Attenzione? Attenzione!
L’attenzione è stata un concetto abbastanza popolare e uno strumento utile nella comunità del deep learning negli ultimi anni. In questo post, esamineremo come è stata inventata l’attenzione, e vari meccanismi e modelli di attenzione, come il trasformatore e SNAIL.
L’attenzione è, in qualche misura, motivata da come prestiamo attenzione visiva a diverse regioni di un’immagine o correliamo le parole in una frase. Prendiamo come esempio l’immagine di uno Shiba Inu nella Fig. 1.

Fig. 1. Uno Shiba Inu in tenuta da uomo. Il merito della foto originale va a Instagram @mensweardog.
L’attenzione visiva umana ci permette di concentrarci su una certa regione con “alta risoluzione” (cioè guardare l’orecchio a punta nel riquadro giallo) mentre percepiamo l’immagine circostante in “bassa risoluzione” (cioè ora che ne dici dello sfondo innevato e del vestito?), e poi regolare il punto focale o fare l’inferenza di conseguenza. Dato un piccolo pezzo di un’immagine, i pixel nel resto forniscono indizi su cosa dovrebbe essere visualizzato lì. Ci aspettiamo di vedere un orecchio a punta nella casella gialla perché abbiamo visto il naso di un cane, un altro orecchio a punta sulla destra, e gli occhi misteriosi di Shiba (roba nelle caselle rosse). Tuttavia, il maglione e la coperta in basso non sarebbero così utili come quelle caratteristiche canine.
Similmente, possiamo spiegare la relazione tra le parole in una frase o in un contesto stretto. Quando vediamo “mangiare”, ci aspettiamo di incontrare molto presto una parola di cibo. Il termine colore descrive il cibo, ma probabilmente non così tanto con “mangiare” direttamente.
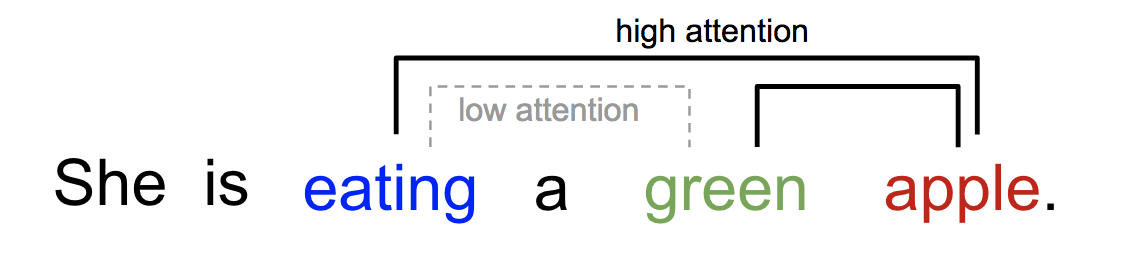
Fig. 2. Una parola “frequenta” in modo diverso altre parole nella stessa frase.
In poche parole, l’attenzione nel deep learning può essere ampiamente interpretata come un vettore di pesi di importanza: per predire o inferire un elemento, come un pixel in un’immagine o una parola in una frase, stimiamo usando il vettore di attenzione quanto fortemente è correlato con (o “frequenta” come avrete letto in molti articoli) altri elementi e prendiamo la somma dei loro valori pesati dal vettore di attenzione come approssimazione del target.
- Cosa c’è di sbagliato nel modello Seq2Seq?
- Nato per la traduzione
- Definizione
- Una famiglia di meccanismi di attenzione
- Sommario
- Self-Attention
- Soft vs Hard Attention
- Global vs Local Attention
- Neural Turing Machines
- Lettura e scrittura
- Meccanismi di attenzione
- Pointer Network
- Transformer
- Key, Value and Query
- Multi-Head Self-Attention
- Encoder
- Decoder
- Architettura completa
- SNAIL
- Self-Attention GAN
Cosa c’è di sbagliato nel modello Seq2Seq?
Il modello seq2seq è nato nel campo della modellazione del linguaggio (Sutskever, et al. 2014). A grandi linee, esso mira a trasformare una sequenza di input (source) in una nuova (target) ed entrambe le sequenze possono essere di lunghezza arbitraria. Esempi di compiti di trasformazione includono la traduzione automatica tra più lingue sia in testo che in audio, la generazione di dialoghi domanda-risposta, o anche il parsing di frasi in alberi grammaticali.
Il modello seq2seq ha normalmente un’architettura encoder-decoder, composta da:
- Un encoder elabora la sequenza di input e comprime le informazioni in un vettore di contesto (noto anche come sentence embedding o vettore “pensiero”) di una lunghezza fissa. Ci si aspetta che questa rappresentazione sia un buon riassunto del significato dell’intera sequenza sorgente.
- Un decodificatore è inizializzato con il vettore di contesto per emettere l’output trasformato. I primi lavori usavano solo l’ultimo stato della rete di codifica come stato iniziale del decoder.
Sia il codificatore che il decodificatore sono reti neurali ricorrenti, cioè usano unità LSTM o GRU.
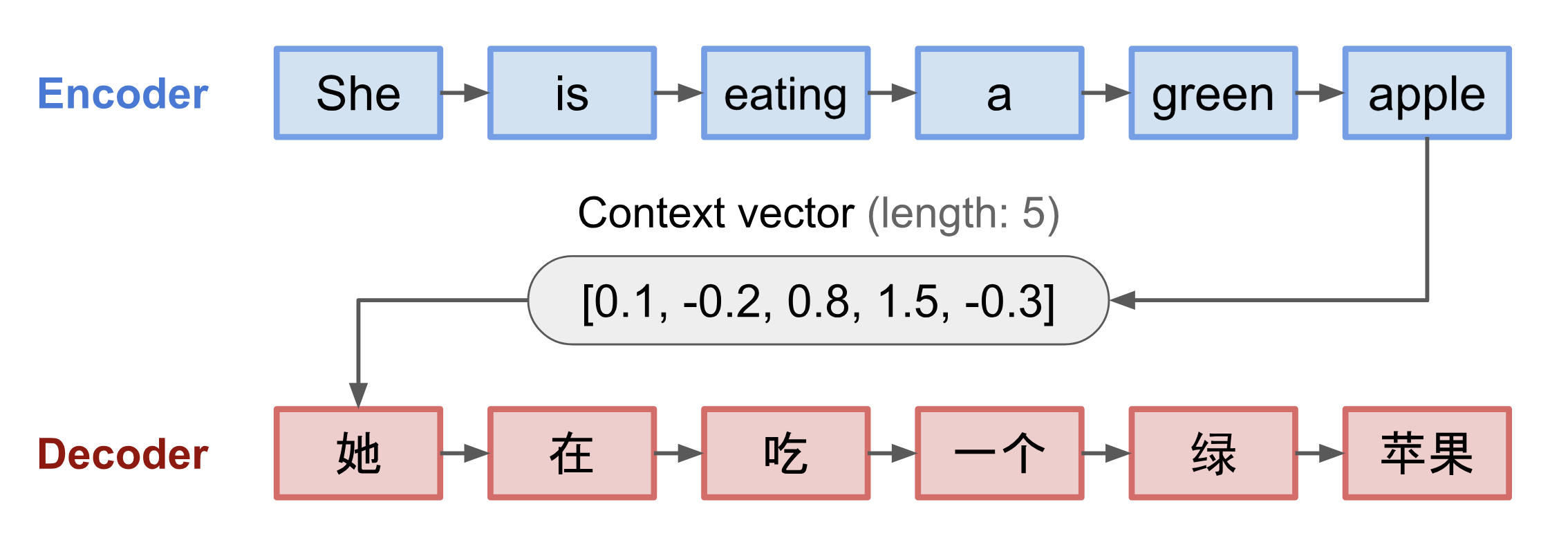
Fig. 3. Il modello encoder-decoder che traduce la frase “lei sta mangiando una mela verde” in cinese. La visualizzazione sia del codificatore che del decodificatore è srotolata nel tempo.
