se concatenan y se transforman linealmente en las dimensiones esperadas. Supongo que la motivación es que el ensamblaje siempre ayuda… 😉 Según el artículo, «la atención multicabezal permite al modelo atender conjuntamente a la información de diferentes subespacios de representación en diferentes posiciones. Con una sola cabeza de atención, el promedio inhibe esto.»
\Nmathbf{W}^O \\\Ncon cabeza}_i &= \Ntext{Atención}(\Nmathbf{Q}\Nmathbf{W}^Q_i, \Nmathbf{K}\Nmathbf{W}^K_i, \donde \N(\Nmathbf{W}^Q_i), \N(\Nmathbf{W}^V_i), \N(\Nmathbf{W}^V_i), y \N(\Nmathbf{W}^O\N) son matrices de parámetros a aprender.
Codificador
![]()
Fig. 15. El codificador del transformador. (Fuente de la imagen: Vaswani, et al, 2017)
El codificador genera una representación basada en la atención con capacidad para localizar una pieza específica de información de un contexto potencialmente infinitamente grande.
- Una pila de N=6 capas idénticas.
- Cada capa tiene una capa de autoatención multicabezal y una red simple de avance totalmente conectada en función de la posición.
- Cada subcapa adopta una conexión residual y una normalización de la capa.Todas las subcapas dan salida a datos de la misma dimensión \(d_\text{model} = 512\).
Decodificador
![]()
Fig. 16. El decodificador del transformador. (Fuente de la imagen: Vaswani, et al, 2017)
El decodificador es capaz de recuperar a partir de la representación codificada.
- Una pila de N = 6 capas idénticas
- Cada capa tiene dos subcapas de mecanismos de atención multicabeza y una subcapa de red feed-forward totalmente conectada.
- De forma similar al codificador, cada subcapa adopta una conexión residual y una normalización de capas.
- La primera subcapa de atención multicabezal se modifica para evitar que las posiciones atiendan a las posiciones posteriores, ya que no queremos mirar al futuro de la secuencia objetivo al predecir la posición actual.
Arquitectura completa
Por último, aquí está la vista completa de la arquitectura del transformador:
- Tanto las secuencias de origen como las de destino pasan primero por capas de incrustación para producir datos de la misma dimensión \(d_\text{model} =512\).
- Para preservar la información de posición, se aplica una codificación posicional basada en ondas sinusoidales y se suma con la salida de incrustación.
- A la salida final del decodificador se añaden un softmax y una capa lineal.
![]()
Fig. 17. La arquitectura del modelo completo del transformador. (Fuente de la imagen: Fig 1 & 2 en Vaswani, et al., 2017.)
Intentar implementar el modelo del transformador es una experiencia interesante, aquí está la mía: lilianweng/transformer-tensorflow. Lee los comentarios del código si te interesa.
SNAIL
El transformador no tiene estructura recurrente ni convolutiva, incluso con la codificación posicional añadida al vector de incrustación, el orden secuencial sólo se incorpora débilmente. Para los problemas sensibles a la dependencia posicional como el aprendizaje de refuerzo, esto puede ser un gran problema.
El Meta-Aprendizaje Neural Simple (SNAIL) (Mishra et al., 2017) fue desarrollado parcialmente para resolver el problema con el posicionamiento en el modelo transformador combinando el mecanismo de auto-atención en el transformador con convoluciones temporales. Se ha demostrado que es bueno tanto en tareas de aprendizaje supervisado como de aprendizaje por refuerzo.
