Who moved my 99th percentth percentile latency?
Co-author: Cuong Tran
A hosszú késleltetési idők minden nap hatással vannak a tagokra, és a rendszerek válaszidejének javítása még a 99. percentilisnél is kritikus fontosságú a tagok élménye szempontjából. Ennek számos oka lehet, például lassú alkalmazások, lassú lemezelérések, hálózati hibák és még sok más. Találkoztunk a microbursting forgalom olyan kiváltó okával, amelyet nem lehet könnyen megoldani a hedging your bet stratégiával, azaz ugyanazt a kérést több szerverre küldeni abban a reményben, hogy az egyik szerverre nem lesz hatással a hosszú késleltetési idő. A következő bejegyzésben megosztjuk a longtail késleltetések gyökeres okának feltárására szolgáló módszertanunkat, tapasztalatainkat és tanulságainkat.
Az adatközponton belüli gépek közötti hálózati késleltetések alacsonyak lehetnek. Általában minden kommunikáció néhány mikromásodpercig tart, de időnként előfordul, hogy néhány csomag néhány ezredmásodpercig tart. A néhány ezredmásodpercig tartó csomagok általában a késleltetési idő 90. percentiliséhez vagy annál magasabb értékéhez tartoznak. A longtail késleltetések akkor fordulnak elő, amikor ezek a magas percentilisek az átlagot jóval meghaladó értékeket vesznek fel, és akár nagyságrendekkel nagyobbak is lehetnek az átlagnál. Az átlagos késleltetési idők tehát csak a történet felét mutatják. Az alábbi grafikon mutatja a különbséget a jó és a hosszúfarkú késleltetési eloszlás között. Mint látható, a 99. percentilis 30-szor rosszabb, mint a medián, a 99,9 percentilis pedig 50-szer rosszabb!
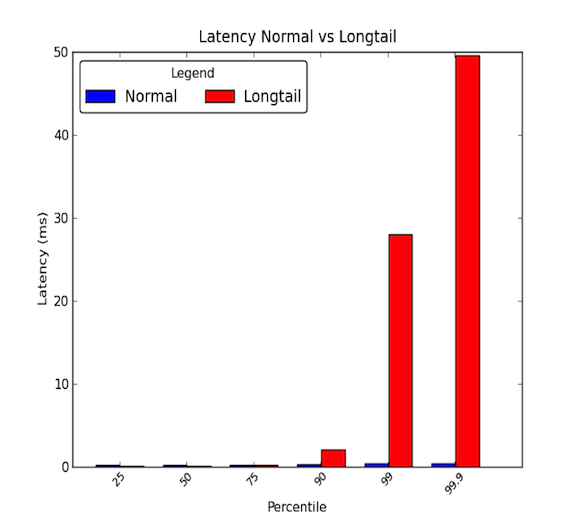
- A hosszúfarkúak tényleg számítanak!
- Egy esettanulmány
- 1. lépés: Ellenőrzött és egyszerűsített környezet
- 2. lépés: Végponttól-végpontig tartó késleltetés mérése
- 3. lépés: Megszüntetés és kísérletezés
- Mikrokitörések, ó, te jó ég!
- A gyökér ok hatása
- 4. lépés: Prototípus és validálás
- A hosszú késleltetések gyökerének megtalálása nehéz lehet.
- Tanulságok
- Köszönet
A hosszúfarkúak tényleg számítanak!
A 30 ms-os 99. percentilis késleltetés azt jelenti, hogy 100 kérésből minden 1. kérés 30 ms késést tapasztal. Egy olyan nagy forgalmú weboldal esetében, mint a LinkedIn, ez azt jelentheti, hogy egy napi 1 millió oldalletöltést produkáló oldal esetében ezek közül 10 000-nél jelentkezik a késés. Manapság azonban a legtöbb rendszer elosztott rendszer, és 1 kérés valójában több későbbi kérést is létrehozhat. Tehát 1 kérés létrehozhat 2 kérést, vagy 10-et, vagy akár 100-at is! Ha több downstream kérés ér egyetlen, hosszú késleltetéssel érintett szolgáltatást, a problémánk ijesztőbbé válik.
