Attention ? Attention !
L’attention a été un concept assez populaire et un outil utile dans la communauté de l’apprentissage profond ces dernières années. Dans ce post, nous allons examiner comment l’attention a été inventée, et divers mécanismes et modèles d’attention, tels que transformateur et SNAIL.
L’attention est, dans une certaine mesure, motivée par la façon dont nous accordons une attention visuelle à différentes régions d’une image ou corrélons des mots dans une phrase. Prenons l’exemple de la photo d’un Shiba Inu dans la Fig. 1.

Fig. 1. Un Shiba Inu dans une tenue d’homme. Le crédit de la photo originale va à Instagram @mensweardog.
L’attention visuelle humaine nous permet de nous concentrer sur une certaine région avec une « haute résolution » (c’est-à-dire regarder l’oreille pointue dans la boîte jaune) tout en percevant l’image environnante en « basse résolution » (c’est-à-dire maintenant que dire du fond enneigé et de la tenue ?), puis d’ajuster le point focal ou de faire l’inférence en conséquence. Pour une petite partie d’une image, les pixels du reste de l’image fournissent des indices sur ce qui devrait y être affiché. Nous nous attendons à voir une oreille pointue dans la case jaune parce que nous avons vu le nez d’un chien, une autre oreille pointue à droite et les yeux mystérieux de Shiba (dans les cases rouges). Cependant, le pull et la couverture en bas ne seraient pas aussi utiles que ces caractéristiques canines.
De même, nous pouvons expliquer la relation entre les mots dans une phrase ou un contexte proche. Lorsque nous voyons « manger », nous nous attendons à rencontrer un mot de nourriture très bientôt. Le terme de couleur décrit la nourriture, mais probablement pas autant avec « manger » directement.
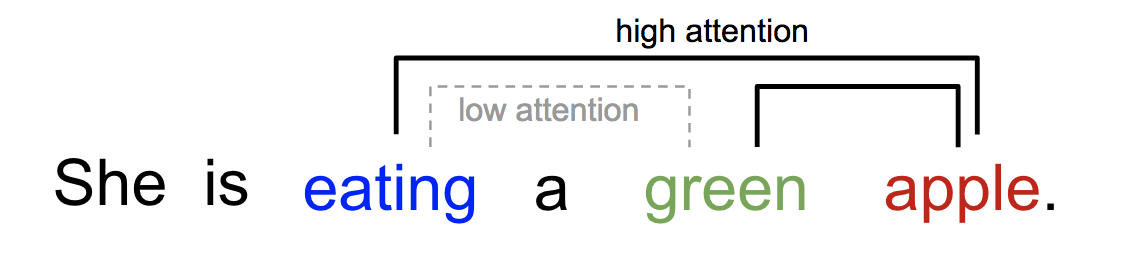
Fig. 2. Un mot « attend » différemment d’autres mots dans la même phrase.
En bref, l’attention dans l’apprentissage profond peut être largement interprétée comme un vecteur de poids d’importance : pour prédire ou inférer un élément, comme un pixel dans une image ou un mot dans une phrase, nous estimons à l’aide du vecteur d’attention à quel point il est corrélé avec (ou « attend » comme vous avez pu le lire dans de nombreux articles) d’autres éléments et prenons la somme de leurs valeurs pondérées par le vecteur d’attention comme l’approximation de la cible.
- Qu’est-ce qui ne va pas avec le modèle Seq2Seq?
- Né pour la traduction
- Définition
- Une famille de mécanismes d’attention
- Sommaire
- Self-Attention
- Soft vs Hard Attention
- Attention globale vs locale
- Machines de Turing neurales
- Lecture et écriture
- Mécanismes d’attention
- Réseau de pointeurs
- Transformer
- Clé, valeur et requête
- Autoattention à têtes multiples
- Encodeur
- Décodeur
- Architecture complète
- SNAIL
- Self-Attention GAN
Qu’est-ce qui ne va pas avec le modèle Seq2Seq?
Le modèle seq2seq est né dans le domaine de la modélisation du langage (Sutskever, et al. 2014). Grosso modo, il vise à transformer une séquence d’entrée (source) en une nouvelle (cible) et les deux séquences peuvent être de longueur arbitraire. Des exemples de tâches de transformation incluent la traduction automatique entre plusieurs langues, que ce soit en texte ou en audio, la génération de dialogues question-réponse, ou même l’analyse syntaxique de phrases en arbres grammaticaux.
Le modèle seq2seq a normalement une architecture encodeur-décodeur, composée de :
- Un encodeur traite la séquence d’entrée et comprime l’information dans un vecteur de contexte (également connu sous le nom d’encastrement de phrase ou vecteur de » pensée « ) d’une longueur fixe. Cette représentation est censée être un bon résumé du sens de la séquence source entière.
- Un décodeur est initialisé avec le vecteur de contexte pour émettre la sortie transformée. Les premiers travaux utilisaient uniquement le dernier état du réseau de l’encodeur comme état initial du décodeur.
L’encodeur et le décodeur sont tous deux des réseaux neuronaux récurrents, c’est-à-dire utilisant des unités LSTM ou GRU.
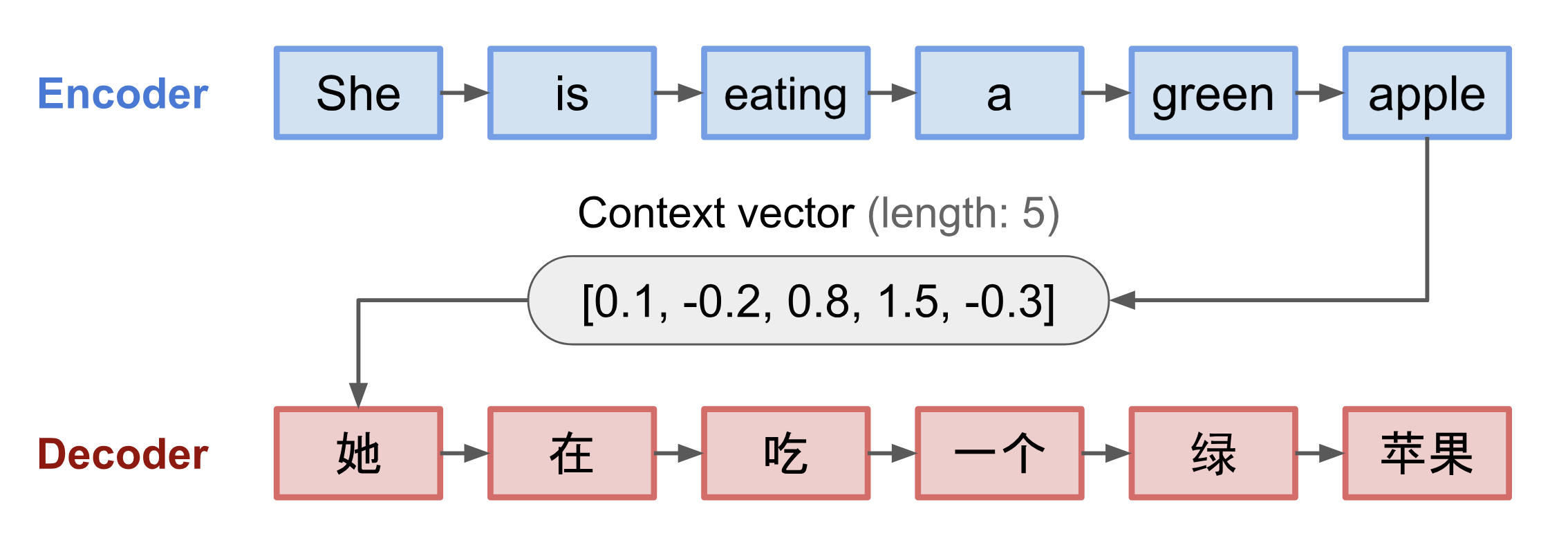
Fig. 3. Le modèle encodeur-décodeur, traduisant la phrase « elle mange une pomme verte » en chinois. La visualisation de l’encodeur et du décodeur est déroulée dans le temps.