Uno svantaggio critico e apparente di questo progetto di vettore di contesto a lunghezza fissa è l’incapacità di ricordare frasi lunghe. Spesso ha dimenticato la prima parte una volta che ha completato l’elaborazione dell’intero input. Il meccanismo di attenzione è nato (Bahdanau et al., 2015) per risolvere questo problema.
Nato per la traduzione
Il meccanismo di attenzione è nato per aiutare a memorizzare lunghe frasi sorgente nella traduzione automatica neurale (NMT). Piuttosto che costruire un singolo vettore di contesto dall’ultimo stato nascosto del codificatore, la salsa segreta inventata dall’attenzione è quella di creare collegamenti tra il vettore di contesto e l’intero input sorgente. I pesi di queste connessioni di collegamento sono personalizzabili per ogni elemento di uscita.
Mentre il vettore di contesto ha accesso all’intera sequenza di ingresso, non dobbiamo preoccuparci di dimenticare. L’allineamento tra sorgente e destinazione è appreso e controllato dal vettore di contesto. Essenzialmente il vettore di contesto consuma tre informazioni:
- stati nascosti del codificatore;
- stati nascosti del decodificatore;
- allineamento tra sorgente e destinazione.
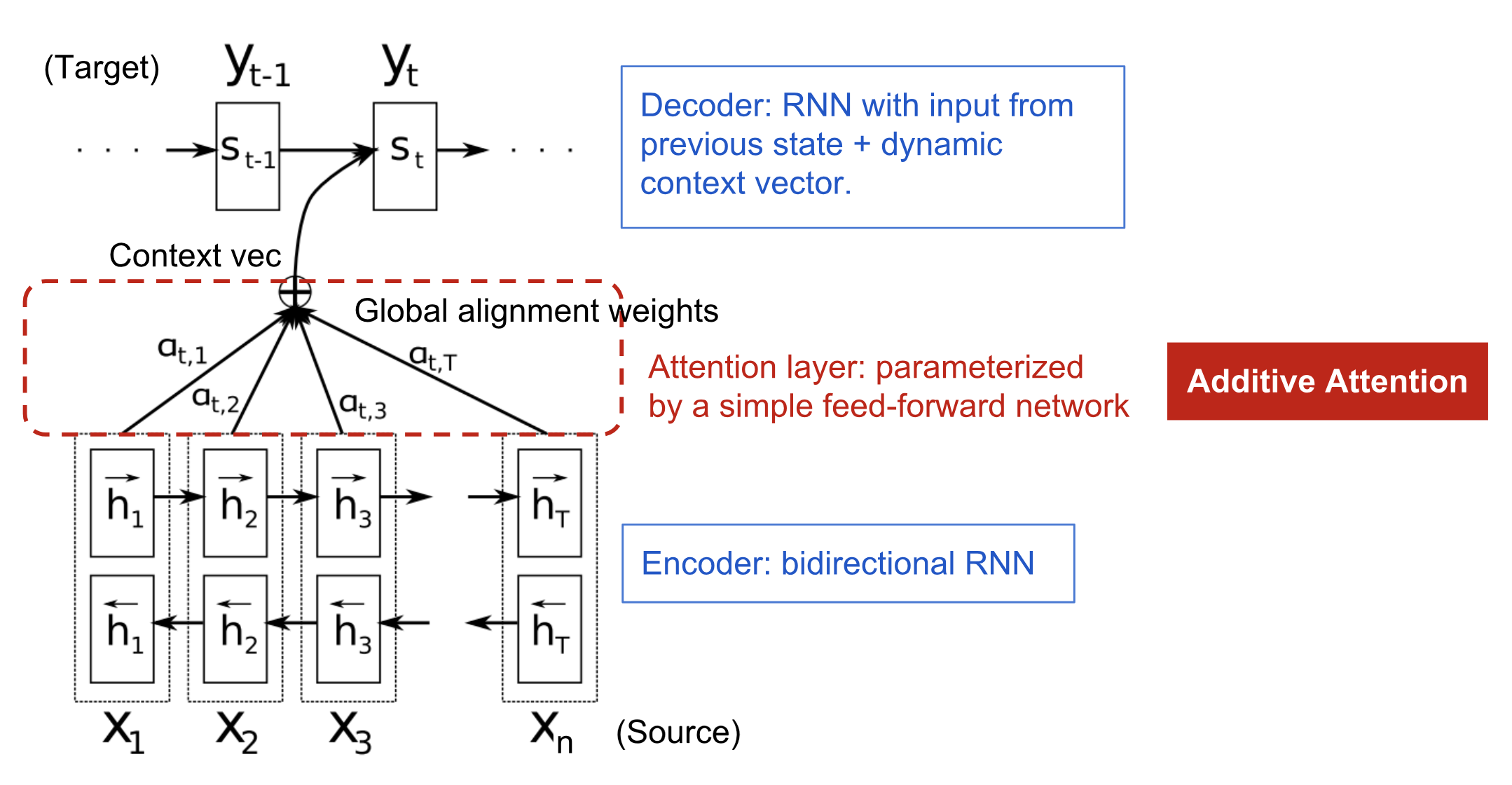
Fig. 4. Il modello encoder-decoder con meccanismo di attenzione additiva in Bahdanau et al., 2015.
Definizione
\mathbf{y} &= \end{aligned}]
(Le variabili in grassetto indicano che sono vettori; lo stesso per tutto il resto in questo post.)
Il codificatore è una RNN bidirezionale (o un’altra impostazione di rete ricorrente di vostra scelta) con uno stato nascosto in avanti \(\overrightarrow{\boldsymbol{h}}_i\) e uno indietro \(\overleftarrow{\boldsymbol{h}}_i\). Una semplice concatenazione di due rappresenta lo stato del codificatore. La motivazione è quella di includere sia le parole precedenti che quelle successive nell’annotazione di una parola.
^\top, i=1,\punti,n]\\)\]
dove sia \(\mathbf{v}_a\) che \(\mathbf{W}_a\) sono matrici di peso da imparare nel modello di allineamento.
La matrice dei punteggi di allineamento è un bel sottoprodotto per mostrare esplicitamente la correlazione tra parole di origine e di destinazione.

Fig. 5. Matrice di allineamento di “L’accord sur l’Espace économique européen a été signé en août 1992” (francese) e la sua traduzione inglese “The agreement on the European Economic Area was signed in August 1992”. (Fonte dell’immagine: Fig 3 in Bahdanau et al., 2015)
Guarda questo bel tutorial del team di Tensorflow per ulteriori istruzioni di implementazione.
Una famiglia di meccanismi di attenzione
Con l’aiuto dell’attenzione, le dipendenze tra sequenze sorgente e target non sono più limitate dalla distanza in-between! Dato il grande miglioramento dell’attenzione nella traduzione automatica, essa si è presto estesa al campo della computer vision (Xu et al. 2015) e le persone hanno iniziato a esplorare varie altre forme di meccanismi di attenzione (Luong, et al., 2015; Britz et al., 2017; Vaswani, et al, 2017).
Sommario
Di seguito è riportata una tabella riassuntiva di diversi meccanismi di attenzione popolari e delle corrispondenti funzioni di punteggio di allineamento:
Ecco una sintesi di categorie più ampie di meccanismi di attenzione:
| Nome | Definizione | Citazione |
|---|---|---|
| Self-Attention(&) | Relazione di diverse posizioni della stessa sequenza di input. Teoricamente l’auto-attenzione può adottare qualsiasi funzione di punteggio di cui sopra, ma basta sostituire la sequenza di destinazione con la stessa sequenza di input. | Cheng2016 |
| Globale/Soft | Attenzione all’intero spazio di stato di input. | Xu2015 |
| Local/Hard | Attendendo alla parte dello spazio di stato di input; cioè una patch dell’immagine di input. | Xu2015; Luong2015 |
(&) Anche, indicato come “intra-attenzione” in Cheng et al, 2016 e in alcuni altri lavori.
Self-Attention
L’autoattenzione, nota anche come intra-attenzione, è un meccanismo di attenzione che mette in relazione diverse posizioni di una singola sequenza per calcolare una rappresentazione della stessa sequenza. È stato dimostrato che è molto utile nella lettura automatica, nel riassunto astrattivo o nella generazione di descrizioni di immagini.
Il documento sulla rete di memoria a breve termine ha usato l’autoattenzione per fare la lettura automatica. Nell’esempio qui sotto, il meccanismo di auto-attenzione ci permette di imparare la correlazione tra le parole correnti e la parte precedente della frase.

Fig. 6. La parola corrente è in rosso e la dimensione dell’ombra blu indica il livello di attivazione. (Fonte immagine: Cheng et al., 2016)
Soft vs Hard Attention
Nel documento show, attend and tell, il meccanismo di attenzione viene applicato alle immagini per generare didascalie. L’immagine viene prima codificata da una CNN per estrarre le caratteristiche. Poi un decodificatore LSTM consuma le caratteristiche di convoluzione per produrre parole descrittive una per una, dove i pesi sono appresi attraverso l’attenzione. La visualizzazione dei pesi di attenzione dimostra chiaramente a quali regioni dell’immagine il modello presta attenzione per produrre una certa parola.

Fig. 7. “Una donna sta lanciando un frisbee in un parco”. (Fonte dell’immagine: Fig. 6(b) in Xu et al. 2015)
Questo articolo ha proposto per la prima volta la distinzione tra attenzione “soft” vs “hard”, in base al fatto che l’attenzione abbia accesso all’intera immagine o solo a una patch:
- Soft Attention: i pesi di allineamento vengono appresi e posizionati “softly” su tutte le patch dell’immagine sorgente; essenzialmente lo stesso tipo di attenzione di Bahdanau et al., 2015.
- Pro: il modello è liscio e differenziabile.
- Contro: costoso quando l’input di origine è grande.
- Hard Attention: seleziona solo una patch dell’immagine a cui partecipare alla volta.
- Pro: meno calcoli al momento dell’inferenza.
- Contro: il modello non è differenziabile e richiede tecniche più complicate come la riduzione della varianza o il reinforcement learning per allenarsi. (Luong, et al., 2015)
Global vs Local Attention
Luong, et al., 2015 hanno proposto l’attenzione “globale” e “locale”. L’attenzione globale è simile all’attenzione soft, mentre quella locale è un’interessante miscela tra hard e soft, un miglioramento rispetto all’attenzione hard per renderla differenziabile: il modello predice prima una singola posizione allineata per la parola target corrente e una finestra centrata intorno alla posizione della fonte viene poi utilizzata per calcolare un vettore di contesto.
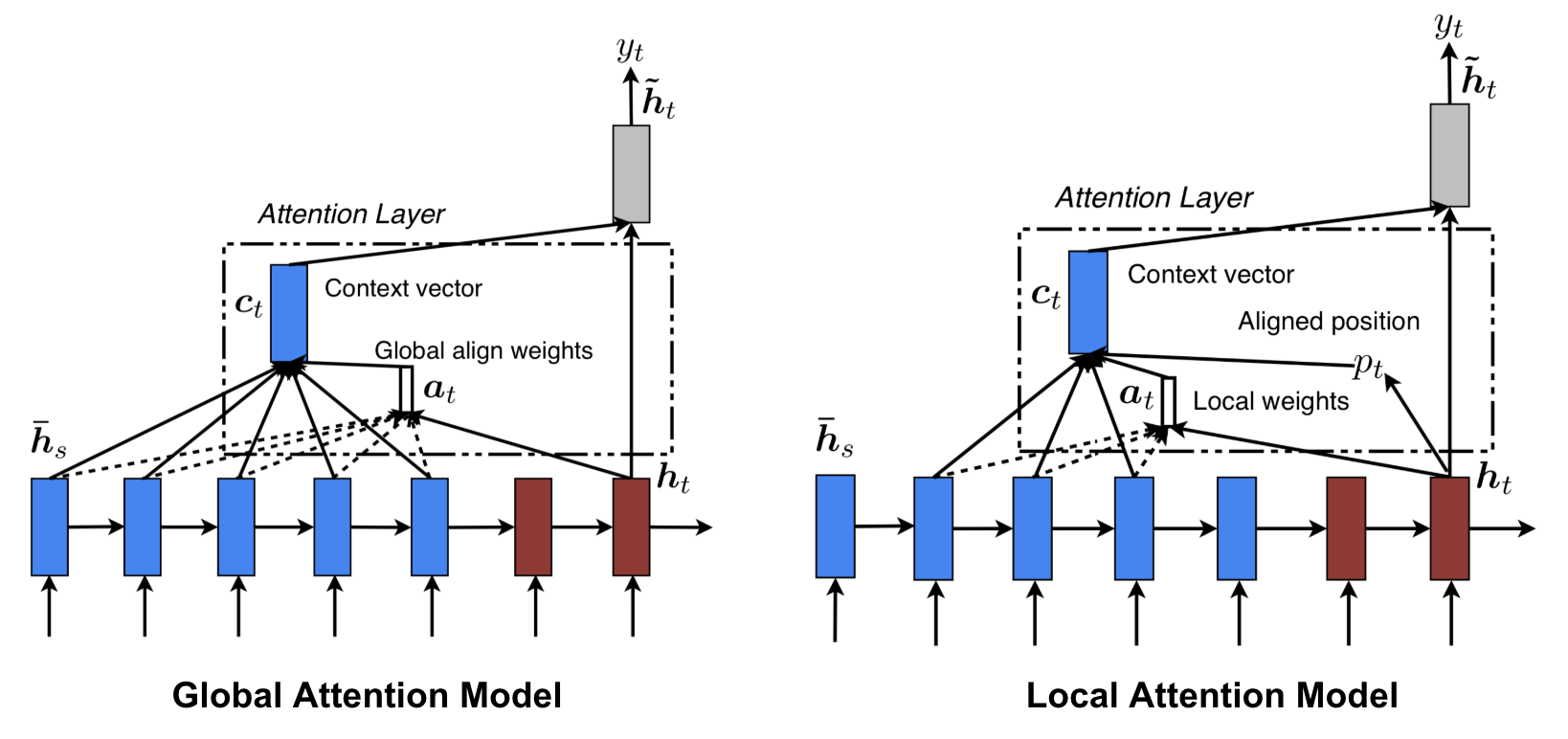
Fig. 8. Global vs local attention (Fonte immagine: Fig 2 & 3 in Luong, et al., 2015)
Neural Turing Machines
Alan Turing nel 1936 propose un modello minimalista di calcolo. È composto da un nastro infinitamente lungo e da una testa che interagisce con il nastro. Il nastro ha innumerevoli celle su di esso, ognuna riempita con un simbolo: 0, 1 o vuoto (” “). La testa operativa può leggere simboli, modificare simboli e muoversi a sinistra/destra sul nastro. Teoricamente una macchina di Turing può simulare qualsiasi algoritmo del computer, indipendentemente da quanto complessa o costosa possa essere la procedura. La memoria infinita dà ad una macchina di Turing il vantaggio di essere matematicamente illimitata. Tuttavia, la memoria infinita non è fattibile nei reali computer moderni e quindi consideriamo la macchina di Turing solo come un modello matematico di computazione.

Fig. 9. Come appare una macchina di Turing: un nastro + una testa che gestisce il nastro. (Fonte immagine: http://aturingmachine.com/)
Neural Turing Machine (NTM, Graves, Wayne & Danihelka, 2014) è un modello di architettura per l’accoppiamento di una rete neurale con una memoria esterna. La memoria imita il nastro della macchina di Turing e la rete neurale controlla le testine di operazione per leggere da o scrivere sul nastro. Tuttavia, la memoria in NTM è finita, e quindi probabilmente assomiglia di più a una “Neural von Neumann Machine”.
NTM contiene due componenti principali, una rete neurale controller e un banco di memoria. Controllore: è incaricato dell’esecuzione delle operazioni sulla memoria. Può essere qualsiasi tipo di rete neurale, feed-forward o ricorrente.Memoria: memorizza le informazioni elaborate. È una matrice di dimensioni \(N \volte M\), contenente N righe vettoriali e ciascuna ha \(M\) dimensioni.
In una iterazione di aggiornamento, il controllore elabora l’input e interagisce con il banco di memoria di conseguenza per generare l’output. L’interazione è gestita da un insieme di testate di lettura e scrittura parallele. Sia le operazioni di lettura che quelle di scrittura sono “sfocate”, assistendo dolcemente a tutti gli indirizzi di memoria.
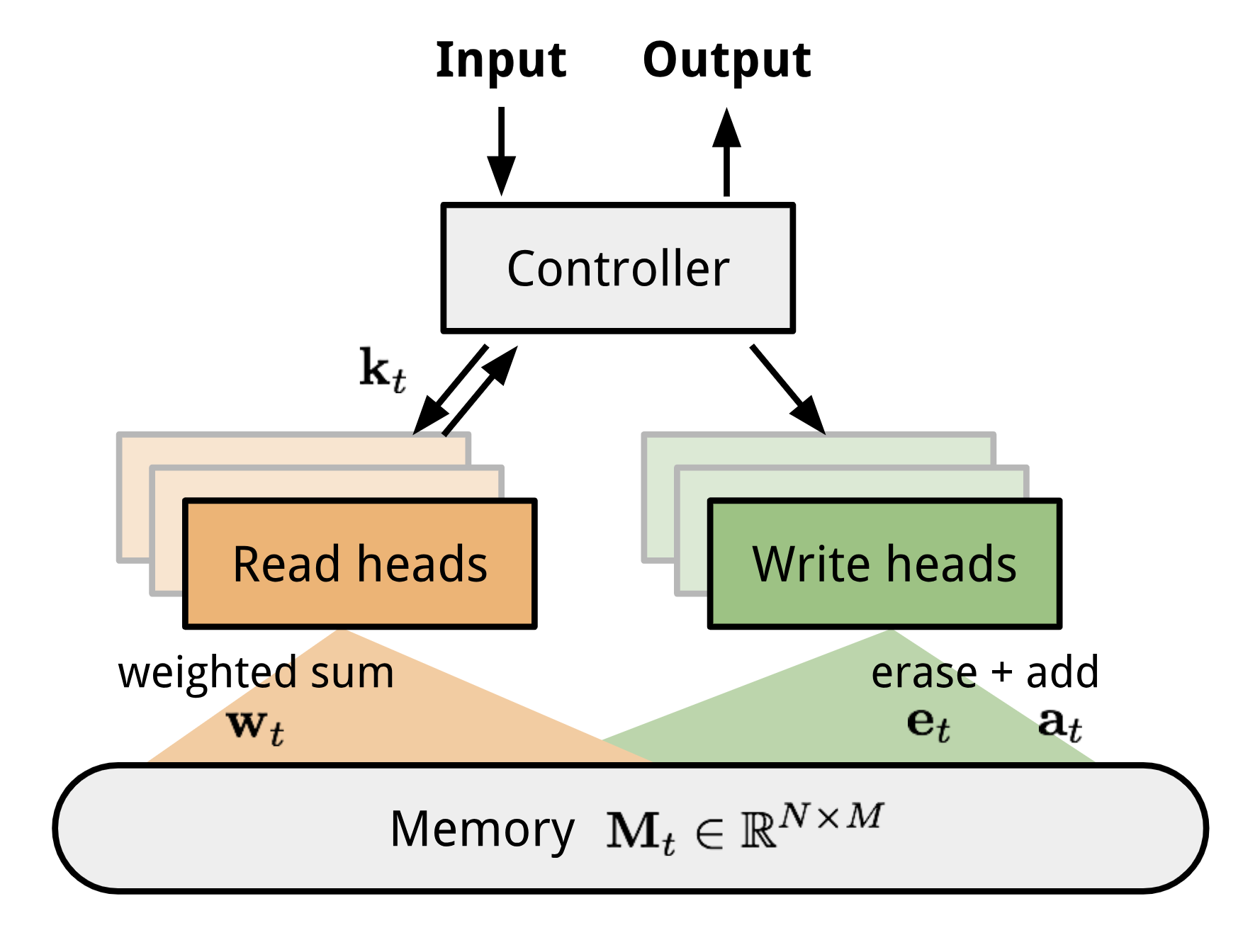
Fig 10. Architettura della macchina di Turing Neurale.
Lettura e scrittura
\
dove \(w_t(i)\) è l’\(i)-esimo elemento in \(\mathbf{w}_t\) e \(\mathbf{M}_t(i)\) è l’\(i)-esimo vettore di riga nella memoria.
\9038> \scriptstyle{\testo{; erase}}\mathbf{M}_t(i) &= \tilde{mathbf{M}}_t(i) + w_t(i) \mathbf{a}_t &{scriptstyle{\testo{; add}}{aligned}]
Meccanismi di attenzione
Nella Macchina di Turing Neurale, il modo di generare la distribuzione dell’attenzione \(\mathbf{w}_t\) dipende dai meccanismi di indirizzamento: NTM usa un misto di indirizzamento basato sul contenuto e basato sulla localizzazione.
L’indirizzamento basato sul contenuto crea vettori di attenzione basati sulla somiglianza tra il vettore chiave \(\mathbf{k}_t\) estratto dal controllore dalle righe di input e di memoria. I punteggi di attenzione basati sul contenuto sono calcolati come similarità coseno e poi normalizzati da softmax. Inoltre, NTM aggiunge un moltiplicatore di forza \(\beta_t\) per amplificare o attenuare l’attenzione della distribuzione.
\)= \frac{exp(\beta_t \frac{mathbf{k}_t \cdot \mathbf{M}_t(i)}{mathbf{k}_t \cdot \mathbf{M}_t(i)\sum_{j=1}^N \exp(\beta_t \frac{mathbf{k}_t \cdot
Interpolazione
Poi viene usato un gate scalare di interpolazione \(g_t\) per fondere il vettore di attenzione basato sul contenuto appena generato con i pesi di attenzione.basato sul contenuto con i pesi di attenzione nell’ultimo passo temporale:
Si sommano i valori in diverse posizioni nel vettore di attenzione, ponderati da una distribuzione di pesi sugli spostamenti interi consentiti. È equivalente a una convoluzione 1-d con un kernel \(\mathbf{s}t(.)\), una funzione dell’offset di posizione. Ci sono molti modi per definire questa distribuzione. Vedi la Fig. 11. per ispirazione.
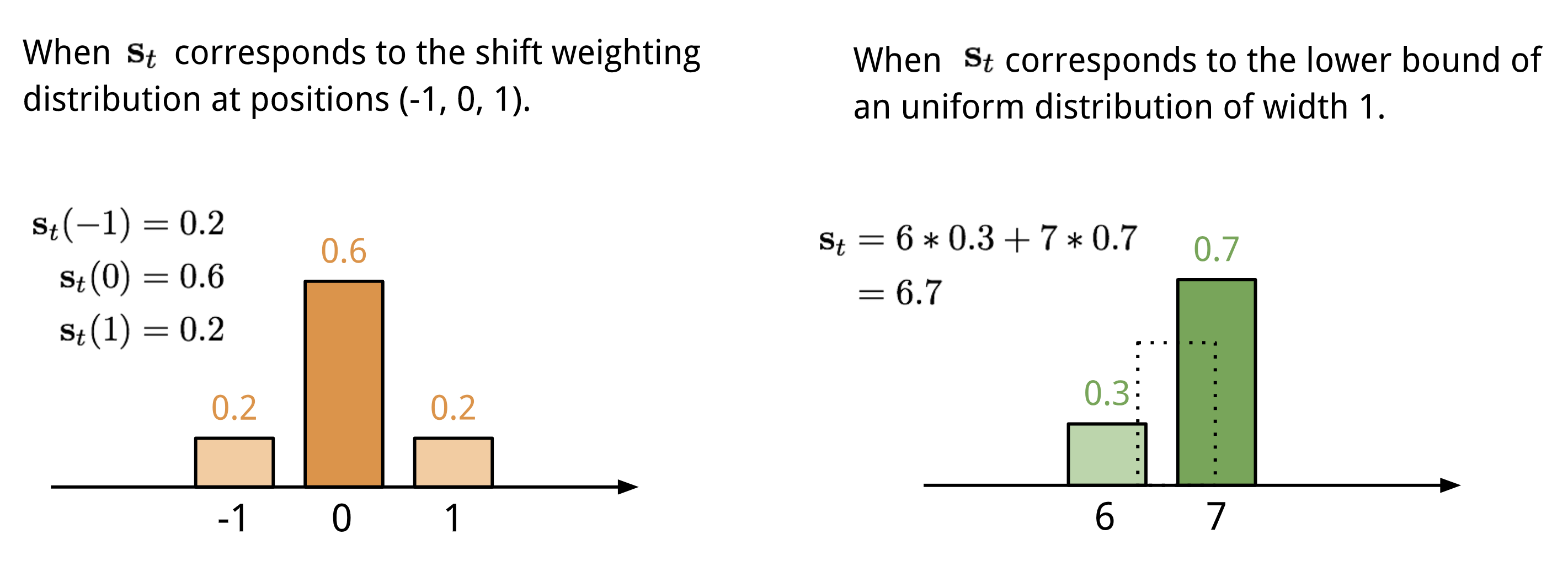
Fig. 11. Due modi di rappresentare la distribuzione di ponderazione dello spostamento \(\mathbf{s}_t\).
Infine la distribuzione di attenzione è migliorata da uno scalare di affinamento \(\gamma_t \geq 1\).
Il processo completo di generazione del vettore di attenzione \(\mathbf{w}_t\) al passo temporale t è illustrato in Fig. 12. Tutti i parametri prodotti dal controllore sono unici per ogni testa. Se ci sono più testine di lettura e scrittura in parallelo, il controllore produrrebbe più set.
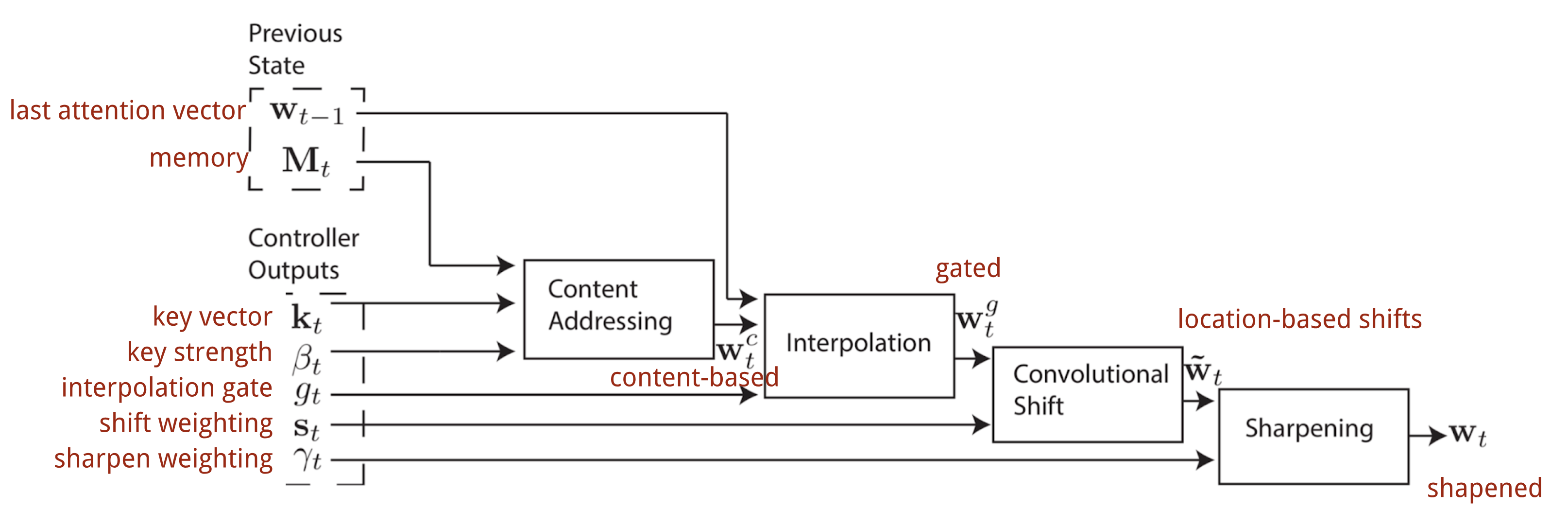
Fig. 12. Diagramma di flusso dei meccanismi di indirizzamento nella Neural Turing Machine. (Fonte immagine: Graves, Wayne & Danihelka, 2014)
Pointer Network
In problemi come l’ordinamento o il commesso viaggiatore, sia l’input che l’output sono dati sequenziali. Sfortunatamente, non possono essere facilmente risolti dai classici modelli seq-2-seq o NMT, dato che le categorie discrete degli elementi di output non sono determinate in anticipo, ma dipendono dalla dimensione variabile dell’input. Il Pointer Net (Ptr-Net; Vinyals, et al. 2015) viene proposto per risolvere questo tipo di problemi: Quando gli elementi di output corrispondono a posizioni in una sequenza di input. Piuttosto che usare l’attenzione per fondere le unità nascoste di un codificatore in un vettore di contesto (Vedi Fig. 8), la Pointer Net applica l’attenzione sugli elementi di input per sceglierne uno come output ad ogni passo del decoder.
Fig. 13. L’architettura di un modello di Pointer Network. (Fonte dell’immagine: Vinyals, et al. 2015)
\\fine{aligned}\]
Il meccanismo di attenzione è semplificato, poiché Ptr-Net non fonde gli stati del codificatore nell’uscita con i pesi di attenzione. In questo modo, l’output risponde solo alle posizioni ma non al contenuto dell’input.
Transformer
“Attention is All you Need” (Vaswani, et al., 2017), senza dubbio, è uno dei paper più impattanti e interessanti del 2017. Ha presentato un sacco di miglioramenti all’attenzione morbida e rende possibile fare la modellazione seq2seq senza unità di rete ricorrenti. Il modello “trasformatore” proposto è interamente costruito sui meccanismi di autoattenzione senza utilizzare l’architettura ricorrente allineata alla sequenza.
La ricetta segreta è portata nella sua architettura del modello.
Key, Value and Query
Il trasformatore adotta l’attenzione scaled dot-product: l’output è una somma pesata dei valori, dove il peso assegnato ad ogni valore è determinato dal prodotto di punti della query con tutte le chiavi:
\
Multi-Head Self-Attention
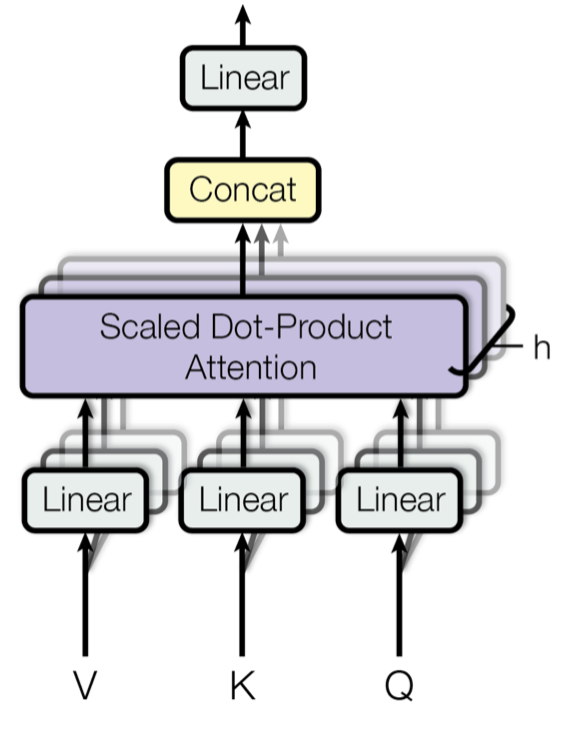
Fig. 14. Meccanismo di attenzione a più teste in scala del prodotto del punto. (Fonte dell’immagine: Fig 2 in Vaswani, et al., 2017)
Piuttosto che calcolare l’attenzione una sola volta, il meccanismo multi-testa esegue l’attenzione scalata dot-product più volte in parallelo. Gli output di attenzione indipendenti sono semplicemente concatenati e trasformati linearmente nelle dimensioni previste. Suppongo che la motivazione sia perché l’assemblaggio aiuta sempre? 😉 Secondo il documento, “l’attenzione multi-testa permette al modello di partecipare congiuntamente alle informazioni da diversi sottospazi di rappresentazione in posizioni diverse. Con una singola testa di attenzione, la media inibisce questo.”
\mathbf{W}^O \mathbf{W}^O \mathbf{W}^Q_i \mathbf{W}^Q_i, \mathbf{K} \mathbf{W}^K_i, \mathbf{V}mathbf{W}^V_i)\end{aligned}]
dove \(\mathbf{W}^Q_i\), \(\mathbf{W}^K_i\), \(\mathbf{W}^V_i\), e \(\mathbf{W}^O\) sono matrici di parametri da imparare.
Encoder
![]()
Fig. 15. L’encoder del trasformatore. (Fonte di immagine: Vaswani, et al, 2017)
Il codificatore genera una rappresentazione basata sull’attenzione con capacità di localizzare un pezzo specifico di informazione da un contesto potenzialmente infinitamente grande.
- Una pila di N=6 strati identici.
- Ogni strato ha uno strato di auto-attenzione a più teste e una semplice rete feed-forward completamente connessa in base alla posizione.
- Ogni sottolivello adotta una connessione residua e una normalizzazione di strato.Tutti i sottolivelli producono dati della stessa dimensione \(d_\testo{modello} = 512\).
Decoder
![]()
Fig. 16. Il decoder del trasformatore. (Fonte di immagine: Vaswani, et al, 2017)
Il decoder è in grado di recuperare dalla rappresentazione codificata.
- Una pila di N = 6 strati identici
- Ogni strato ha due sottolivelli di meccanismi di attenzione multitesta e un sottolivello di rete feed-forward completamente collegata.
- Similmente al codificatore, ogni sottolivello adotta una connessione residua e una normalizzazione di strato.
- Il primo sottolivello di attenzione multitesta è modificato per evitare che le posizioni assistano a posizioni successive, poiché non vogliamo guardare nel futuro della sequenza di destinazione quando prevediamo la posizione attuale.
Architettura completa
Ecco infine la visione completa dell’architettura del trasformatore:
- Entrambe le sequenze sorgente e destinazione passano prima attraverso strati di embedding per produrre dati della stessa dimensione \(d_\testo{modello} =512\).
- Per preservare le informazioni di posizione, una codifica posizionale basata su onde sinusoidali viene applicata e sommata all’uscita di embedding.
- Un softmax e uno strato lineare vengono aggiunti all’uscita finale del decoder.
![]()
Fig. 17. L’architettura del modello completo del trasformatore. (Fonte immagine: Fig 1 & 2 in Vaswani, et al., 2017.)
Provare a implementare il modello del trasformatore è un’esperienza interessante, ecco la mia: lilianweng/transformer-tensorflow. Leggi i commenti nel codice se sei interessato.
SNAIL
Il trasformatore non ha una struttura ricorrente o convoluzionale, anche con la codifica posizionale aggiunta al vettore di incorporazione, l’ordine sequenziale è solo debolmente incorporato. Per problemi sensibili alla dipendenza posizionale come l’apprendimento del rinforzo, questo può essere un grosso problema.
Il Simple Neural Attention Meta-Learner (SNAIL) (Mishra et al., 2017) è stato sviluppato parzialmente per risolvere il problema con il posizionamento nel modello del trasformatore combinando il meccanismo di autoattenzione nel trasformatore con le convoluzioni temporali. Ha dimostrato di essere buono sia in compiti di apprendimento supervisionato che di apprendimento per rinforzo.
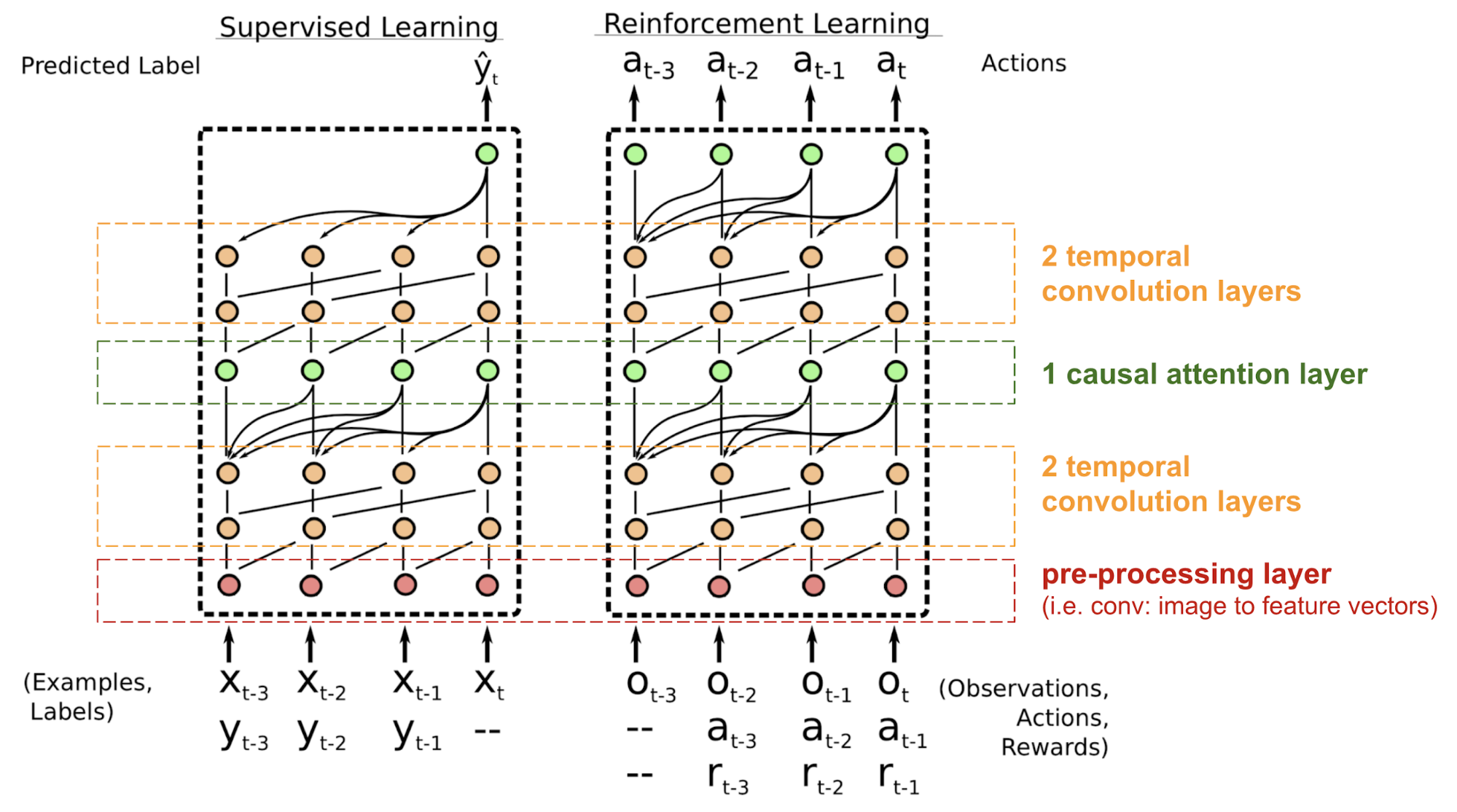
Fig. 18. Architettura del modello SNAIL (Fonte immagine: Mishra et al., 2017)
SNAIL nasce nel campo del meta-learning, che è un altro grande argomento degno di un post a sé. Ma in parole semplici, ci si aspetta che il modello di meta-apprendimento sia generalizzabile a nuovi compiti non visti nella distribuzione simile. Leggi questa bella introduzione se sei interessato.
Self-Attention GAN
Self-Attention GAN (SAGAN; Zhang et al., 2018) aggiunge strati di autoattenzione in GAN per consentire sia al generatore che al discriminatore di modellare meglio le relazioni tra le regioni spaziali.
La classica DCGAN (Deep Convolutional GAN) rappresenta sia il discriminatore che il generatore come reti convoluzionali multistrato. Tuttavia, la capacità di rappresentazione della rete è limitata dalla dimensione del filtro, poiché la caratteristica di un pixel è limitata a una piccola regione locale. Per collegare regioni molto distanti tra loro, le caratteristiche devono essere diluite attraverso strati di operazioni convoluzionali e le dipendenze non sono garantite per essere mantenute.
Come l’autoattenzione (morbida) nel contesto della visione è progettata per imparare esplicitamente la relazione tra un pixel e tutte le altre posizioni, anche le regioni molto distanti, può facilmente catturare le dipendenze globali. Quindi ci si aspetta che la GAN dotata di auto-attenzione gestisca meglio i dettagli, urrà!
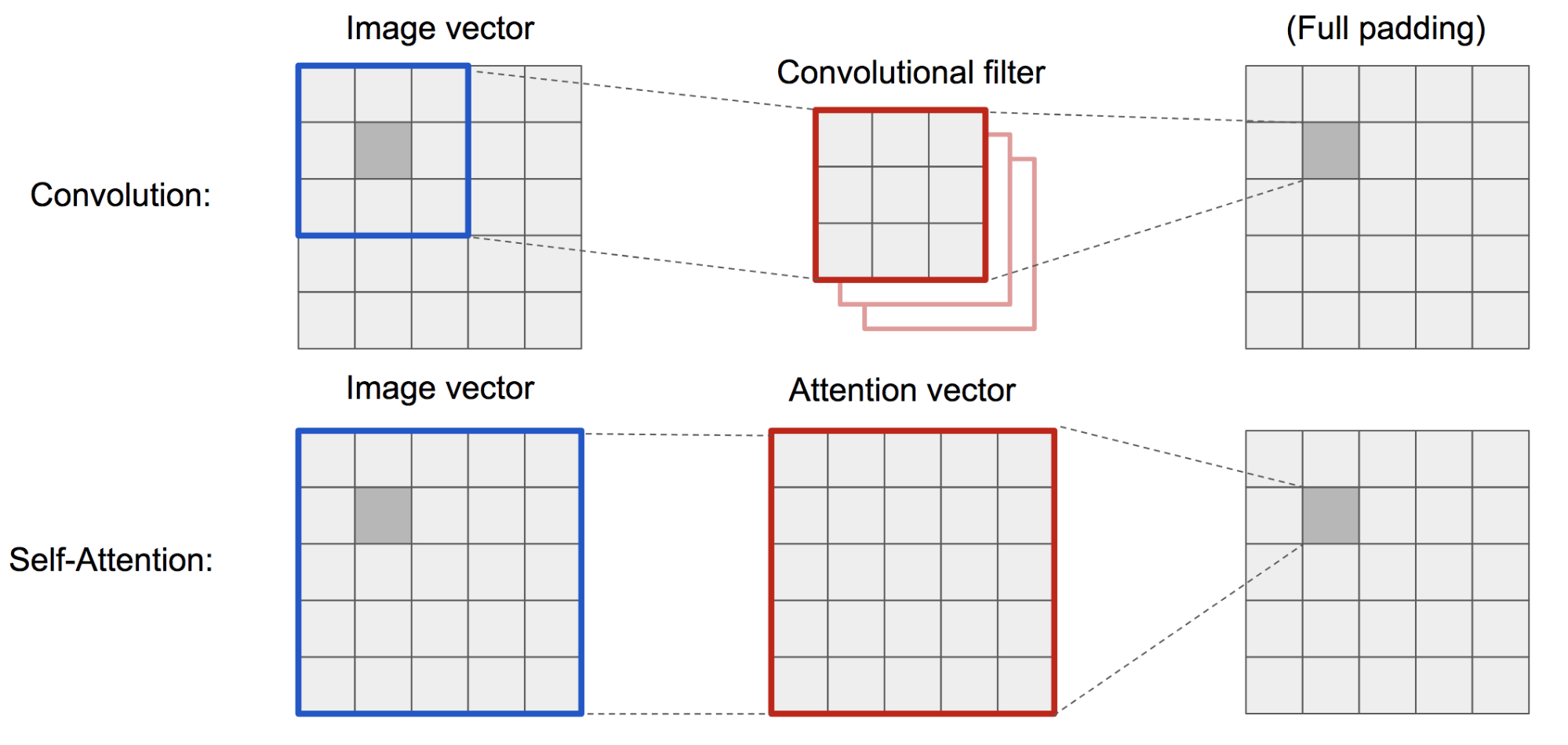
Fig. 19. L’operazione di convoluzione e l’autoattenzione hanno accesso a regioni di dimensioni molto diverse.
Il SAGAN adotta la rete neurale non locale per applicare il calcolo dell’attenzione. La mappa convoluzionale delle caratteristiche dell’immagine \(\mathbf{x}}) è ramificata in tre copie, corrispondenti ai concetti di chiave, valore e domanda nel trasformatore:
- Key: \(f(\mathbf{x}) = \mathbf{W}_f \mathbf{x})
- Query: \(g(\mathbf{x}) = \mathbf{W}_g \mathbf{x})
- Valore: \(h(\mathbf{x}) = \mathbf{W}_h \mathbf{x})
Poi applichiamo l’attenzione dot-product per produrre le mappe di autoattenzione:
\
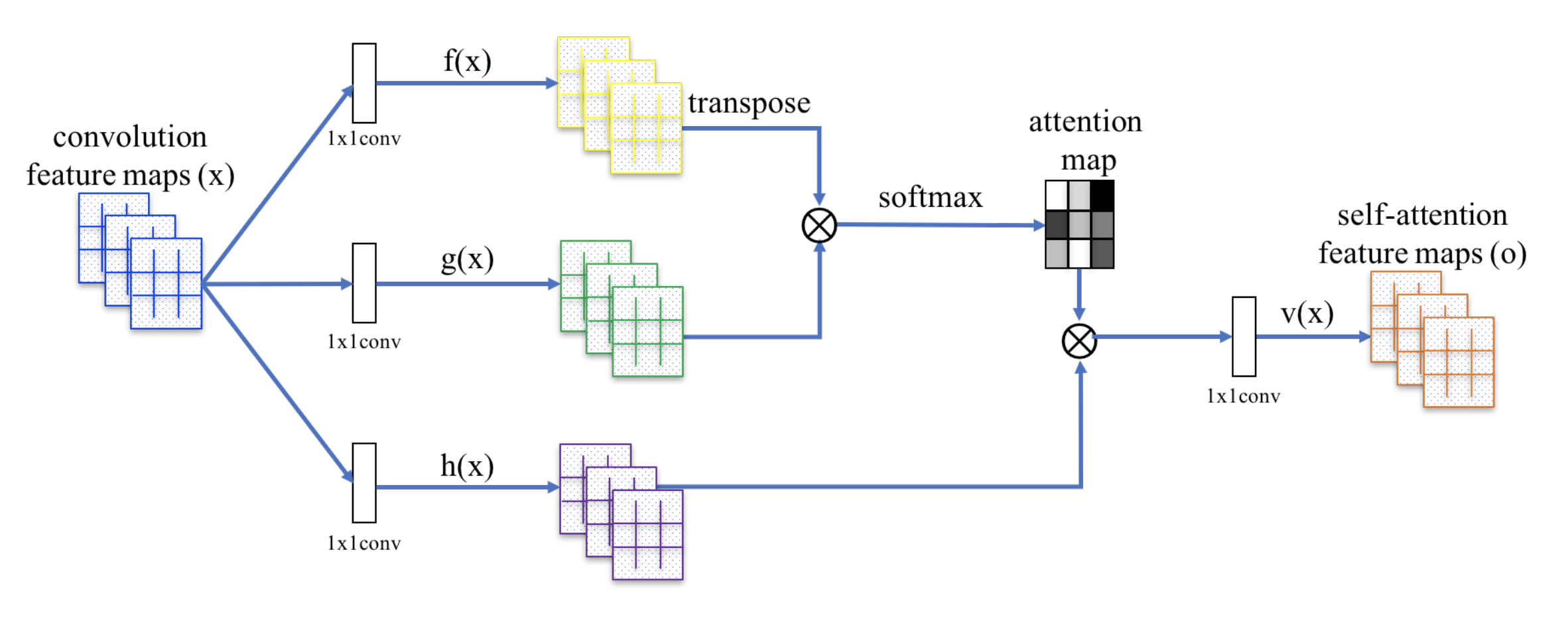
Fig. 20. Il meccanismo di auto-attenzione in SAGAN. (Fonte immagine: Fig. 2 in Zhang et al, 2018)
Inoltre, l’output dello strato di attenzione viene moltiplicato per un parametro di scala e aggiunto nuovamente alla mappa originale delle caratteristiche di input:
\
Mentre il parametro di scala \(\gamma\) viene aumentato gradualmente da 0 durante l’addestramento, la rete è configurata per fare affidamento prima sugli spunti nelle regioni locali e poi gradualmente imparare ad assegnare più peso alle regioni che sono più lontane.

Fig. 21. Immagini di esempio 128×128 generate da SAGAN per diverse classi. (Fonte dell’immagine: Partial Fig. 6 in Zhang et al., 2018)
Citato come:
Se notate errori e sbagli in questo post, non esitate a contattarmi a e sarei molto felice di correggerli subito!
Ciao al prossimo post 😀
“Attention and Memory in Deep Learning and NLP.” – Jan 3, 2016 by Denny Britz
“Neural Machine Translation (seq2seq) Tutorial”
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. “Traduzione automatica neurale imparando congiuntamente ad allineare e tradurre”. ICLR 2015.
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, e Yoshua Bengio. “Mostra, partecipa e racconta: Generazione neurale di didascalie di immagini con attenzione visiva”. ICML, 2015.
Ilya Sutskever, Oriol Vinyals, e Quoc V. Le. “Apprendimento da sequenza a sequenza con reti neurali”. NIPS 2014.
Thang Luong, Hieu Pham, Christopher D. Manning. “Approcci efficaci alla traduzione automatica neurale basata sull’attenzione”. EMNLP 2015.
Denny Britz, Anna Goldie, Thang Luong, e Quoc Le. “Esplorazione massiccia di architetture di traduzione automatica neurale”. ACL 2017.
Ashish Vaswani, et al. “L’attenzione è tutto ciò che serve.” NIPS 2017.
Jianpeng Cheng, Li Dong, e Mirella Lapata. “Reti di memoria a lungo termine per la lettura automatica”. EMNLP 2016.
Xiaolong Wang, et al. “Reti neurali non locali”. CVPR 2018
Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, e Pieter Abbeel. “Un semplice meta-apprendista neurale attento”. ICLR 2018.
“WaveNet: A Generative Model for Raw Audio” – Sep 8, 2016 by DeepMind.
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. “Reti di puntatori”. NIPS 2015.
Alex Graves, Greg Wayne, e Ivo Danihelka. “Macchine di turing neurali.” arXiv preprint arXiv:1410.5401 (2014).