Chi ha spostato il mio 99° percentile di latenza?
Co-autore: Cuong Tran
Le latenze lunghe colpiscono i membri ogni giorno e migliorare i tempi di risposta dei sistemi anche al 99° percentile è fondamentale per l’esperienza dei membri. Ci possono essere molte cause come applicazioni lente, accessi al disco lenti, errori nella rete e molte altre. Abbiamo riscontrato una causa di microbursting del traffico che non può essere facilmente risolta con la strategia dell’hedging your bet, cioè l’invio della stessa richiesta a più server nella speranza che uno dei server non sia impattato dalle latenze longtail. In questo post seguente condivideremo la nostra metodologia per individuare le cause delle latenze longtail, le esperienze e le lezioni apprese.
Le latenze di rete tra le macchine in un centro dati possono essere basse. Generalmente, tutte le comunicazioni richiedono pochi microsecondi, ma ogni tanto, alcuni pacchetti richiedono qualche millisecondo. I pacchetti che impiegano pochi millisecondi generalmente appartengono al 90° percentile o superiore delle latenze. Le latenze a coda lunga si verificano quando questi percentili alti iniziano ad avere valori che vanno ben oltre la media e possono essere magnitudini maggiori della media. Quindi le latenze medie danno solo metà della storia. Il grafico qui sotto mostra la differenza tra una buona distribuzione di latenze e una con una coda lunga. Come potete vedere, il 99° percentile è 30 volte peggiore della mediana e il 99,9° percentile è 50 volte peggio!
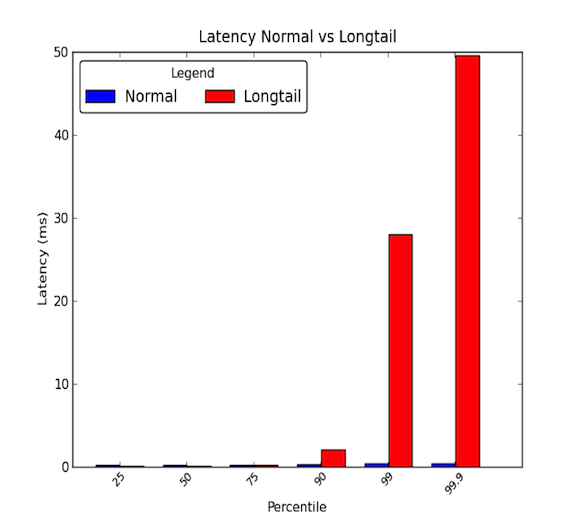
- Le code lunghe contano davvero!
- Caso di studio
- Passo 1: avere un ambiente controllato e semplificato
- Passo 2: Misurare la latenza end-to-end
- Step 3: Eliminare e sperimentare
- Microburst, oh mio!
- Impatto della causa principale
- Passo 4: Prototipare e validare
- Trovare la causa principale dei longtail può essere difficile.
- Lezioni apprese
- Riconoscimenti
Le code lunghe contano davvero!
Una latenza del 99° percentile di 30 ms significa che ogni 1 richiesta su 100 ha un ritardo di 30 ms. Per un sito web ad alto traffico come LinkedIn, questo potrebbe significare che per una pagina con 1 milione di pagine viste al giorno, allora 10.000 di quelle pagine viste subiscono il ritardo. Tuttavia, la maggior parte dei sistemi al giorno d’oggi sono sistemi distribuiti e 1 richiesta può effettivamente creare più richieste a valle. Quindi 1 richiesta potrebbe creare 2 richieste, o 10, o anche 100! Se più richieste a valle colpiscono un singolo servizio affetto da latenze longtail, il nostro problema diventa più spaventoso.