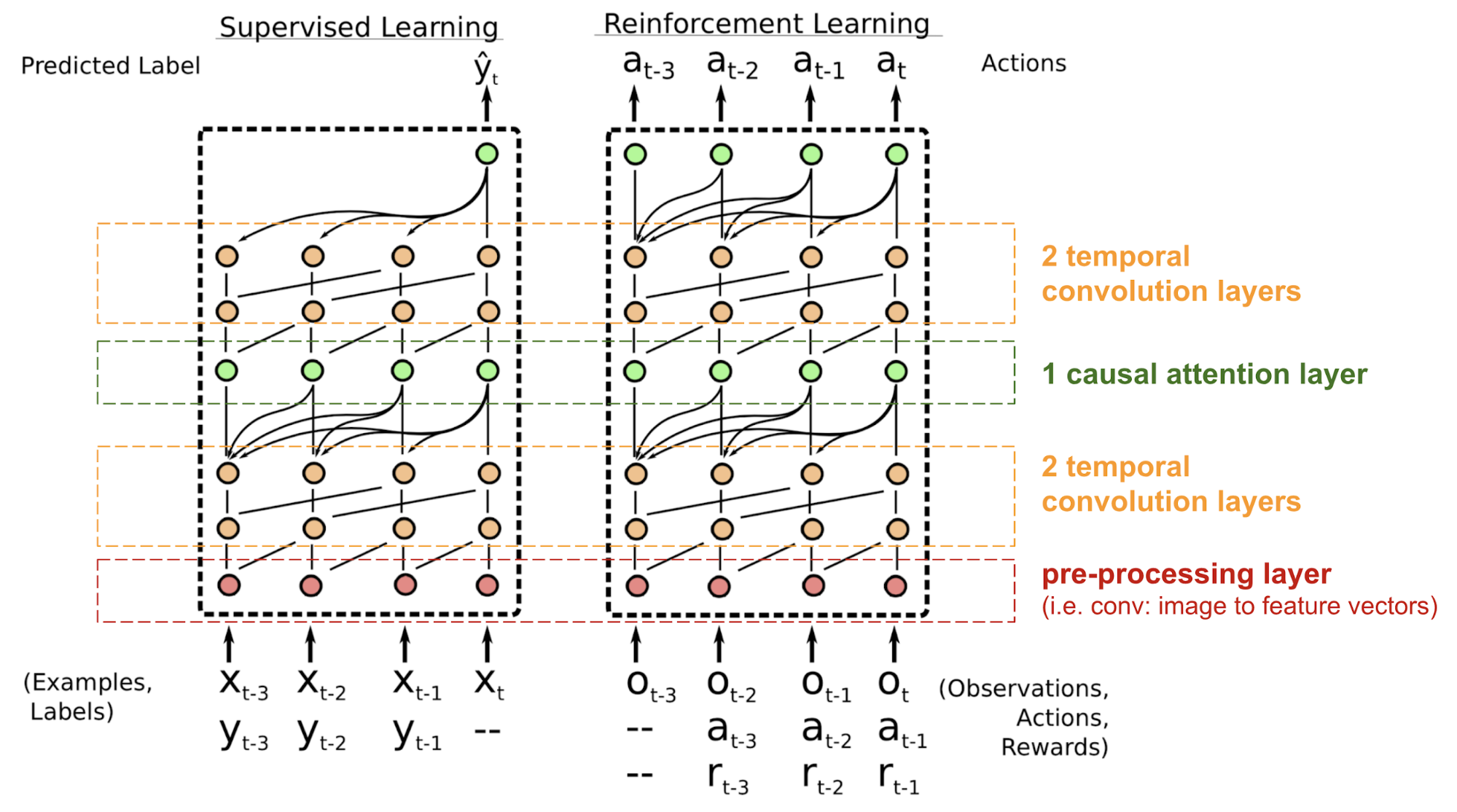
Fig. 18. Arquitectura del modelo SNAIL (Fuente de la imagen: Mishra et al., 2017)
SNAIL nació en el campo del meta-aprendizaje, que es otro gran tema digno de un post por sí mismo. Pero en palabras sencillas, se espera que el modelo de meta-aprendizaje sea generalizable a tareas novedosas y no vistas en la distribución similar. Lee esta bonita introducción si estás interesado.
Self-Attention GAN
Self-Attention GAN (SAGAN; Zhang et al., 2018) añade capas de autoatención en GAN para permitir que tanto el generador como el discriminador modelen mejor las relaciones entre regiones espaciales.
El clásico DCGAN (Deep Convolutional GAN) representa tanto al discriminador como al generador como redes convolucionales multicapa. Sin embargo, la capacidad de representación de la red está restringida por el tamaño del filtro, ya que la característica de un píxel está limitada a una pequeña región local. Para conectar regiones alejadas, las características tienen que diluirse a través de capas de operaciones convolucionales y no se garantiza el mantenimiento de las dependencias.
Como la autoatención (suave) en el contexto de la visión está diseñada para aprender explícitamente la relación entre un píxel y todas las demás posiciones, incluso las regiones alejadas, puede capturar fácilmente las dependencias globales. Por lo tanto, se espera que la GAN equipada con auto-atención maneje mejor los detalles, ¡hurra!