Un inconvénient critique et apparent de cette conception de vecteur de contexte à longueur fixe est l’incapacité à se souvenir des longues phrases. Souvent, il a oublié la première partie une fois qu’il a terminé de traiter l’ensemble de l’entrée. Le mécanisme d’attention est né (Bahdanau et al., 2015) pour résoudre ce problème.
Né pour la traduction
Le mécanisme d’attention est né pour aider à mémoriser les longues phrases sources dans la traduction automatique neuronale (NMT). Plutôt que de construire un vecteur de contexte unique à partir du dernier état caché de l’encodeur, la sauce secrète inventée par l’attention consiste à créer des raccourcis entre le vecteur de contexte et l’entrée source entière. Les poids de ces raccourcis de connexion sont personnalisables pour chaque élément de sortie.
Alors que le vecteur de contexte a accès à la totalité de la séquence d’entrée, nous n’avons pas à nous soucier de l’oubli. L’alignement entre la source et la cible est appris et contrôlé par le vecteur de contexte. Essentiellement, le vecteur de contexte consomme trois éléments d’information:
- états cachés de l’encodeur;
- états cachés du décodeur;
- alignement entre la source et la cible.
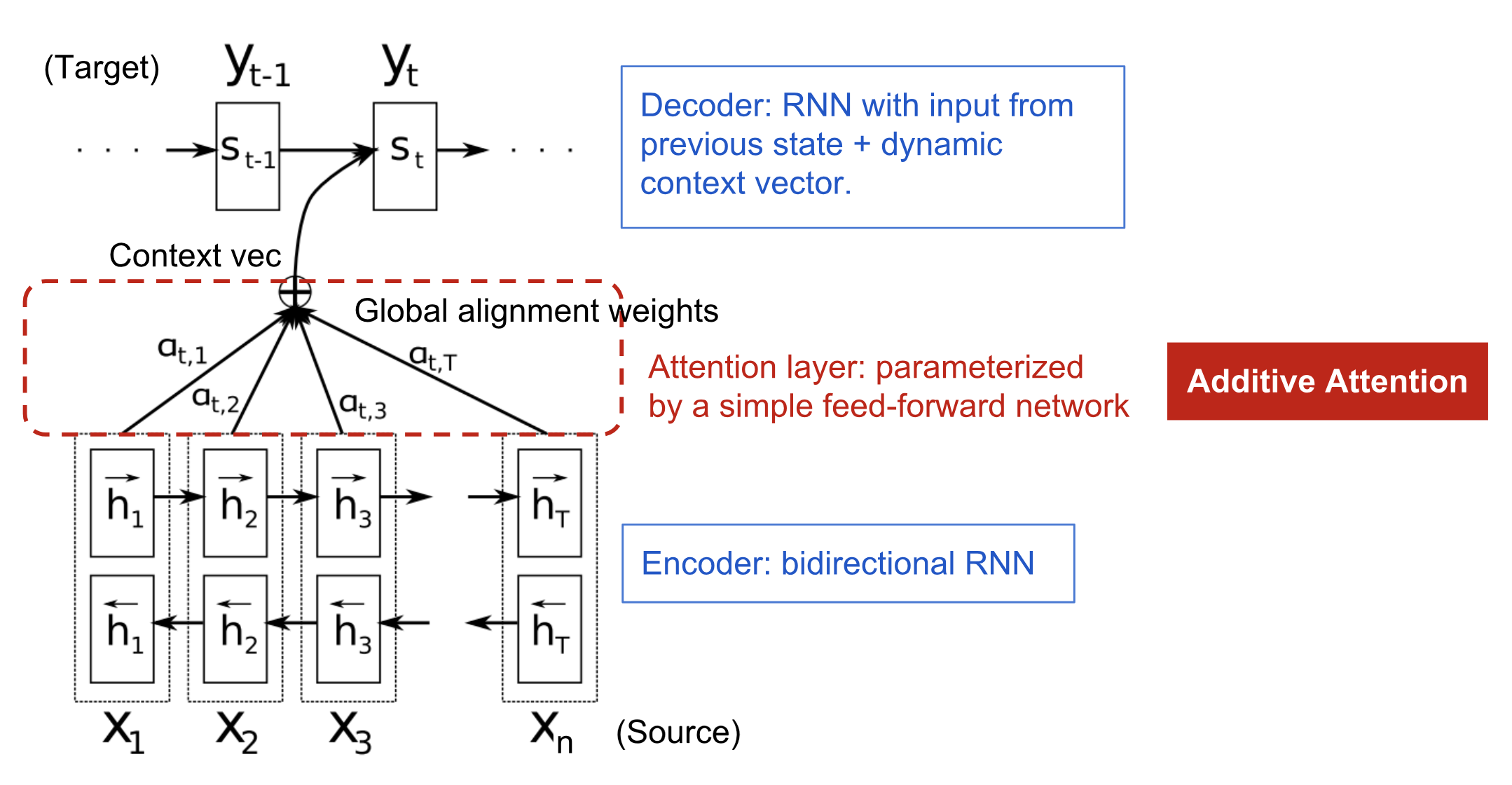
Fig. 4. Le modèle d’encodeur-décodeur avec mécanisme d’attention additif dans Bahdanau et al., 2015.
Définition
\\\\\\\\mathbf{y}. &= \end{aligned}\]
(Les variables en gras indiquent qu’il s’agit de vecteurs ; idem pour tout le reste dans ce post.)
L’encodeur est un RNN bidirectionnel (ou un autre paramètre de réseau récurrent de votre choix) avec un état caché avant \(\overrightarrow{\boldsymbol{h}}_i\) et un état caché arrière \(\overleftarrow{\boldsymbol{h}}_i\). Une simple concaténation de deux représente l’état du codeur. La motivation est d’inclure les mots précédents et suivants dans l’annotation d’un mot.
\^\top, i=1,\dots,n\]\\)\]
où à la fois \(\mathbf{v}_a\) et \(\mathbf{W}_a\) sont des matrices de poids à apprendre dans le modèle d’alignement.
La matrice des scores d’alignement est un sous-produit agréable pour montrer explicitement la corrélation entre les mots source et cible.

Fig. 5. Matrice d’alignement de « L’accord sur l’Espace économique européen a été signé en août 1992 » (français) et sa traduction anglaise « The agreement on the European Economic Area was signed in August 1992 ». (Source de l’image : Fig 3 dans Bahdanau et al., 2015)
Voyez ce beau tutoriel de l’équipe de Tensorflow pour plus d’instructions d’implémentation.
Une famille de mécanismes d’attention
Avec l’aide de l’attention, les dépendances entre les séquences source et cible ne sont plus limitées par la distance intercalaire ! Étant donné la grande amélioration de l’attention dans la traduction automatique, elle s’est rapidement étendue au domaine de la vision par ordinateur (Xu et al. 2015) et les gens ont commencé à explorer diverses autres formes de mécanismes d’attention (Luong, et al., 2015 ; Britz et al., 2017 ; Vaswani, et al, 2017).
Sommaire
Vous trouverez ci-dessous un tableau récapitulatif de plusieurs mécanismes d’attention populaires et des fonctions de score d’alignement correspondantes :
Voici un résumé de catégories plus larges de mécanismes d’attention :
| Nom | Définition | Citation |
|---|---|---|
| Self-Attention(&) | Relation de différentes positions de la même séquence d’entrée. Théoriquement, l’auto-attention peut adopter toutes les fonctions de score ci-dessus, mais il suffit de remplacer la séquence cible par la même séquence d’entrée. | Cheng2016 |
| Global/Soft | Attendant à tout l’espace d’état d’entrée. | Xu2015 |
| Local/Dur | Attendant à la partie de l’espace d’état d’entrée ; c’est-à-dire un patch de l’image d’entrée. | Xu2015 ; Luong2015 |
(&) Également, appelé « intra-attention » dans Cheng et al, 2016 et quelques autres articles.
Self-Attention
L’auto-attention, également appelée intra-attention, est un mécanisme d’attention mettant en relation différentes positions d’une même séquence afin de calculer une représentation de cette même séquence. Il a été démontré qu’il est très utile pour la lecture automatique, le résumé abstractif ou la génération de descriptions d’images.
L’article sur le réseau de mémoire à long court terme a utilisé l’auto-attention pour faire de la lecture automatique. Dans l’exemple ci-dessous, le mécanisme d’auto-attention nous permet d’apprendre la corrélation entre les mots actuels et la partie précédente de la phrase.

Fig. 6. Le mot actuel est en rouge et la taille de l’ombre bleue indique le niveau d’activation. (Source de l’image : Cheng et al., 2016)
Soft vs Hard Attention
Dans l’article show, attend and tell, le mécanisme d’attention est appliqué aux images pour générer des légendes. L’image est d’abord codée par un CNN pour extraire des caractéristiques. Ensuite, un décodeur LSTM consomme les caractéristiques de convolution pour produire des mots descriptifs un par un, où les poids sont appris par l’attention. La visualisation des poids d’attention démontre clairement les régions de l’image auxquelles le modèle prête attention afin de produire un certain mot.

Fig. 7. « Une femme lance un frisbee dans un parc ». (Source de l’image : Fig. 6(b) in Xu et al. 2015)
Cet article a d’abord proposé la distinction entre l’attention « douce » vs « dure », selon que l’attention a accès à l’image entière ou seulement à un patch :
- Attention douce : les poids d’alignement sont appris et placés « doucement » sur tous les patchs de l’image source ; essentiellement le même type d’attention que dans Bahdanau et al., 2015.
- Pro : le modèle est lisse et différentiable.
- Con : coûteux lorsque l’entrée de la source est grande.
- Hard Attention : ne sélectionne qu’un patch de l’image pour y prêter attention à la fois.
- Pro : moins de calculs au moment de l’inférence.
- Con : le modèle est non-différenciable et nécessite des techniques plus compliquées comme la réduction de la variance ou l’apprentissage par renforcement pour s’entraîner. (Luong, et al., 2015)
Attention globale vs locale
Luong, et al., 2015 ont proposé l’attention « globale » et « locale ». L’attention globale est similaire à l’attention douce, tandis que l’attention locale est un mélange intéressant entre l’attention dure et l’attention douce, une amélioration sur l’attention dure pour la rendre différenciable : le modèle prédit d’abord une position alignée unique pour le mot cible actuel et une fenêtre centrée autour de la position de la source est ensuite utilisée pour calculer un vecteur de contexte.
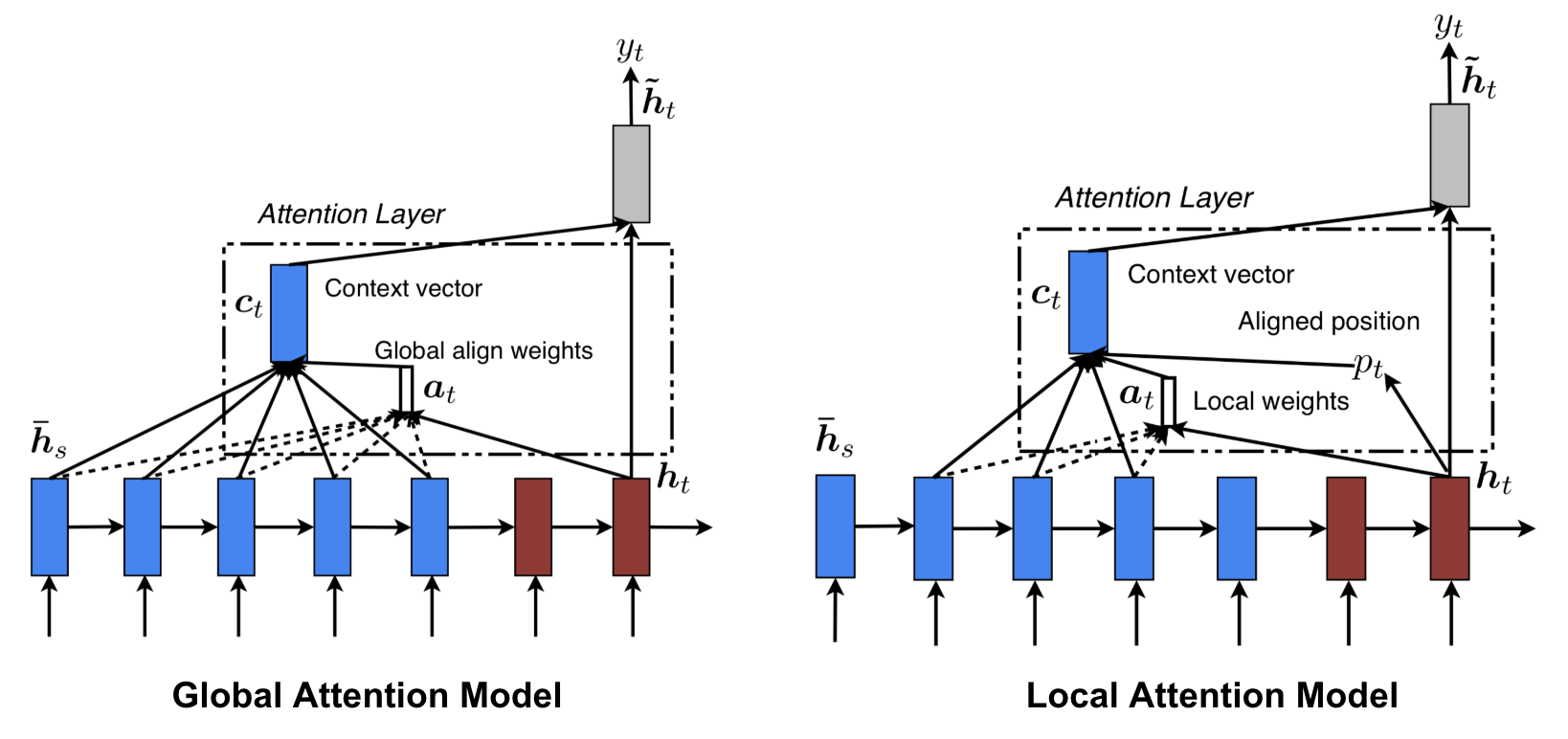
Fig. 8. Attention globale vs locale (Source de l’image : Fig 2 & 3 dans Luong, et al., 2015)
Machines de Turing neurales
Alan Turing en 1936 a proposé un modèle minimaliste de calcul. Il est composé d’une bande infiniment longue et d’une tête permettant d’interagir avec la bande. La bande comporte d’innombrables cellules, chacune remplie d’un symbole : 0, 1 ou blanc ( » « ). La tête d’opération peut lire des symboles, éditer des symboles et se déplacer de gauche à droite sur la bande. En théorie, une machine de Turing peut simuler n’importe quel algorithme informatique, quelle que soit la complexité ou le coût de la procédure. La mémoire infinie donne à une machine de Turing l’avantage d’être mathématiquement illimitée. Cependant, la mémoire infinie n’est pas réalisable dans les ordinateurs modernes réels et alors nous ne considérons la machine de Turing que comme un modèle mathématique de calcul.

Fig. 9. Comment se présente une machine de Turing : une bande + une tête qui manipule la bande. (Source de l’image : http://aturingmachine.com/)
La machine de Turing neuronale (MNT, Graves, Wayne & Danihelka, 2014) est une architecture modèle permettant de coupler un réseau neuronal avec un stockage en mémoire externe. La mémoire imite la bande de la machine de Turing et le réseau neuronal contrôle les têtes d’opération pour lire ou écrire sur la bande. Cependant, la mémoire dans NTM est finie, et donc il ressemble probablement plus à une « Neural von Neumann Machine ».
NTM contient deux composants majeurs, un réseau neuronal contrôleur et une banque de mémoire. Le contrôleur : est chargé d’exécuter les opérations sur la mémoire. Il peut s’agir de n’importe quel type de réseau neuronal, feed-forward ou récurrent.Mémoire : stocke les informations traitées. C’est une matrice de taille \(N \times M\), contenant N rangées de vecteurs et chacune a \(M\) dimensions.