Per illustrare, diciamo che 1 richiesta del cliente crea 10 richieste a valle verso un sottosistema affetto da latenze longtail. E supponiamo che abbia una probabilità dell’1% di rispondere lentamente a una singola richiesta. Allora la probabilità che almeno 1 delle 10 richieste a valle sia affetta dalle latenze longtail è equivalente al complemento di tutte le richieste a valle che rispondono velocemente (99% di probabilità di rispondere velocemente ad ogni singola richiesta) che è:

Questo è il 9,5%! Questo significa che 1 richiesta del cliente ha quasi il 10% di possibilità di essere colpita da una risposta lenta. Questo equivale ad aspettarsi che 100.000 richieste di clienti siano colpite su 1 milione di richieste di clienti. Sono un sacco di membri!
Tuttavia, il nostro esempio precedente non considera che i membri attivi generalmente navigano più di una pagina e se quel singolo utente fa la stessa richiesta client più volte, la probabilità che l’utente sia colpito da problemi di latenza aumenta drasticamente. Di conseguenza, un servizio di backend molto attivo colpito da latenze longtail può avere un serio impatto su tutto il sito.
Caso di studio
Di recente abbiamo avuto l’opportunità di indagare su uno dei nostri sistemi distribuiti che presentava latenze di rete longtail. Questo problema è stato in agguato per alcuni mesi con indagini sommarie che non hanno mostrato alcuna ragione ovvia per le latenze di rete a coda lunga. Abbiamo deciso di fare un’indagine più approfondita per individuare la causa del problema. In questo post sul blog, abbiamo voluto condividere la nostra esperienza e la metodologia che abbiamo usato per identificare la causa principale attraverso il seguente caso di studio.
Passo 1: avere un ambiente controllato e semplificato
Prima abbiamo impostato un ambiente di prova del sistema di produzione attuale. Abbiamo semplificato il sistema a poche macchine che potevano riprodurre le latenze di rete a coda lunga. Inoltre, abbiamo spento la registrazione e i dati della cache di persistenza sul disco per eliminare lo stress IO. Questo ci ha permesso di concentrare la nostra attenzione su componenti chiave come la CPU e la rete. Ci siamo anche assicurati di impostare delle simulazioni di traffico che potevamo ripetere per avere test riproducibili mentre eseguivamo esperimenti e regolazioni sui sistemi. Il diagramma qui sotto mostra il nostro ambiente di test che consisteva in uno strato API, un server cache e un piccolo cluster di database.

A un livello elevato, le richieste da servizi esterni arrivano al sistema distribuito attraverso uno strato API. Le richieste sono poi fatte a un server di cache per soddisfare le query. Se i dati non sono nella cache, il server della cache farà richieste al cluster del database per formare la risposta alla query.
Passo 2: Misurare la latenza end-to-end
Il passo successivo è stato quello di guardare in dettaglio le latenze end-to-end. Così facendo, abbiamo potuto tentare di isolare le nostre latenze longtail e vedere quale componente nel nostro sistema distribuito ha influenzato le latenze che stavamo vedendo. Durante una simulazione del traffico, abbiamo usato l’utilità ping tra le varie coppie tra un host del livello API, un host del server di cache e uno degli host del cluster di database per misurare le latenze. Il seguente mostra le latenze al 99° percentile tra la coppia di host:

Da queste misurazioni iniziali, abbiamo concluso che il cache server aveva il problema delle latenze a coda lunga. Abbiamo fatto altri esperimenti per verificare questi risultati e abbiamo trovato quanto segue:
- Il problema principale era la latenza al 99° percentile per il traffico in entrata al server della cache.
- Le latenze al 99° percentile sono state misurate verso altre macchine host sullo stesso rack del server di cache e nessun altro host era interessato.
- le latenze al 99° percentile sono state misurate anche con il traffico TCP, UDP e ICMP e tutto il traffico in entrata al server della cache ne è stato influenzato.