Az illusztráció kedvéért tegyük fel, hogy 1 ügyfélkérés 10 downstream kérést hoz létre egy hosszú késleltetéssel érintett alrendszerhez. És tegyük fel, hogy 1%-os valószínűséggel lassan válaszol egyetlen kérésre. Ekkor annak a valószínűsége, hogy a 10 downstream kérésből legalább 1-et érint a longtail késleltetés, megegyezik az összes downstream kérés gyors válaszadásának komplementerével (99%-os valószínűséggel bármelyik kérésre gyorsan válaszol), ami:

Ez 9,5%! Ez azt jelenti, hogy 1 ügyfélkérésre közel 10 százalék az esélye annak, hogy lassú válasz érkezik. Ez egyenértékű azzal, mintha 1 millió ügyfélkérésből 100 000 ügyfélkérés érintettségére számítanánk. Ez nagyon sok tag!
Az előző példánk azonban nem veszi figyelembe, hogy az aktív tagok általában egynél több oldalt böngésznek, és ha egyetlen felhasználó többször is ugyanazt az ügyfélkérést teszi, drámaian megnő annak a valószínűsége, hogy a felhasználót késleltetési problémák érintik. Ezért egy nagyon aktív backend-szolgáltatás, amelyet hosszú késleltetési késleltetések érintenek, komoly hatással lehet az egész webhelyre.
Egy esettanulmány
A közelmúltban volt alkalmunk megvizsgálni az egyik elosztott rendszerünket, amelynél hosszú hálózati késleltetési késleltetéseket tapasztaltunk. Ez a probléma már néhány hónapja lappangott, és a felületes vizsgálatok nem mutatták ki a hosszú hálózati késleltetések nyilvánvaló okait. Úgy döntöttünk, hogy alaposabban megvizsgáljuk a probléma okát. Ebben a blogbejegyzésben az alábbi esettanulmányon keresztül szerettük volna megosztani tapasztalatainkat és módszertanunkat, amelyet a kiváltó ok azonosításához használtunk.
1. lépés: Ellenőrzött és egyszerűsített környezet
Először létrehoztunk egy tesztkörnyezetet a tényleges termelési rendszerről. A rendszert leegyszerűsítettük néhány gépre, amelyekkel reprodukálni tudtuk a hosszú távú hálózati késleltetéseket. Továbbá kikapcsoltuk a naplózást és a perzisztencia cache-adatokat a lemezen, hogy kiküszöböljük az IO-stresszt. Ez lehetővé tette, hogy figyelmünket a kulcsfontosságú összetevőkre, például a CPU-ra és a hálózatra összpontosítsuk. Arra is ügyeltünk, hogy szimulált forgalmi futtatásokat állítsunk be, amelyeket meg tudtunk ismételni, hogy reprodukálható teszteket végezhessünk, miközben kísérleteket és hangolásokat végeztünk a rendszereken. Az alábbi ábra a tesztkörnyezetünket mutatja, amely egy API-rétegből, egy gyorsítótár-kiszolgálóból és egy kis adatbázis-klaszterből állt.

Felső szinten a külső szolgáltatásokból érkező kérések egy API-rétegen keresztül érkeznek az elosztott rendszerbe. A lekérdezések ezután egy gyorsítótár-kiszolgálóhoz érkeznek a lekérdezések teljesítése érdekében. Ha az adatok nincsenek a gyorsítótárban, akkor a gyorsítótár-kiszolgáló kéréseket intéz az adatbázis-klaszterhez a lekérdezési válasz kialakításához.
2. lépés: Végponttól-végpontig tartó késleltetés mérése
A következő lépés a részletes végponttól-végpontig tartó késleltetések vizsgálata volt. Ezzel megkísérelhettük elkülöníteni a hosszúfarkú késleltetéseket, és megnézhettük, hogy az elosztott rendszerünk melyik összetevője befolyásolja a tapasztalt késleltetéseket. Egy szimulált forgalmi futtatás során a ping segédprogramot használtuk egy API-réteg hoszt, egy gyorsítótár-kiszolgáló hoszt és az egyik adatbázis-klaszter hoszt közötti különböző párok között, hogy megmérjük a késleltetéseket. Az alábbiakban a 99. percentilis késleltetések láthatók a hosztpárok között:

Ezekből a kezdeti mérésekből arra következtettünk, hogy a gyorsítótár-kiszolgálónál van a hosszú késleltetési probléma. További kísérleteket végeztünk ezen eredmények ellenőrzésére, és a következőket találtuk:
- A fő probléma a 99. percentilis késleltetési idő volt a gyorsítótár-kiszolgáló felé irányuló bejövő forgalomban.