Dans une itération de mise à jour, le contrôleur traite l’entrée et interagit avec la banque de mémoire en conséquence pour générer la sortie. L’interaction est gérée par un ensemble de têtes de lecture et d’écriture parallèles. Les deux opérations de lecture et d’écriture sont « floues » en s’occupant doucement de toutes les adresses de la mémoire.
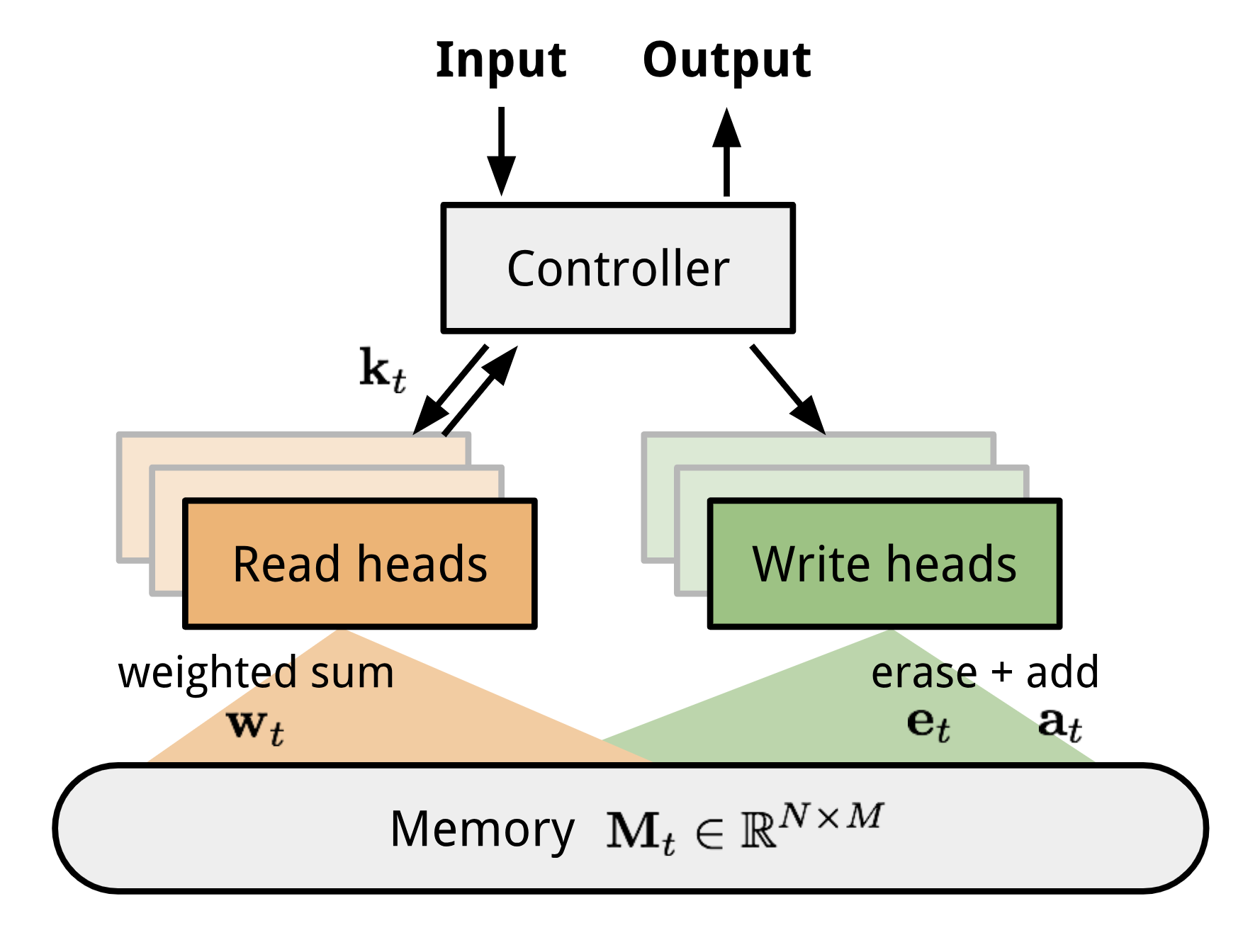
Fig 10. Architecture de la machine de Turing neuronale.
Lecture et écriture
\
où \(w_t(i)\) est le \(i\)-ième élément dans \(\mathbf{w}_t\) et \(\mathbf{M}_t(i)\) est le \(i\)-ième vecteur de ligne dans la mémoire.
\N{9038>\scriptstyle{\text{ ; effacement}}\N{\i}mathbf{M}_t(i) &= \tilde{\mathbf{M}}_t(i) + w_t(i) \mathbf{a}_t &\scriptstyle{\text{ ; add}}\end{aligned}\]
Mécanismes d’attention
Dans la Machine de Turing Neurale, la façon de générer la distribution de l’attention \(\mathbf{w}_t\) dépend des mécanismes d’adressage : NTM utilise un mélange d’adressages basés sur le contenu et sur l’emplacement.
L’adressage basé sur le contenu
L’adressage basé sur le contenu crée des vecteurs d’attention basés sur la similarité entre le vecteur clé \(\mathbf{k}_t\) extrait par le contrôleur des lignes d’entrée et de mémoire. Les scores d’attention basés sur le contenu sont calculés sous forme de similarité cosinusoïdale, puis normalisés par softmax. En outre, NTM ajoute un multiplicateur de force \(\beta_t\) pour amplifier ou atténuer le foyer de la distribution.
\)= \frac{\exp(\beta_t \frac{\mathbf{k}_t \cdot \mathbf{M}_t(i)}{\|\mathbf{k}_t\| \cdot \|\mathbf{M}_t(i)\|})}{\sum_{j=1}^N \exp(\beta_t \frac{\mathbf{k}_t \cdot \mathbf{M}_t(j)}{\|\mathbf{k}_t\| \cdot \|\mathbf{M}_t(j)\|})}\]
Interpolation
Puis un scalaire de porte d’interpolation \(g_t\) est utilisé pour mélanger le vecteur d’attention basé sur le contenu nouvellement généré avec les poids d’attention.vecteur d’attention basé sur le contenu nouvellement généré avec les poids d’attention du dernier pas de temps :
\
L’adressage basé sur l’emplacement
L’adressage basé sur l’emplacement additionne les valeurs à différentes positions dans le vecteur d’attention, pondérées par une distribution de pondération sur les décalages entiers admissibles. Il est équivalent à une convolution 1-d avec un noyau \(\mathbf{s}_t(.)\), fonction du décalage de position. Il existe de multiples façons de définir cette distribution. Voir la Fig. 11. pour s’en inspirer.
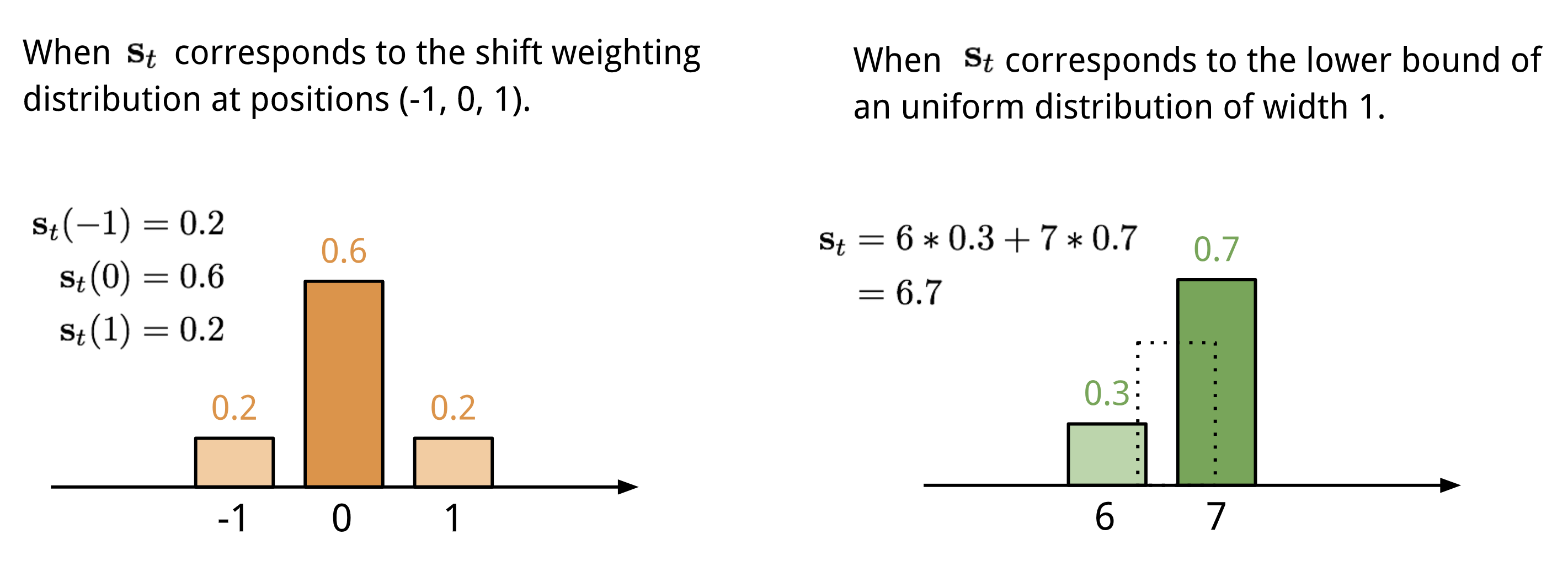
Fig. 11. Deux façons de représenter la distribution de pondération des déplacements \(\mathbf{s}_t\).
Enfin, la distribution de l’attention est améliorée par un scalaire d’affinement \(\gamma_t \geq 1\).
Le processus complet de génération du vecteur d’attention \(\mathbf{w}_t\) au pas de temps t est illustré à la Fig. 12. Tous les paramètres produits par le contrôleur sont uniques pour chaque tête. S’il y a plusieurs têtes de lecture et d’écriture en parallèle, le contrôleur produirait plusieurs ensembles.
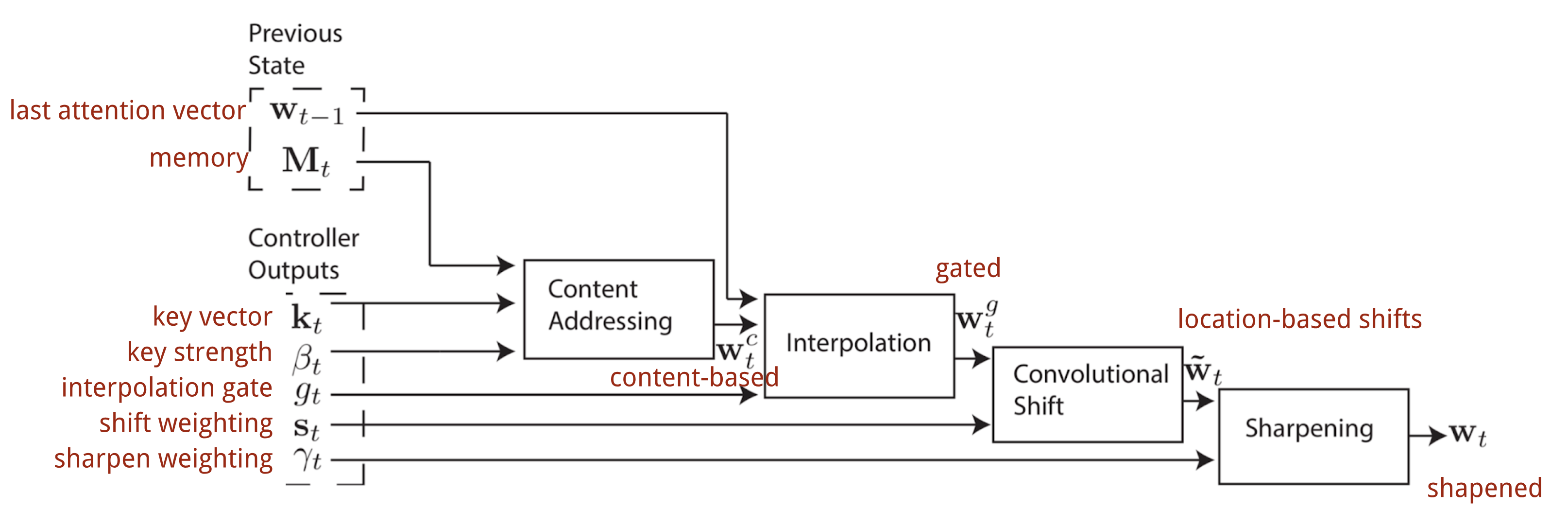
Fig. 12. Diagramme de flux des mécanismes d’adressage dans la machine de Turing neuronale. (Source image : Graves, Wayne & Danihelka, 2014)
Réseau de pointeurs
Dans des problèmes comme le tri ou le voyageur de commerce, l’entrée et la sortie sont toutes deux des données séquentielles. Malheureusement, ils ne peuvent pas être facilement résolus par les modèles classiques seq-2-seq ou NMT, étant donné que les catégories discrètes des éléments de sortie ne sont pas déterminées à l’avance, mais dépendent de la taille variable des entrées. Le Pointer Net (Ptr-Net ; Vinyals, et al. 2015) est proposé pour résoudre ce type de problèmes : Lorsque les éléments de sortie correspondent à des positions dans une séquence d’entrée. Plutôt que d’utiliser l’attention pour mélanger les unités cachées d’un encodeur dans un vecteur de contexte (Voir Fig. 8), le Pointer Net applique l’attention sur les éléments d’entrée pour en choisir un comme sortie à chaque étape du décodeur.
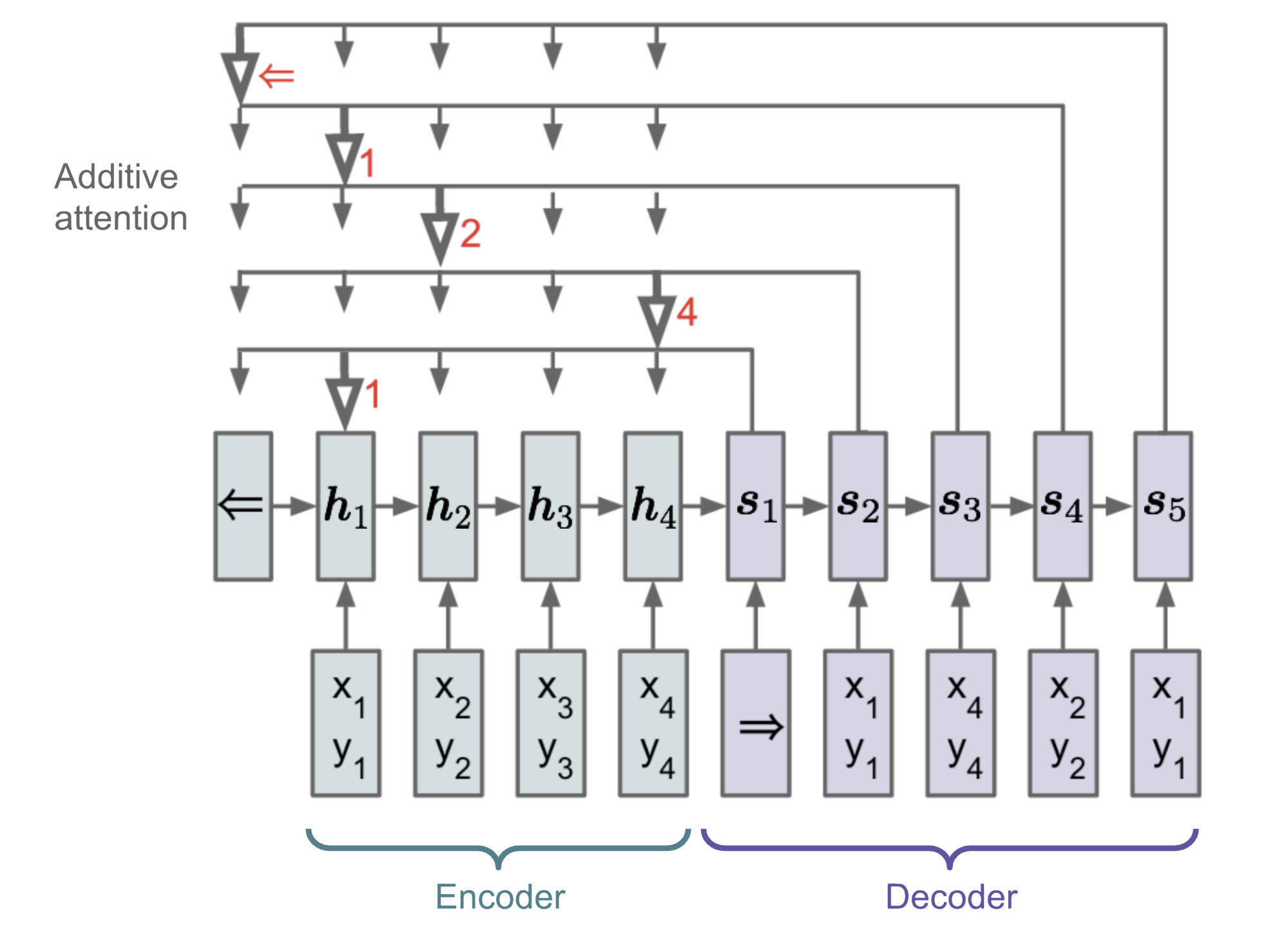
Fig. 13. L’architecture d’un modèle de réseau de pointeurs. (Source image : Vinyals, et al. 2015)
\))\end{aligned}\]
Le mécanisme d’attention est simplifié, car Ptr-Net ne mélange pas les états de l’encodeur dans la sortie avec des poids d’attention. De cette façon, la sortie ne répond qu’aux positions mais pas au contenu de l’entrée.
Transformer
« Attention is All you Need » (Vaswani, et al., 2017), sans aucun doute, est l’un des papiers les plus impactants et intéressants de 2017. Il a présenté beaucoup d’améliorations de l’attention douce et rend possible la modélisation seq2seq sans unités de réseau récurrentes. Le modèle « transformateur » proposé est entièrement construit sur les mécanismes d’auto-attention sans utiliser l’architecture récurrente alignée sur la séquence.
La recette secrète est portée dans l’architecture de son modèle.
Clé, valeur et requête
Le transformateur adopte l’attention point-produit échelonnée : la sortie est une somme pondérée des valeurs, où le poids attribué à chaque valeur est déterminé par le point-produit de la requête avec toutes les clés :
\
Autoattention à têtes multiples
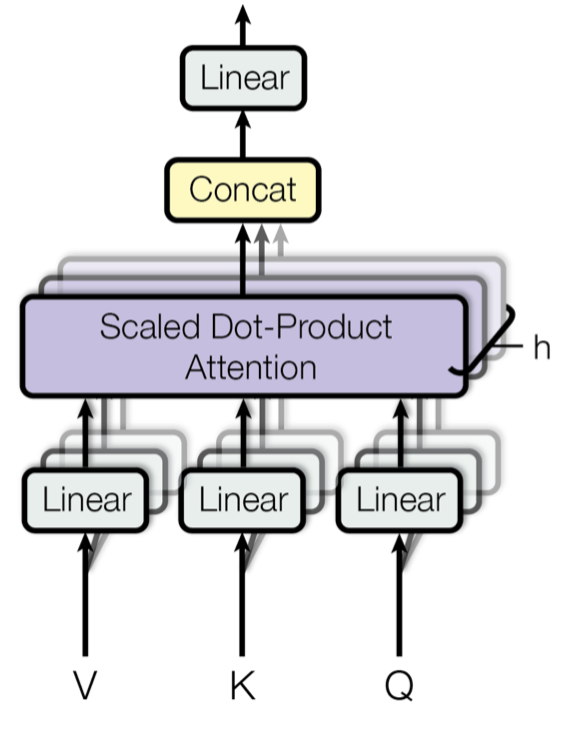
Fig. 14. Mécanisme d’attention multi-têtes à l’échelle du point-produit. (Source de l’image : Fig 2 dans Vaswani, et al., 2017)
Plutôt que de ne calculer l’attention qu’une seule fois, le mécanisme multi-têtes exécute l’attention point-produit échelonnée plusieurs fois en parallèle. Les sorties d’attention indépendantes sont simplement concaténées et transformées linéairement dans les dimensions attendues. Je suppose que la motivation est que l’assemblage est toujours utile… 😉 Selon l’article, « l’attention multi-têtes permet au modèle d’assister conjointement à des informations provenant de différents sous-espaces de représentation à différentes positions. Avec une seule tête d’attention, le calcul de la moyenne inhibe cela. »
\\\\\\N-texte{où tête}_i &= \text{Attention}(\mathbf{Q}\mathbf{W}^Q_i, \mathbf{K}\mathbf{W}^K_i, \mathbf{V}\mathbf{W}^V_i)\end{aligned}\]
où \(\mathbf{W}^Q_i\), \(\mathbf{W}^K_i\), \(\mathbf{W}^V_i\), et \(\mathbf{W}^O\) sont des matrices de paramètres à apprendre.
Encodeur
![]()
Fig. 15. L’encodeur du transformateur. (Source de l’image : Vaswani, et al, 2017)
L’encodeur génère une représentation basée sur l’attention avec la capacité de localiser un élément d’information spécifique à partir d’un contexte potentiellement infiniment grand.
- Une pile de N=6 couches identiques.
- Chaque couche a une couche d’auto-attention à têtes multiples et un simple réseau feed-forward entièrement connecté selon la position.
- Chaque sous-couche adopte une connexion résiduelle et une normalisation de couche.
Décodeur
![]()
Fig. 16. Le décodeur du transformateur. (Source de l’image : Vaswani, et al, 2017)
Le décodeur est capable de récupérer à partir de la représentation encodée.
- Un empilement de N = 6 couches identiques
- Chaque couche comporte deux sous-couches de mécanismes d’attention à têtes multiples et une sous-couche de réseau feed-forward entièrement connecté.
- Similaire à l’encodeur, chaque sous-couche adopte une connexion résiduelle et une normalisation de couche.
- La première sous-couche d’attention multi-têtes est modifiée pour empêcher les positions d’assister aux positions ultérieures, car nous ne voulons pas regarder dans le futur de la séquence cible lors de la prédiction de la position actuelle.
Architecture complète
Finalement voici la vue complète de l’architecture du transformateur:
- Les deux séquences source et cible passent d’abord par des couches d’incorporation pour produire des données de même dimension \(d_\text{model} =512\).
- Pour préserver l’information de position, un codage positionnel basé sur des ondes sinusoïdales est appliqué et additionné à la sortie d’incorporation.
- Un softmax et une couche linéaire sont ajoutés à la sortie finale du décodeur.
![]()
Fig. 17. L’architecture du modèle complet du transformateur. (Source de l’image : Fig 1 & 2 dans Vaswani, et al., 2017.)
Tenter d’implémenter le modèle du transformateur est une expérience intéressante, voici la mienne : lilianweng/transformer-tensorflow. Lisez les commentaires dans le code si vous êtes intéressés.
SNAIL
Le transformateur n’a pas de structure récurrente ou convolutive, même avec l’encodage positionnel ajouté au vecteur d’intégration, l’ordre séquentiel n’est que faiblement incorporé. Pour les problèmes sensibles à la dépendance positionnelle comme l’apprentissage par renforcement, cela peut être un gros problème.
Le Simple Neural Attention Meta-Learner (SNAIL) (Mishra et al., 2017) a été développé en partie pour résoudre le problème du positionnement dans le modèle du transformateur en combinant le mécanisme d’auto-attention du transformateur avec des convolutions temporelles. Il a été démontré qu’il est bon pour les tâches d’apprentissage supervisé et d’apprentissage par renforcement.
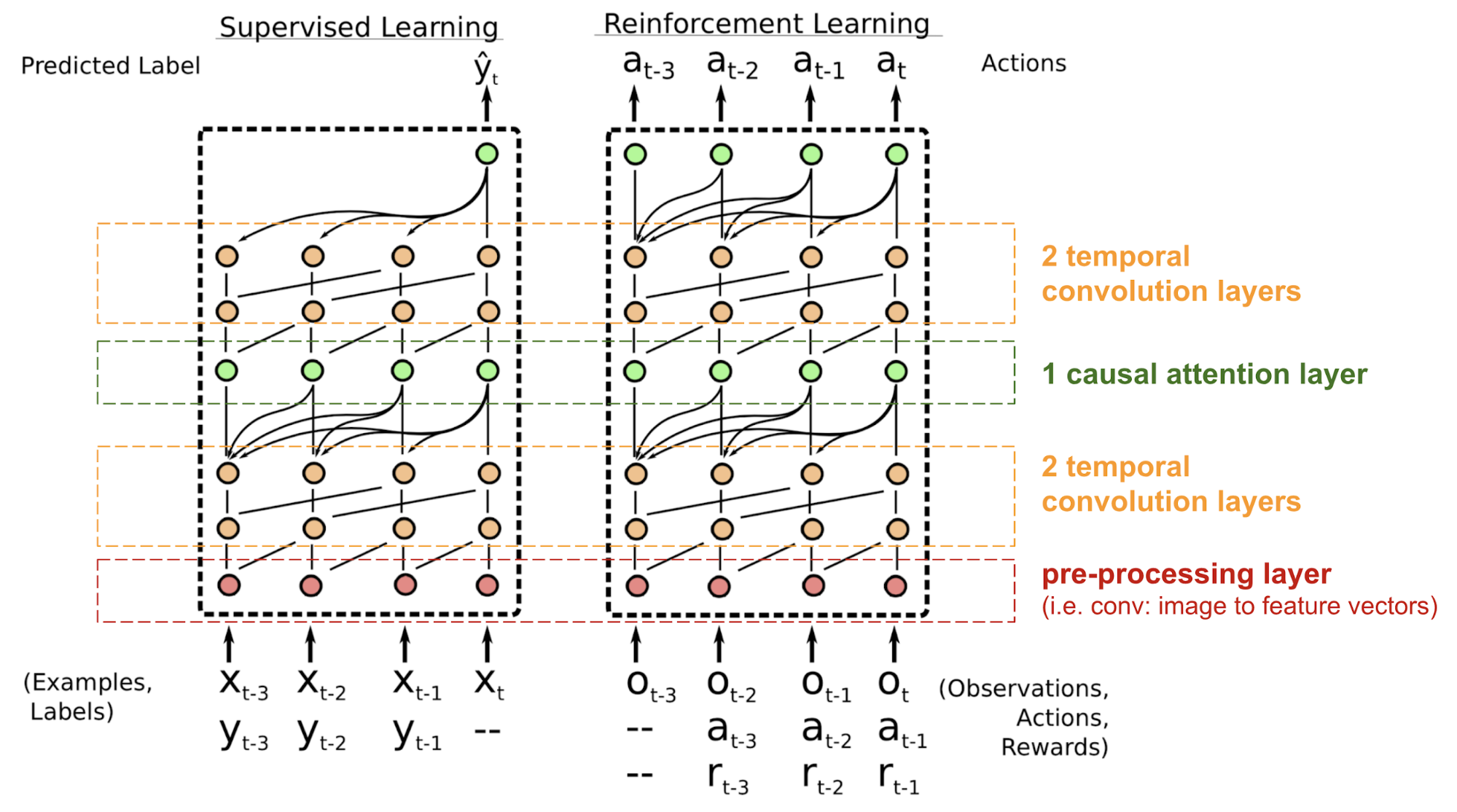
Fig. 18. Architecture du modèle SNAIL (Source d’image : Mishra et al., 2017)
SNAIL est né dans le domaine du méta-apprentissage, qui est un autre grand sujet digne d’un post à lui seul. Mais en termes simples, le modèle de méta-apprentissage est censé être généralisable à de nouvelles tâches non vues dans la distribution similaire. Lisez cette belle introduction si vous êtes intéressé.
Self-Attention GAN
Self-Attention GAN (SAGAN ; Zhang et al., 2018) ajoute des couches d’auto-attention dans le GAN pour permettre à la fois au générateur et au discriminateur de mieux modéliser les relations entre les régions spatiales.
Le DCGAN classique (Deep Convolutional GAN) représente à la fois le discriminateur et le générateur comme des réseaux convolutifs multicouches. Cependant, la capacité de représentation du réseau est limitée par la taille du filtre, car la caractéristique d’un pixel est limitée à une petite région locale. Afin de connecter des régions éloignées, les caractéristiques doivent être diluées par des couches d’opérations convolutives et le maintien des dépendances n’est pas garanti.
Comme l’auto-attention (douce) dans le contexte de la vision est conçue pour apprendre explicitement la relation entre un pixel et toutes les autres positions, même les régions éloignées, elle peut facilement capturer les dépendances globales. Par conséquent, le GAN équipé de l’auto-attention devrait mieux gérer les détails, hourra !
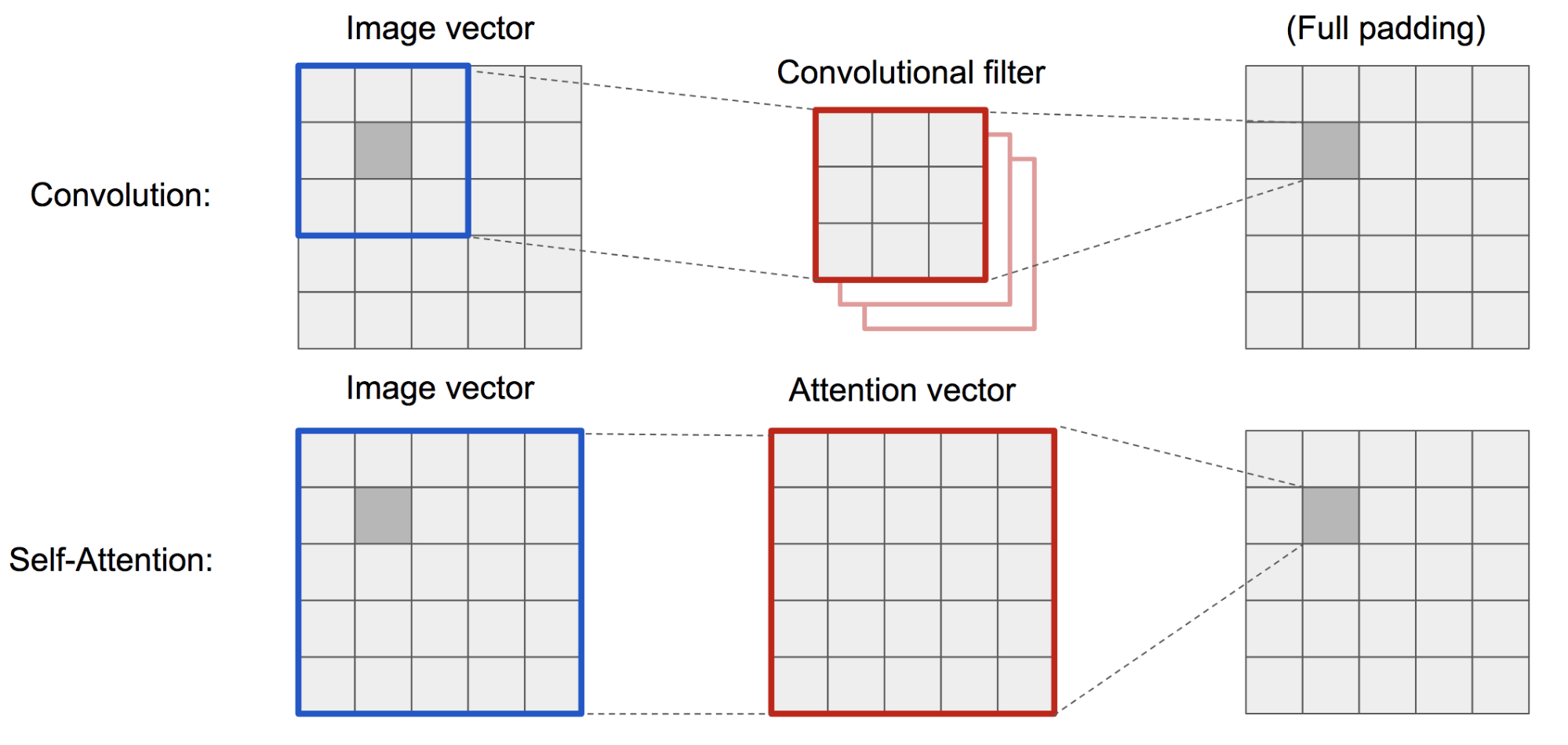
Fig. 19. L’opération de convolution et l’auto-attention ont accès à des régions de tailles très différentes.
Le SAGAN adopte le réseau neuronal non local pour appliquer le calcul de l’attention. Les cartes de caractéristiques d’image convolutives \(\mathbf{x}\) sont ramifiées en trois copies, correspondant aux concepts de clé, de valeur et de requête dans le transformateur:
- Clé : \(f(\mathbf{x}) = \mathbf{W}_f \mathbf{x}\)
- Query : \(g(\mathbf{x}) = \mathbf{W}_g \mathbf{x}\)
- Valeur : \(h(\mathbf{x}) = \mathbf{W}_h \mathbf{x}\)
Puis nous appliquons l’attention du point-produit pour sortir les cartes de caractéristiques d’auto-attention:
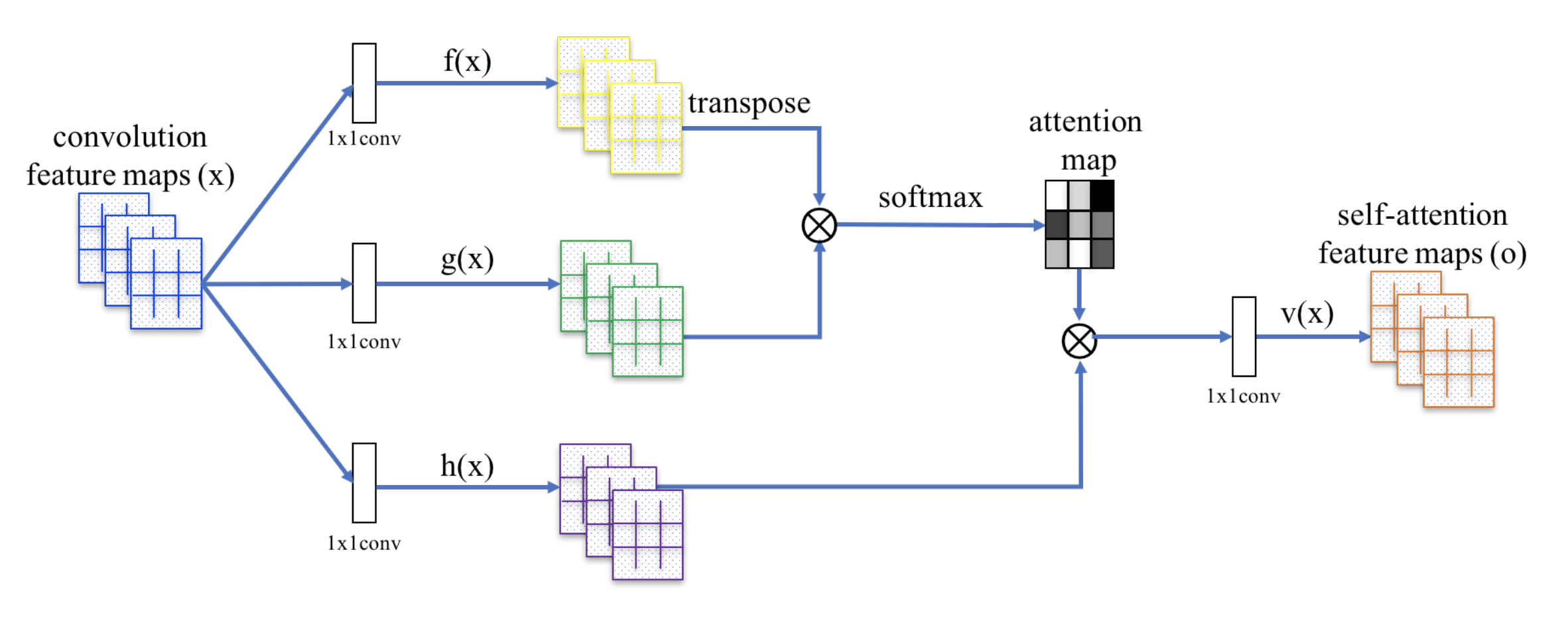
Fig. 20. Le mécanisme d’auto-attention dans SAGAN. (Source de l’image : Fig. 2 dans Zhang et al, 2018)
De plus, la sortie de la couche d’attention est multipliée par un paramètre d’échelle et ajoutée de nouveau à la carte de caractéristiques d’entrée originale:
\
Alors que le paramètre d’échelle \(\gamma\) est augmenté progressivement à partir de 0 pendant la formation, le réseau est configuré pour s’appuyer d’abord sur les indices dans les régions locales, puis apprendre progressivement à attribuer plus de poids aux régions qui sont plus éloignées.

Fig. 21. Images d’exemple 128×128 générées par SAGAN pour différentes classes. (Source de l’image : Fig. 6 partielle dans Zhang et al., 2018)
Cité comme:
Si vous remarquez des erreurs et des fautes dans ce post, n’hésitez pas à me contacter à et je serais très heureux de les corriger immédiatement!
Vous voir dans le prochain post 😀
« Attention et mémoire dans l’apprentissage profond et la PNL ». – Le 3 janvier 2016 par Denny Britz
« Tutoriel de traduction automatique neuronale (seq2seq) »
Dzmitry Bahdanau, Kyunghyun Cho, et Yoshua Bengio. « Traduction automatique neuronale par apprentissage conjoint pour aligner et traduire ». ICLR 2015.
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, et Yoshua Bengio. « Montrer, assister et raconter : Génération neuronale de légendes d’images avec attention visuelle ». ICML, 2015.
Ilya Sutskever, Oriol Vinyals, et Quoc V. Le. « Apprentissage de séquence à séquence avec des réseaux de neurones ». NIPS 2014.
Thang Luong, Hieu Pham, Christopher D. Manning. « Approches efficaces pour la traduction automatique neuronale basée sur l’attention ». EMNLP 2015.
Denny Britz, Anna Goldie, Thang Luong, et Quoc Le. « Exploration massive des architectures de traduction automatique neuronale ». ACL 2017.
Ashish Vaswani, et al. « Attention is all you need ». NIPS 2017.
Jianpeng Cheng, Li Dong, et Mirella Lapata. « Mémoire à long court terme – réseaux pour la lecture automatique ». EMNLP 2016.
Xiaolong Wang, et al. « Réseaux neuronaux non locaux ». CVPR 2018
Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, et Pieter Abbeel. « Un méta-apprenant attentif aux neurones simple ». ICLR 2018.
« WaveNet : Un modèle génératif pour l’audio brut » – 8 septembre 2016 par DeepMind.
Oriol Vinyals, Meire Fortunato, et Navdeep Jaitly. « Réseaux de pointeurs ». NIPS 2015.
Alex Graves, Greg Wayne, et Ivo Danihelka. « Machines de turing neurales », arXiv preprint arXiv:1410.5401 (2014).
.