Il passo successivo è stato quello di scomporre la rete e lo stack di protocollo del sospetto server di cache. Così facendo, speravamo di isolare la parte del server di cache che aveva un impatto sulle latenze della coda lunga. Le nostre misure di latenza end-to-end sono mostrate qui sotto:

Abbiamo fatto queste misure implementando una semplice applicazione UDP richiesta/risposta in C e abbiamo usato il timestamping fornito dal sistema Linux per il traffico di rete. Si può vedere un esempio nella documentazione del kernel per le caratteristiche in timestamping.c per ottenere informazioni dettagliate su quando i pacchetti colpiscono la scheda di interfaccia di rete e i socket. Vale anche la pena notare che alcune schede di interfaccia di rete forniscono un timestamping hardware che permette di ottenere informazioni su quando i pacchetti passano effettivamente attraverso la scheda di interfaccia di rete; tuttavia, non tutte le schede lo supportano. Potete vedere questo documento di RedHat per maggiori informazioni. Abbiamo anche usato tcpdumps sul sistema per essere in grado di vedere quando le richieste/risposte vengono elaborate a livello di protocollo dal sistema operativo.
Step 3: Eliminare e sperimentare
Dopo aver identificato che il problema di latenza era tra l’hardware della scheda di interfaccia di rete e il livello di protocollo del sistema operativo, ci siamo concentrati molto su queste parti del sistema. Dato che la scheda di interfaccia di rete (NIC) avrebbe potuto essere un possibile problema, abbiamo deciso di esaminarla per prima e risalire la pila per eliminare i vari livelli. Mentre guardavamo ogni componente, abbiamo tenuto a mente quanto segue: Equità, Contenuti e Saturazione. Queste tre aree chiave aiutano a trovare potenziali colli di bottiglia o problemi di latenza.
- Equità: Le entità nel sistema stanno ricevendo la loro giusta quota di tempo o risorse per elaborare o completare? Per esempio, ogni applicazione su un sistema sta ricevendo una giusta quantità di tempo da eseguire sulle CPU per completare i propri compiti? Se no, l’ingiustizia o l’equità sta causando un problema? Per esempio, forse un’applicazione ad alta priorità dovrebbe essere favorita rispetto alle altre; un video in tempo reale richiede più tempo per essere elaborato rispetto a un lavoro in background che consente di eseguire il backup dei file su un servizio cloud.
- Contese: Le entità nel sistema stanno lottando per la stessa risorsa? Per esempio, se due applicazioni stanno scrivendo su un singolo disco rigido, entrambe le applicazioni devono contendersi la larghezza di banda del disco. Questo si riferisce pesantemente all’equità, poiché le contese devono essere risolte attraverso una sorta di algoritmo di equità. Le contese possono essere più facili da cercare invece di una questione di equità.
- Saturazione: Una risorsa è sovra o completamente utilizzata? Se una risorsa viene sovrautilizzata o completamente utilizzata, potremmo colpire qualche limitazione che crea contestazioni o ritardi in quanto le entità devono mettersi in coda per utilizzare le risorse quando diventano disponibili.
Quando abbiamo affrontato il NIC, ci siamo concentrati principalmente sul guardare a) se le code straripavano, il che si sarebbe mostrato come scarti e avrebbe indicato possibili limitazioni nell’uso della banda o b) se c’erano pacchetti malformati che necessitavano di ritrasmissioni, il che avrebbe potuto causare ritardi. Ci sono stati 0 scarti e 0 pacchetti malformati che hanno colpito la NIC durante i nostri esperimenti e il nostro utilizzo della larghezza di banda è stato di circa 5 – 40 MB/s che è basso sul nostro hardware da 1 Gbps.
Poi, ci siamo concentrati sul livello del driver e del protocollo. Queste due parti erano difficili da separare; tuttavia, abbiamo trascorso una buona parte della nostra indagine guardando diversi tuning del sistema operativo che si occupavano della programmazione dei processi, dell’utilizzo delle risorse per i core, della gestione degli interrupt di programmazione e dell’affinità degli interrupt per l’utilizzo dei core. Queste aree chiave potrebbero potenzialmente causare ritardi nell’elaborazione dei pacchetti di rete e volevamo assicurarci che le richieste e le risposte fossero servite alla massima velocità che la macchina poteva gestire. Sfortunatamente, la maggior parte della nostra sperimentazione non ha prodotto alcuna causa principale.