- A 99. percentilis késleltetési időt a gyorsítótár-kiszolgálóval azonos rackben lévő más állomásgépek felé mértük, és más állomás nem volt érintett.
- 99. percentilis késleltetési idő ezután TCP, UDP és ICMP forgalommal is mérésre került, és a gyorsítótár-kiszolgáló felé irányuló összes bejövő forgalom érintett volt.
A következő lépés a gyanúsított gyorsítótár-kiszolgáló hálózatának és protokollkötegének lebontása volt. Ezzel reméltük, hogy elszigetelhetjük a gyorsítótár-kiszolgálónak azt a részét, amely hatással volt a hosszú távú késleltetésekre. A végponttól végpontig tartó bontási késleltetési méréseinket az alábbiakban mutatjuk be:

A méréseket egy egyszerű UDP kérés-válasz alkalmazás C nyelven történő implementálásával végeztük, és a hálózati forgalomhoz a Linux rendszer által biztosított időbélyegzést használtuk. A kernel dokumentációjában a timestamping.c fájlban található egy példa a funkciókhoz, hogy részletes információt kapjunk arról, hogy a csomagok mikor érkeztek a hálózati interfész kártyára és a foglalatokra. Érdemes megjegyezni azt is, hogy néhány hálózati csatolókártya hardveres időbélyegzést biztosít, amely lehetővé teszi, hogy információt kapjunk arról, hogy a csomagok ténylegesen mikor haladnak át a hálózati csatolókártyán; azonban nem minden kártya támogatja ezt. További információért lásd ezt a RedHat által készített dokumentumot. A tcpdumps-ot is használtuk a rendszeren, hogy láthassuk, mikor dolgozza fel a kéréseket/válaszokat protokollszinten az operációs rendszer.
3. lépés: Megszüntetés és kísérletezés
Miután azonosítottuk, hogy a késleltetési probléma a hálózati csatolókártya hardvere és az operációs rendszer protokollrétege között van, erősen koncentráltunk a rendszer ezen részeire. Mivel a hálózati csatolókártya (NIC) lehetett a lehetséges probléma, úgy döntöttünk, hogy először azt vizsgáljuk meg, és a veremben felfelé haladva kiküszöböljük a különböző rétegeket. Az egyes komponensek vizsgálata során a következőket tartottuk szem előtt: Tisztesség, tartalom és telítettség. Ez a három kulcsfontosságú terület segít megtalálni a lehetséges szűk keresztmetszeteket vagy késleltetési problémákat.
- Fairness: A rendszerben lévő entitások megkapják-e a feldolgozáshoz vagy befejezéshez szükséges idő vagy erőforrások méltányos részét? Például, a rendszerben minden alkalmazás méltányos mennyiségű időt kap a CPU-kon a feladatai elvégzéséhez? Ha nem, akkor az igazságtalanság vagy a méltányosság okoz-e problémát? Például lehet, hogy egy magas prioritású alkalmazást előnyben kell részesíteni a többivel szemben; a valós idejű videók feldolgozása több időt igényel, mint egy olyan háttérfeladaté, amely lehetővé teszi a fájlok biztonsági mentését egy felhőszolgáltatásba.
- Tartalmak: A rendszerben lévő entitások harcolnak ugyanazért az erőforrásért? Ha például két alkalmazás ír egy merevlemezre, mindkét alkalmazásnak meg kell küzdenie a meghajtó sávszélességéért. Ez erősen kapcsolódik a méltányossághoz, mivel a vitákat valamilyen méltányossági algoritmussal kell megoldani. A méltányossági kérdés helyett könnyebb lehet a tartalmat keresni.
- Telítettség: Egy erőforrás túlterhelt vagy teljesen ki van használva? Ha egy erőforrás túlterhelt vagy teljesen ki van használva, előfordulhat, hogy valamilyen korlátozásba ütközünk, ami vitákat vagy késéseket okoz, mivel az entitásoknak sorba kell állniuk, hogy használhassák az erőforrásokat, amint azok elérhetővé válnak.
Amikor a hálózati kártyával foglalkoztunk, főként arra összpontosítottunk, hogy megnézzük, a) túlcsordulnak-e a sorok, ami elutasításként jelentkezik, és esetleges sávszélesség-használati korlátokra utal, vagy b) vannak-e rosszul formált csomagok, amelyek újratovábbításra szorulnak, ami késedelmeket okozhat. Kísérleteink során 0 selejtes és 0 rosszul formázott csomag érkezett a hálózati kártyára, és a sávszélesség-használat nagyjából 5-40 MB/s volt, ami alacsony az 1 Gbps-os hardverünkön.
A következő lépésben az illesztőprogram és a protokoll szintjére összpontosítottunk. Ezt a két részt nehéz volt szétválasztani; vizsgálatunk jó részét azonban azzal töltöttük, hogy különböző operációs rendszerhangolásokat vizsgáltunk, amelyek a folyamatok ütemezésével, a magok erőforrás-kihasználtságával, a megszakítások kezelésének ütemezésével és a magok kihasználtságának megszakítási affinitásával foglalkoztak. Ezek a kulcsfontosságú területek potenciálisan késedelmet okozhatnak a hálózati csomagok feldolgozásában, és meg akartunk győződni arról, hogy a kérések és válaszok kiszolgálása olyan gyorsan történik, amilyen gyorsan a gép képes kezelni. Sajnos a legtöbb kísérletünk nem vezetett eredményre.
A kezdetben tapasztalt tünetek sávszélesség-korlátozott rendszerre utaltak. Amikor nagy forgalom keletkezik, a késleltetések megnövekednek a sorban állási késleltetések miatt. Mégis, amikor a hálózati kártyaréteget vizsgáltuk, nem láttunk ilyen problémát. Miután azonban szinte mindent kiiktattunk a veremből, rájöttünk, hogy a teljesítményméréseink 1 másodperces vagy 1000 milliszekundumos granularitásban mérnek. Egy 30 ms hosszú késleltetéssel hogyan is remélhettük volna, hogy észrevesszük a problémát?
Mikrokitörések, ó, te jó ég!
Számos rendszereinkben 1 Gbps-os hálózati csatolókártyák vannak. Amikor megnéztük a bejövő forgalmat, azt láttuk, hogy a Cache Server általában 5 – 40 MB/s forgalmat tapasztalt. Ez a fajta sávszélesség-használat nem vet fel semmilyen vészjelzést; mi van azonban, ha a sávszélesség-használatot milliszekundumonként nézzük! Az alábbi első grafikon a sávszélesség másodpercenkénti használatát mutatja, és alacsony használatot mutat, míg a második grafikon a sávszélesség ezredmásodpercenkénti használatát mutatja, és teljesen mást mutat.

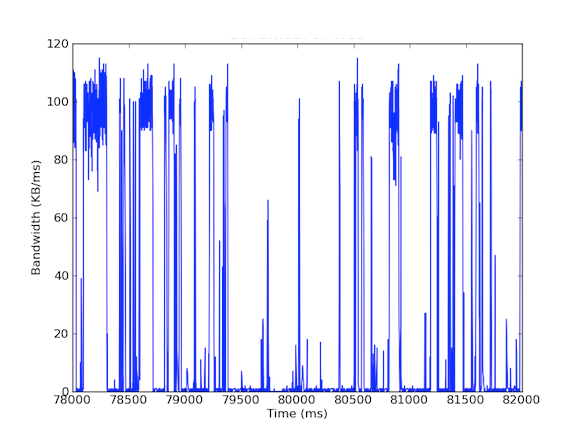
A milliszekundumonkénti bejövő sávszélesség-forgalom méréséhez a tcpdump segítségével gyűjtöttük össze a forgalmat egy meghatározott időtartamra. Ehhez offline számításokra volt szükség, de mivel a tcpdumps mikroszekundumos szintű időbélyegzőkkel rendelkezik, ki tudtuk számítani a bejövő sávszélesség-használatot milliszekundumonként. Ezekkel a mérésekkel azonosítani tudtuk a hosszú távú hálózati késleltetések okát. Amint a fenti grafikonokon látható, a milliszekundumonkénti sávszélesség-felhasználás rövid, néhány száz milliszekundumos kitöréseket mutat, amelyek megközelítik a 100 kB/ms értéket. Egy ilyen 100 kB/ms-os sebesség egy teljes másodpercig fenntartva 100 MB/s-nak felel meg, ami az 1 Gbps-os hálózati csatolókártyák elméleti kapacitásának 80%-a! Ezeket a kitöréseket mikrokitöréseknek nevezzük, és az elosztott adatbázis-fürt egyszerre válaszol a gyorsítótár-kiszolgálónak, így egy másodperc alatti időre teljesen kihasznált kapcsolatot hoz létre. Az alábbiakban egy grafikon mutatja a sávszélesség kihasználtságát az 1 Gbps sebesség százalékos arányában az ugyanezen időszak alatt mért késleltetésekkel szemben. Mint látható, a késleltetési tüskék és a kiugró forgalom között magas korreláció van:
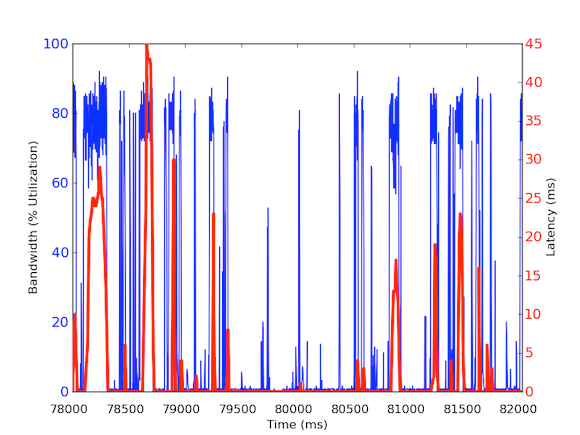
Ezek a grafikonok jól mutatják a másodperc alatti mérések fontosságát! Bár nehéz egy teljes infrastruktúrát fenntartani ilyen adatokkal, legalábbis a mélyreható vizsgálatokhoz ez kellene, hogy legyen a go to granularitás, mert a teljesítményben az ezredmásodpercek tényleg számítanak!
A gyökér ok hatása
Ez a gyökér ok érdekes hatással van az elosztott rendszerünkre. Általában a rendszerek szeretik a nagy áteresztőképességet, ezért a rendkívül magas kihasználtság jó dolog. A mi caching szerverünk azonban kétféle forgalommal foglalkozik: (1) nagy áteresztőképességű adatok az adatbázisból (2) kisebb lekérdezések az API rétegből. Igaz, az API réteg kérései okozhatják a nagy áteresztőképességű adatokat az adatbázisból, de itt van a kulcs: csak akkor van rá szükség, ha a kérést a gyorsítótár nem tudja teljesíteni. Ha a kérés a gyorsítótárban van, a gyorsítótár-kiszolgálónak gyorsan vissza kell adnia az adatokat anélkül, hogy az adatbázis számításaira várnia kellene. De mi történik akkor, ha egy gyorsítótárban tárolt kérés egy nem gyorsítótárban tárolt kérésre adott mikrokitöréses válasz közben érkezik? A mikrokitörés 30 ms késedelmet okozhat bármely más bejövő forgalomban, és ezért a gyorsítótárazott kérés további 30 ms késedelmet tapasztalhat, ami teljesen felesleges!
4. lépés: Prototípus és validálás
Mihelyt felfedeztük a valószínűsíthető kiváltó okot, validálni akartuk az eredményeinket. Mivel ez a kiugró sávszélesség-használat késéseket okozhat a gyorsítótár találatoknál, ezeket a kéréseket el tudtuk különíteni a gyorsítótár-kiszolgáló adatbázis-klaszterhez intézett lekérdezéseitől. Ennek érdekében létrehoztunk egy kísérleti környezetet, ahol egyetlen gyorsítótár-kiszolgáló host két NIC-vel rendelkezik, mindkettő saját IP-címmel. Ezzel a beállítással a gyorsítótár-kiszolgálóhoz intézett összes API-rétegű kérés az egyik interfészen, a gyorsítótár-kiszolgálónak az adatbázis-fürthöz intézett összes lekérdezése pedig a másik interfészen keresztül történik. Az alábbi diagram ezt szemlélteti:

Ezzel a beállítással a következő késleltetéseket mértük, és mint látható, az API-réteg és a gyorsítótár-kiszolgáló közötti késleltetések valójában megfelelnek az elvárásainknak – egészségesek és 1 ms alatt vannak. A késleltetések az adatbázis-klaszterrel nem kerülhetők el jobb hardver nélkül; mivel maximalizálni akarjuk az áteresztőképességet, mindig lesznek kitörések, és így a csomagok sorba kerülnek az interfészen.

Ezért a különböző forgalom különböző prioritásokat érdemel, és ideális megoldás lehet a mikrokitörések kezelésére. További megoldások közé tartozik a hardver javítása, például 10 Gbps-os hardver használata, az adatok tömörítése, vagy akár a szolgáltatásminőség használata.
A hosszú késleltetések gyökerének megtalálása nehéz lehet.
A hosszú késleltetések gyökerét nehéz megtalálni, mivel azok efemer jellegűek és elkerülik a teljesítményméréseket. A legtöbb teljesítménymérés, amelyet itt a LinkedIn-nél gyűjtünk, 1 másodperces, néhány pedig 1 perces granularitású. Ezt figyelembe véve azonban a 30 ms-ig tartó hosszú késleltetések könnyen elkerülhetik a figyelmet az akár 1000 ms-os (1 másodperces) granularitású méréseknél. Nem csak ez, de a hosszú késleltetések különböző hardver- vagy szoftverproblémákból is adódhatnak, és egy összetett elosztott rendszerben elég nehéz lehet megtalálni a kiváltó okokat. Néhány példa az okokra lehet a méltányossággal, versengéssel és telítettséggel foglalkozó hardvererőforrás-használat, vagy adatmintázati problémák, például a több csomópontos eloszlások vagy a teljesítményfelhasználók, amelyek hosszú késleltetési időt okoznak a munkaterhelésüknek.
Összefoglalva, erősen javasoljuk, hogy a jövőbeli vizsgálatokhoz emlékezzünk a módszertanunk e négy lépésére:
- Vezérelt és egyszerűsített környezet.
- Végezzünk részletes végponttól végpontig tartó késleltetési méréseket.
- Vezessük ki és kísérletezzünk.
- Prototípusok készítése és validálás.
Tanulságok
- A hosszúfarkú késleltetés nem csak zaj! Különböző valós okokra vezethető vissza, és a 99. percentilis kérések hatással lehetnek egy nagy elosztott rendszer többi részére.
- Ne hagyjuk figyelmen kívül a késleltetési problémák 99. percentilisét, mint power usereket; ahogy a power userek szaporodnak, úgy szaporodnak a problémák is.
- A hedging your bet bár általában jó stratégia, amikor a rendszer kétszer küldi ugyanazt a kérést egy gyors válasz reményében, nem segít, ha a hosszúfarkú késleltetések az alkalmazás okoztaak. Valójában csak ront a rendszeren azzal, hogy több forgalmat ad a rendszernek, ami a mi esetünkben több mikrokitörést okozna. Ha ezt a stratégiát alapos elemzés nélkül hajtottuk volna végre, akkor csalódnunk kellett volna, mert a rendszer teljesítménye romlott volna, és jelentős mennyiségű erőfeszítést pazaroltunk volna egy ilyen megoldás megvalósítására.
- A szórás/gyűjtés megközelítések könnyen okozhatnak mikrokitöréseket a sávszélesség-használatban, ami milliszekundumos nagyságrendű várakozási késedelmeket okoz.
- Szükség van másodperc alatti granularitású mérésekre.
- Néha a hardverfejlesztések jelentik a legköltséghatékonyabb megoldást a problémák enyhítésére, de addig is vannak érdekes enyhítési lehetőségek, amelyeket a fejlesztők tehetnek, például az adatok tömörítése vagy az adatok küldésének vagy felhasználásának szelektálása.
Végezetül a legfontosabb lecke, amit megtanultunk, a módszertan követése volt. A módszertanok irányt adnak a vizsgálatoknak, különösen akkor, amikor a dolgok zavarossá válnak, vagy kezdik úgy érezni magukat, mint egy Középföldei utazás.
Köszönet
Szeretnék köszönetet mondani Andrew Carternek a vizsgálat során végzett munkájáért és együttműködéséért, valamint Steven Callisternek az operatív támogatásért és a visszajelzésekért. Köszönöm továbbá Badri Sridharannak, Haricharan Ramachandrának, Ritesh Maheshwarinak és Zhenyun Zhuangnak az írással kapcsolatos visszajelzéseiket és javaslataikat.