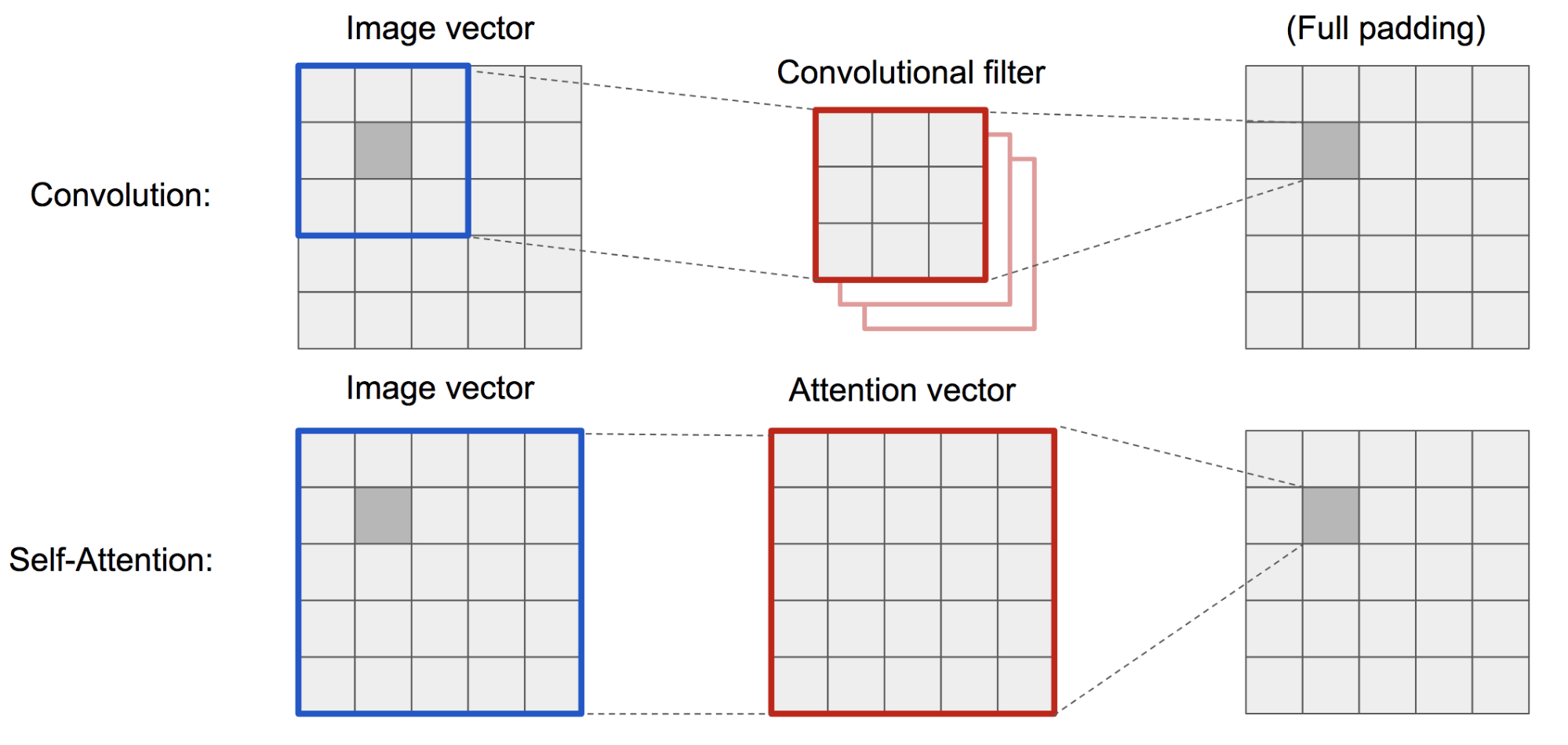
Fig. 19. La operación de convolución y la autoatención tienen acceso a regiones de tamaños muy diferentes.
El SAGAN adopta la red neuronal no local para aplicar el cálculo de la atención. Los mapas convolucionales de características de la imagen \(\mathbf{x}\) se ramifican en tres copias, correspondientes a los conceptos de clave, valor y consulta en el transformador:
- Clave: \(f(\mathbf{x}) = \mathbf{W}_f \mathbf{x})
- Consulta: \N-(g(\mathbf{x}) = \mathbf{W}_g \mathbf{x})
- Valor: \(h(\mathbf{x}) = \mathbf{W}_h \mathbf{x})
A continuación, aplicamos la atención punto-producto para dar salida a los mapas de características de autoatención:
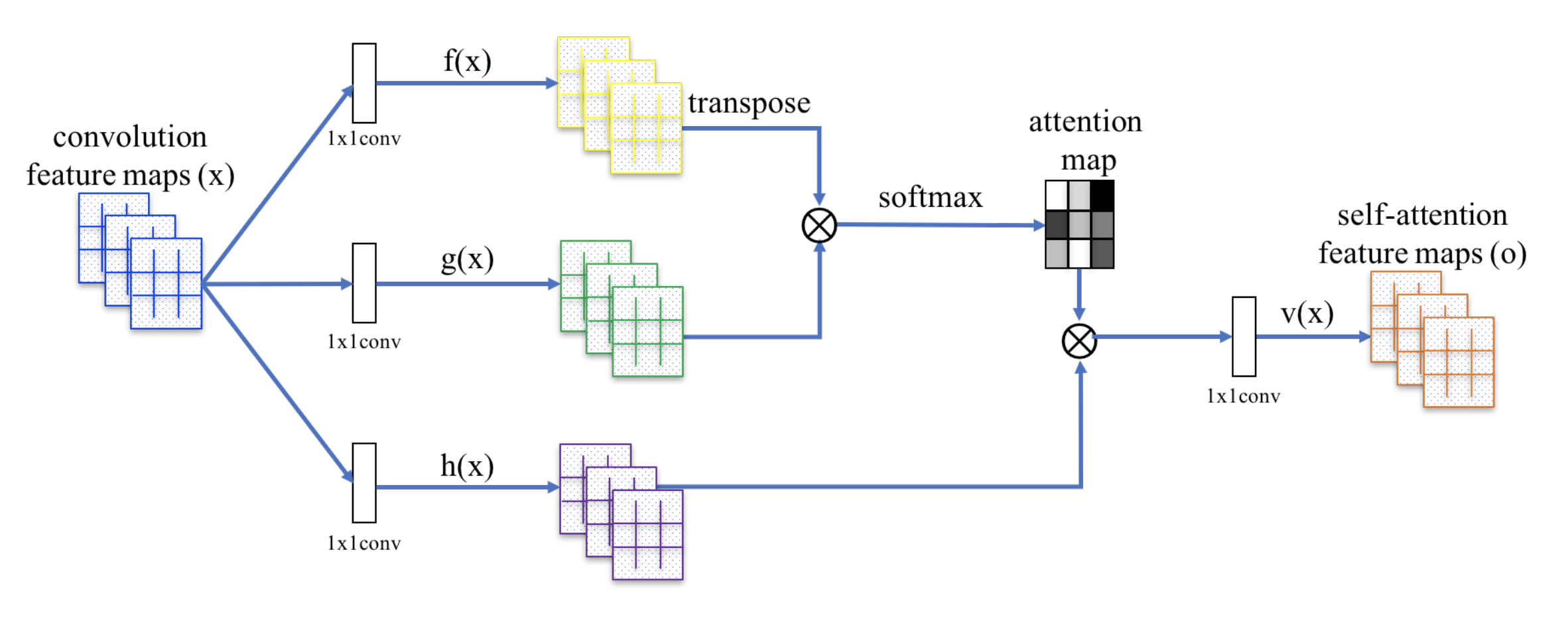
Fig. 20. El mecanismo de autoatención en SAGAN. (Fuente de la imagen: Fig. 2 en Zhang et al, 2018)
Además, la salida de la capa de atención se multiplica por un parámetro de escala y se añade de nuevo al mapa de características de entrada original:
Mientras que el parámetro de escala \(\gamma\) se incrementa gradualmente desde 0 durante el entrenamiento, la red está configurada para confiar primero en las pistas de las regiones locales y luego aprender gradualmente a asignar más peso a las regiones que están más lejos.

Fig. 21. Imágenes de ejemplo de 128×128 generadas por SAGAN para diferentes clases. (Fuente de la imagen: Fig. 6 parcial en Zhang et al., 2018)
Citado como:
¡Si notáis errores y faltas en este post, no dudéis en poneros en contacto conmigo en y estaré encantado de corregirlos enseguida!
Nos vemos en el próximo post 😀
«Atención y memoria en aprendizaje profundo y PNL». – 3 de enero de 2016 por Denny Britz
«Tutorial de traducción automática neuronal (seq2seq)»
Dzmitry Bahdanau, Kyunghyun Cho, y Yoshua Bengio. «Traducción automática neuronal mediante el aprendizaje conjunto de la alineación y la traducción». ICLR 2015.
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, y Yoshua Bengio. «Mostrar, atender y contar: Generación neuronal de pies de foto con atención visual». ICML, 2015.
Ilya Sutskever, Oriol Vinyals, y Quoc V. Le. «Aprendizaje de secuencia a secuencia con redes neuronales». NIPS 2014.
Thang Luong, Hieu Pham, Christopher D. Manning. «Enfoques eficaces para la traducción automática neuronal basada en la atención». EMNLP 2015.
Denny Britz, Anna Goldie, Thang Luong y Quoc Le. «Exploración masiva de arquitecturas neuronales de traducción automática». ACL 2017.
Ashish Vaswani, et al. «La atención es todo lo que necesitas». NIPS 2017.
Jianpeng Cheng, Li Dong, y Mirella Lapata. «Redes de memoria a largo plazo para la lectura automática». EMNLP 2016.
Xiaolong Wang, et al. «Redes neuronales no locales». CVPR 2018
Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, y Pieter Abbeel. «Un simple meta-aprendizaje neuronal atento». ICLR 2018.
«WaveNet: A Generative Model for Raw Audio» – 8 de septiembre de 2016 por DeepMind.
Oriol Vinyals, Meire Fortunato, y Navdeep Jaitly. «Redes de punteros». NIPS 2015.
Alex Graves, Greg Wayne, e Ivo Danihelka. «Neural turing machines». arXiv preprint arXiv:1410.5401 (2014).