I sintomi che abbiamo visto all’inizio sembravano implicare un sistema limitato nella larghezza di banda. Quando si produce molto traffico, le latenze aumentano a causa dei ritardi nelle code. Eppure, quando abbiamo guardato al livello NIC, non abbiamo visto un tale problema. Ma dopo aver eliminato quasi tutto nello stack, ci siamo resi conto che le nostre metriche di performance misurano in granularità di 1 secondo o 1.000 millisecondi. Con una latenza longtail di 30 ms, come potevamo sperare di catturare il problema?
Microburst, oh mio!
Molti dei nostri sistemi hanno schede di interfaccia di rete da 1 Gbps. Quando abbiamo guardato il traffico in entrata, abbiamo visto che il Cache Server ha generalmente sperimentato un traffico di 5 – 40 MB/s. Questo tipo di utilizzo della larghezza di banda non solleva alcuna bandiera rossa; tuttavia, cosa succede se guardiamo l’utilizzo della larghezza di banda per millisecondo! Il primo grafico qui sotto è dell’utilizzo della larghezza di banda al secondo e mostra un basso utilizzo, mentre il secondo grafico è dell’utilizzo della larghezza di banda al millisecondo e mostra una storia completamente diversa.

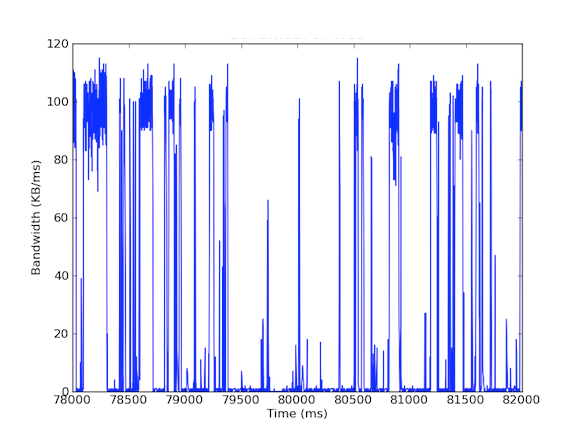
Per misurare il traffico di banda in entrata al millisecondo, abbiamo usato tcpdump per raccogliere il traffico per un determinato periodo di tempo. Questo ha richiesto calcoli offline, ma poiché tcpdump ha timestamp a livello di microsecondi, siamo stati in grado di calcolare l’utilizzo della larghezza di banda in entrata per millisecondo. Facendo queste misurazioni, siamo stati in grado di identificare la causa delle latenze di rete a coda lunga. Come si può vedere nei grafici di cui sopra, l’uso della larghezza di banda per millisecondo mostra brevi raffiche di poche centinaia di millisecondi alla volta che raggiungono quasi 100 kB/ms. Un tale tasso di 100 kB/ms sostenuto per un intero secondo sarebbe equivalente a 100 MB/s, che è l’80% della capacità teorica delle schede di interfaccia di rete da 1 Gbps! Questi scoppi sono conosciuti come microburst e sono creati dal cluster di database distribuito che risponde al server di cache tutto in una volta, creando così un collegamento completamente utilizzato per un tempo inferiore al secondo. Di seguito è riportato un grafico dell’utilizzo della larghezza di banda come percentuale della velocità di 1 Gbps rispetto alle latenze misurate durante lo stesso lasso di tempo. Come potete vedere, c’è un’alta correlazione tra i picchi di latenza e il traffico burst:
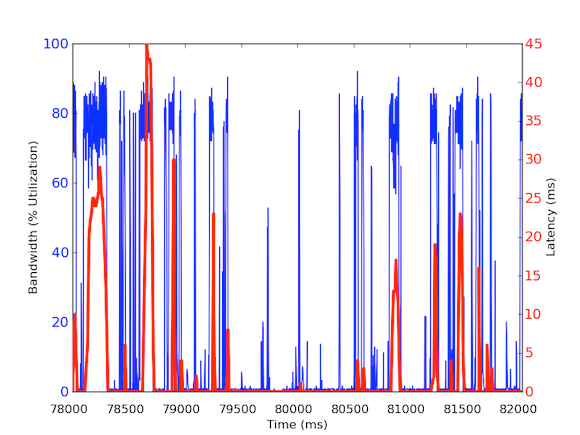
Questi grafici mostrano l’importanza delle misurazioni al sub-secondo! Anche se è difficile mantenere un’infrastruttura completa con tali dati, almeno per indagini approfondite, dovrebbe essere una granularità da seguire perché nelle prestazioni, i millisecondi contano davvero!
Impatto della causa principale
Questa causa principale ha un effetto interessante sul nostro sistema distribuito. Generalmente ai sistemi piace un alto throughput, quindi avere un utilizzo estremamente alto è una buona cosa. Ma il nostro server di caching ha a che fare con due tipi di traffico: (1) dati ad alta velocità dal database (2) piccole query dal livello API. Certo, le richieste dell’API Layer possono causare l’alto throughput di dati dal database, ma ecco la chiave: è necessario solo quando la richiesta non può essere soddisfatta dalla cache. Se la richiesta è nella cache, il server della cache dovrebbe restituire i dati rapidamente senza dover aspettare i calcoli del database. Ma cosa succede se una richiesta in cache arriva durante un microburst di risposta per una richiesta non in cache? Il microburst può causare 30 ms di ritardo a qualsiasi altro traffico in arrivo e quindi la richiesta nella cache potrebbe sperimentare 30 ms extra di ritardo che è completamente inutile!
Passo 4: Prototipare e validare
Una volta scoperta una causa plausibile, abbiamo voluto validare i nostri risultati. Dal momento che questo uso burst della larghezza di banda può causare ritardi agli hit della cache, abbiamo potuto isolare queste richieste dalle query del server della cache al cluster del database. Per fare questo abbiamo impostato un ambiente sperimentale in cui un singolo host del server di cache ha due NIC, ognuna con i propri indirizzi IP. Con questa configurazione, tutte le richieste API Layer al server di cache passano attraverso un’interfaccia e tutte le query del server di cache al cluster di database passano attraverso l’altra interfaccia. Il diagramma qui sotto illustra questo:

Con questa configurazione abbiamo misurato le seguenti latenze e, come si può vedere, le latenze tra il livello API e il server di cache sono effettivamente quello che ci aspettiamo – sano e sotto 1 ms. Le latenze con il cluster del database non possono essere evitate senza migliorare l’hardware; poiché vogliamo massimizzare il throughput, si verificheranno sempre dei burst e quindi i pacchetti saranno accodati all’interfaccia.

Pertanto, un traffico diverso merita priorità diverse e può essere una soluzione ideale per gestire il traffico microbursting. Altre soluzioni includono il miglioramento dell’hardware come l’utilizzo di hardware a 10 Gbps, la compressione dei dati o anche l’utilizzo della qualità del servizio.
Trovare la causa principale dei longtail può essere difficile.
La causa principale delle latenze longtail può essere difficile da trovare, poiché sono effimere e possono sfuggire alle metriche delle prestazioni. La maggior parte delle metriche di performance che raccogliamo qui a LinkedIn sono a granularità di 1 secondo e alcune a 1 minuto. Tuttavia, prendendo questo in prospettiva, le latenze longtail che durano 30 ms possono essere facilmente mancate da misurazioni con granularità anche di 1.000 ms (1 secondo). Non solo, le latenze a coda lunga possono essere dovute a diversi problemi nell’hardware o nel software e può essere abbastanza difficile trovare la causa principale in un sistema distribuito complesso. Alcuni esempi di cause possono essere l’utilizzo di risorse hardware che hanno a che fare con l’equità, la contesa e la saturazione, o problemi di modelli di dati come distribuzioni multi-nodali o utenti potenti che causano latenze longtail per i loro carichi di lavoro.
Per riassumere, incoraggiamo fortemente a ricordare questi quattro passi della nostra metodologia per indagini future:
- Avere un ambiente controllato e semplificato.
- Avere misure dettagliate di latenza end-to-end.
- Eliminare e sperimentare.
- Prototipare e convalidare.
Lezioni apprese
- La latenza longtail non è solo rumore! