Qui a déplacé mon 99e centile de latence ?
Co-auteur : Cuong Tran
Les latences à longue queue affectent les membres tous les jours et l’amélioration des temps de réponse des systèmes, même au 99e percentile, est essentielle pour l’expérience du membre. Il peut y avoir de nombreuses causes telles que des applications lentes, des accès lents aux disques, des erreurs dans le réseau, et bien d’autres. Nous avons rencontré une cause fondamentale du trafic de microbursting qui ne peut pas être facilement résolue par la stratégie de couverture du pari, c’est-à-dire l’envoi de la même requête à plusieurs serveurs dans l’espoir que l’un des serveurs ne sera pas impacté par les latences à longue queue. Dans ce billet suivant, nous partagerons notre méthodologie pour trouver la cause profonde des latences à longue queue, nos expériences et les leçons apprises.
Les latences réseau entre les machines d’un centre de données peuvent être faibles. En général, toutes les communications prennent quelques microsecondes, mais de temps en temps, certains paquets prennent quelques millisecondes. Les paquets qui prennent quelques millisecondes appartiennent généralement au 90e percentile ou plus des latences. Les latences de longue traîne se produisent lorsque ces percentiles élevés commencent à avoir des valeurs qui vont bien au-delà de la moyenne et peuvent être des magnitudes plus grandes que la moyenne. Ainsi, les latences moyennes ne donnent que la moitié de l’histoire. Le graphique ci-dessous montre la différence entre une bonne distribution des latences et une distribution à longue queue. Comme vous pouvez le voir, le 99e percentile est 30 fois pire que la médiane et le 99,9 percentile est 50 fois pire !
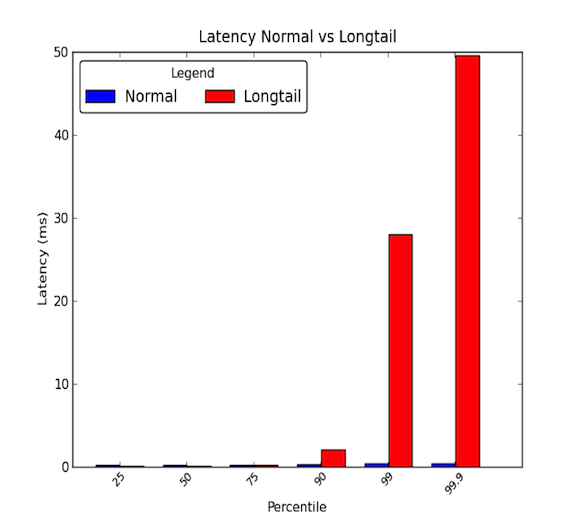
- Les longues queues ont vraiment de l’importance !
- Étude de cas
- Etape 1 : Avoir un environnement contrôlé et simplifié
- Étape 2 : Mesurer la latence de bout en bout
- Étape 3 : Éliminer et expérimenter
- Microbursts, oh my!
- Impact de la cause première
- Étape 4 : Prototype et validation
- Trouver la cause première des longues queues peut être difficile.
- Les leçons apprises
- Remerciements
Les longues queues ont vraiment de l’importance !
Une latence de 99e percentile de 30 ms signifie que chaque 1 demande sur 100 subit un retard de 30 ms. Pour un site web à fort trafic comme LinkedIn, cela pourrait signifier que pour une page avec 1 million de pages vues par jour, alors 10 000 de ces pages vues subissent le retard. Cependant, la plupart des systèmes actuels sont des systèmes distribués et une demande peut en fait créer plusieurs demandes en aval. Ainsi, une demande peut créer 2 demandes, ou 10, ou même 100 ! Si de multiples requêtes en aval frappent un seul service affecté par des latences à longue queue, notre problème devient plus effrayant.
Pour illustrer, disons que 1 requête client crée 10 requêtes en aval vers un sous-système affecté par des latences à longue queue. Et supposons qu’il a une probabilité de 1% de répondre lentement à une seule demande. Alors la probabilité qu’au moins 1 des 10 demandes en aval soit affectée par les latences de longue traîne est équivalente au complément de toutes les demandes en aval répondant rapidement (probabilité de 99% de répondre rapidement à une seule demande) qui est :

C’est 9,5 % ! Cela signifie que la demande d’un client a presque 10 % de chances d’être affectée par une réponse lente. Cela équivaut à s’attendre à ce que 100 000 demandes de clients soient affectées sur 1 million de demandes de clients. Cela fait beaucoup de membres !
Cependant, notre exemple précédent ne tient pas compte du fait que les membres actifs parcourent généralement plus d’une page et que si cet utilisateur unique fait la même demande client plusieurs fois, la probabilité que l’utilisateur soit affecté par des problèmes de latence augmente considérablement. Par conséquent, un service backend très actif affecté par des latences à longue queue peut avoir un impact sérieux sur l’ensemble du site.
Étude de cas
Nous avons récemment eu l’occasion d’enquêter sur l’un de nos systèmes distribués qui connaissait des latences réseau à longue queue. Ce problème était tapi depuis quelques mois, les enquêtes superficielles ne montrant pas de raisons évidentes pour les latences réseau à longue queue. Nous avons décidé de mener une enquête plus approfondie pour trouver la cause du problème. Dans ce billet de blog, nous voulions partager notre expérience et la méthodologie que nous avons utilisée pour identifier la cause première à travers l’étude de cas suivante.
Etape 1 : Avoir un environnement contrôlé et simplifié
Nous avons d’abord mis en place un environnement de test du système de production réel. Nous avons simplifié le système à quelques machines qui pouvaient reproduire les latences réseau à longue queue. De plus, nous avons désactivé la journalisation et les données de cache de persistance sur le disque pour éliminer le stress IO. Cela nous a permis de concentrer notre attention sur les composants clés tels que le CPU et le réseau. Nous avons également veillé à mettre en place des simulations de trafic que nous pouvions répéter afin d’avoir des tests reproductibles pendant que nous réalisions des expériences et des réglages sur les systèmes. Le diagramme ci-dessous montre notre environnement de test qui se composait d’une couche API, d’un serveur de cache et d’un petit cluster de base de données.

À un niveau élevé, les demandes des services externes arrivent dans le système distribué par une couche API. Les demandes sont ensuite adressées à un serveur cache pour répondre aux requêtes. Si les données ne sont pas dans le cache, le serveur de cache fera des demandes au cluster de base de données pour former la réponse à la requête.
Étape 2 : Mesurer la latence de bout en bout
L’étape suivante consistait à examiner les latences détaillées de bout en bout. En faisant cela, nous pouvions tenter d’isoler nos latences de longue queue et voir quel composant de notre système distribué affectait les latences que nous voyions. Au cours d’une simulation de trafic, nous avons utilisé l’utilitaire ping entre les différentes paires entre un hôte de la couche API, un hôte du serveur de cache et l’un des hôtes du cluster de base de données afin de mesurer les latences. Le tableau suivant montre les latences du 99e percentile entre la paire d’hôtes :

D’après ces mesures initiales, nous avons conclu que le serveur de cache avait le problème des latences à longue queue. Nous avons expérimenté davantage pour vérifier ces résultats et avons trouvé ce qui suit :
- Le problème majeur était les latences du 99e percentile pour le trafic entrant vers le serveur de cache.
- Les latences du 99e percentile ont été mesurées vers d’autres machines hôtes sur le même rack que le serveur cache et aucun autre hôte n’a été affecté.
- Les latences du 99e percentile ont ensuite également été mesurées avec le trafic TCP, UDP et ICMP et tout le trafic entrant vers le serveur cache a été affecté.
L’étape suivante consistait à décomposer le réseau et la pile de protocoles du serveur cache suspecté. En faisant cela, nous espérions isoler la pièce du serveur cache qui avait un impact sur les latences de la longue queue. Nos mesures de latence de ventilation de bout en bout sont présentées ci-dessous :

Nous avons effectué ces mesures en implémentant une simple application de requête/réponse UDP en C et utilisé l’horodatage fourni par le système Linux pour le trafic réseau. Vous pouvez voir un exemple dans la documentation du noyau pour les fonctionnalités de timestamping.c pour obtenir des informations détaillées sur le moment où les paquets frappent la carte d’interface réseau et les sockets. Il est également intéressant de noter que certaines cartes d’interface réseau fournissent un horodatage matériel qui vous permet d’obtenir des informations sur le moment où les paquets passent réellement par la carte d’interface réseau ; cependant, toutes les cartes ne le supportent pas. Vous pouvez consulter ce document de RedHat pour plus d’informations. Nous avons également utilisé des tcpdumps sur le système pour pouvoir voir quand les demandes/réponses sont traitées au niveau du protocole par le système d’exploitation.
Étape 3 : Éliminer et expérimenter
Après avoir identifié que le problème de latence se situait entre le matériel de la carte d’interface réseau et la couche protocole du système d’exploitation, nous nous sommes fortement concentrés sur ces parties du système. Puisque la carte d’interface réseau (NIC) aurait pu être un problème possible, nous avons décidé de l’examiner en premier et de remonter la pile pour éliminer les différentes couches. En examinant chaque composant, nous avons gardé à l’esprit les éléments suivants : Equité, Contentions, et Saturation. Ces trois domaines clés permettent de trouver les goulots d’étranglement potentiels ou les problèmes de latence.
- Équité : Les entités du système reçoivent-elles leur part équitable de temps ou de ressources pour traiter ou terminer ? Par exemple, chaque application sur un système reçoit-elle une quantité équitable de temps d’exécution sur les CPU pour compléter leurs tâches ? Si ce n’est pas le cas, l’iniquité ou l’équité pose-t-elle un problème ? Par exemple, peut-être qu’une application hautement prioritaire devrait être favorisée par rapport aux autres ; la vidéo en temps réel nécessite plus de temps de traitement qu’une tâche d’arrière-plan qui vous permet de sauvegarder des fichiers sur un service de cloud.
- Contentions : Les entités du système se battent-elles pour la même ressource ? Par exemple, si deux applications écrivent sur un seul disque dur, les deux applications doivent se disputer la bande passante du disque. Ceci est fortement lié à l’équité puisque les contentions doivent être résolues par une sorte d’algorithme d’équité. Les contestations peuvent être plus faciles à rechercher au lieu d’une question d’équité.
- Saturation : Une ressource est-elle surutilisée ou complètement utilisée ? Si une ressource est surutilisée ou complètement utilisée, nous pouvons atteindre une certaine limitation qui crée des contentions ou des retards car les entités doivent faire la queue pour utiliser les ressources au fur et à mesure qu’elles deviennent disponibles.
Lorsque nous nous sommes attaqués à la NIC, nous nous sommes principalement attachés à regarder a) si les files d’attente débordaient, ce qui se traduirait par des rejets et indiquerait d’éventuelles limitations de l’utilisation de la bande passante ou b) s’il y avait des paquets malformés nécessitant des retransmissions, ce qui pourrait provoquer des retards. Il y avait 0 rejets et 0 paquets malformés frappant la NIC pendant nos expériences et notre utilisation de la bande passante était à peu près de 5 à 40 Mo/s, ce qui est faible sur notre matériel de 1 Gbps.
Puis, nous nous sommes concentrés sur le niveau du pilote et du protocole. Ces deux parties étaient difficiles à séparer ; cependant, nous avons passé une bonne partie de notre enquête à examiner les différents réglages du système d’exploitation qui traitaient de l’ordonnancement des processus, de l’utilisation des ressources pour les cœurs, de la gestion des interruptions d’ordonnancement et de l’affinité des interruptions pour les utilisations des cœurs. Ces domaines clés pouvaient potentiellement causer des retards dans le traitement des paquets réseau et nous voulions nous assurer que les demandes et les réponses étaient traitées aussi rapidement que la machine pouvait le faire. Malheureusement, la plupart de nos expérimentations n’ont donné aucune cause fondamentale.
Les symptômes que nous avons vus au début semblaient impliquer un système limité en bande passante. Lorsque beaucoup de trafic est produit, les latences augmentent en raison des délais de mise en file d’attente. Pourtant, lorsque nous avons examiné la couche NIC, nous n’avons pas vu un tel problème. Mais après avoir éliminé presque tout ce qui se trouvait dans la pile, nous avons réalisé que nos mesures de performance se mesurent en granularités de 1 seconde ou 1 000 millisecondes. Avec une latence de longue queue de 30 ms, comment pouvions-nous espérer attraper le problème ?
Microbursts, oh my!
Plusieurs de nos systèmes ont des cartes d’interface réseau de 1 Gbps. Lorsque nous avons examiné le trafic entrant, nous avons vu que le serveur Cache subissait généralement un trafic de 5 à 40 Mo/s. Ce type d’utilisation de la bande passante ne soulève pas d’inquiétude, mais que se passe-t-il si nous examinons l’utilisation de la bande passante par milliseconde ? Le premier graphique ci-dessous est celui de l’utilisation de la bande passante par seconde et montre une faible utilisation, tandis que le second graphique est celui de l’utilisation de la bande passante par milliseconde et montre une histoire complètement différente.

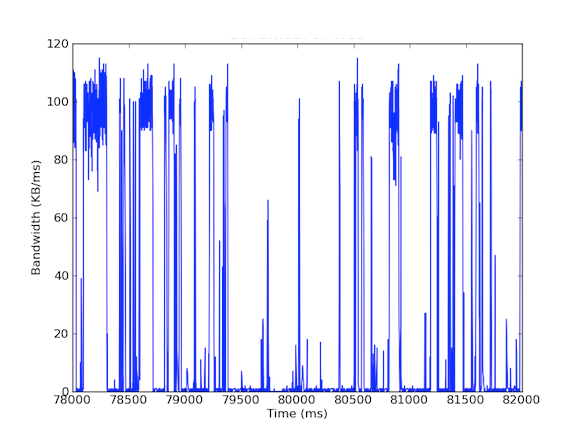
Pour mesurer le trafic de la bande passante entrante par milliseconde, nous avons utilisé tcpdump pour rassembler le trafic pendant une période de temps définie. Cela a nécessité des calculs hors ligne, mais comme les tcpdump ont des timestamps au niveau de la microseconde, nous avons pu calculer l’utilisation de la bande passante entrante par milliseconde. Grâce à ces mesures, nous avons pu identifier la cause des latences réseau à longue queue. Comme vous pouvez le voir dans les graphiques ci-dessus, l’utilisation de la bande passante par milliseconde montre de brèves rafales de quelques centaines de millisecondes à la fois qui atteignent près de 100 kB/ms. Un tel taux de 100 kB/ms maintenu pendant une seconde entière équivaudrait à 100 Mo/s, soit 80 % de la capacité théorique des cartes d’interface réseau de 1 Gbps ! Ces rafales sont connues sous le nom de microrafales et sont créées par le cluster de bases de données distribuées qui répond au serveur de cache en une seule fois, créant ainsi un lien entièrement utilisé pendant une durée inférieure à une seconde. Vous trouverez ci-dessous un graphique de l’utilisation de la bande passante en pourcentage des vitesses de 1 Gbps par rapport aux latences mesurées pendant la même période. Comme vous pouvez le voir, il existe une forte corrélation entre les pics de latence et le trafic en rafale :
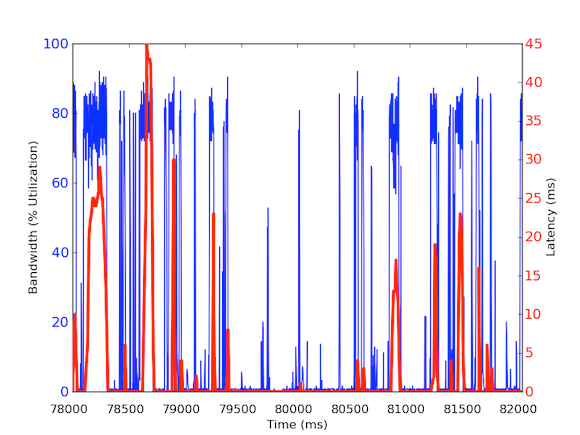
Ces graphiques montrent l’importance des mesures en sous-secondes ! Bien qu’il soit difficile de maintenir une infrastructure complète avec de telles données, au moins pour les enquêtes approfondies, cela devrait être une granularité de go to car dans la performance, les millisecondes comptent vraiment !
Impact de la cause première
Cette cause première a un effet intéressant sur notre système distribué. Généralement, les systèmes aiment les hauts débits, donc avoir une utilisation extrêmement élevée est une bonne chose. Mais notre serveur de mise en cache traite deux types de trafic : (1) les données à haut débit de la base de données (2) les petites requêtes de la couche API. Il est vrai que les requêtes de la couche API peuvent être à l’origine du haut débit de données de la base de données, mais voici la clé : elles ne sont nécessaires que lorsque la requête ne peut être satisfaite par le cache. Si la demande est dans le cache, le serveur de mise en cache devrait renvoyer les données rapidement sans avoir à attendre les calculs de la base de données. Mais que se passe-t-il si une demande en cache arrive pendant un microburst de réponse pour une demande sans cache ? Le microburst peut causer 30 ms de retard à tout autre trafic entrant et, par conséquent, la requête mise en cache pourrait subir un retard supplémentaire de 30 ms qui n’est absolument pas nécessaire !
Étape 4 : Prototype et validation
Une fois que nous avons découvert une cause première plausible, nous avons voulu valider nos résultats. Comme cette utilisation de la bande passante en rafale peut causer des retards dans les hits du cache, nous pouvions isoler ces demandes des requêtes du serveur de cache vers le cluster de base de données. Pour ce faire, nous avons mis en place un environnement expérimental dans lequel un seul hôte de serveur de cache dispose de deux NIC, chacune avec sa propre adresse IP. Avec cette configuration, toutes les demandes de la couche API vers le serveur de cache passent par une interface et toutes les requêtes du serveur de cache vers le cluster de base de données passent par l’autre interface. Le diagramme ci-dessous illustre cela :

Avec cette configuration, nous avons mesuré les latences suivantes et comme vous pouvez le voir, les latences entre la couche API et le serveur de cache sont en fait ce que nous attendons – saines et inférieures à 1 ms. Les latences avec le cluster de base de données ne peuvent pas être évitées sans améliorer le matériel ; parce que nous voulons maximiser le débit, les rafales vont toujours se produire et donc les paquets seront mis en file d’attente à l’interface.

Par conséquent, le trafic différent mérite des priorités différentes et peut être une solution idéale pour gérer le trafic de micro-rafales. D’autres solutions incluent l’amélioration du matériel comme l’utilisation de matériel 10 Gbps, la compression des données ou même l’utilisation de la qualité de service.
Trouver la cause première des longues queues peut être difficile.
La cause première des latences des longues queues peut être difficile à trouver, car elles sont éphémères et peuvent échapper aux mesures de performance. La plupart des mesures de performance que nous recueillons ici à LinkedIn sont à des granularités de 1 seconde et certaines à 1 minute. Toutefois, si l’on met cela en perspective, des latences de longue durée (30 ms) peuvent facilement échapper à des mesures dont la granularité est de 1 000 ms (1 seconde). De plus, les latences à longue queue peuvent être dues à différents problèmes matériels ou logiciels et il peut être assez difficile de trouver la cause profonde dans un système distribué complexe. Certains exemples de causes peuvent être l’utilisation des ressources matérielles traitant de l’équité, de la contention et de la saturation, ou des problèmes de modèle de données tels que des distributions multi-nodales ou des utilisateurs puissants causant des latences à longue queue pour leurs charges de travail.
Pour résumer, nous encourageons fortement à se souvenir de ces quatre étapes de notre méthodologie pour de futures enquêtes :
- Ayez un environnement contrôlé et simplifié.
- Avoir des mesures détaillées de latence de bout en bout.
- Eliminer et expérimenter.
- Prototype et validation.
Les leçons apprises
- La latence de longue traîne n’est pas seulement du bruit ! Elle peut être due à différentes raisons réelles et les demandes du 99e percentile peuvent affecter le reste d’un grand système distribué.
- N’écartez pas le 99e percentile des problèmes de latence en tant qu’utilisateurs puissants ; à mesure que les utilisateurs puissants se multiplient, les problèmes se multiplient aussi.
- Couvrir son pari bien qu’il s’agisse d’une stratégie généralement bonne où le système envoie la même requête deux fois dans l’espoir d’une réponse rapide n’aide pas lorsque les latences à longue queue sont induites par l’application. En fait, cela ne fait qu’empirer le système en ajoutant plus de trafic au système qui, dans notre cas, provoquerait plus de microrafales. Si nous avions mis en œuvre cette stratégie sans une analyse approfondie, nous aurions été déçus car les performances du système auraient été dégradées et cela aurait fait perdre beaucoup d’efforts pour mettre en œuvre une telle solution.
- Les approches de dispersion/rassemblement peuvent facilement provoquer des microbursts d’utilisation de la bande passante, provoquant des délais de mise en file d’attente à la granularité de la milliseconde.
- Des mesures de granularité sub-seconde sont nécessaires.
- Parfois, les améliorations matérielles sont le moyen le plus rentable d’aider à atténuer les problèmes, mais d’ici là, il y a encore des atténuations intéressantes que les développeurs peuvent faire, comme compresser les données ou être sélectif sur les données envoyées ou utilisées.
Enfin, la leçon la plus importante que nous avons apprise est de suivre la méthodologie. Les méthodologies donnent une direction aux enquêtes, en particulier lorsque les choses deviennent confuses ou commencent à ressembler à un voyage à travers la Terre du Milieu.
Remerciements
Je tiens à remercier Andrew Carter pour son travail et sa collaboration au cours de l’enquête et Steven Callister pour son soutien opérationnel et ses commentaires. Merci également à Badri Sridharan, Haricharan Ramachandra, Ritesh Maheshwari et Zhenyun Zhuang pour leurs commentaires et suggestions sur cet écrit.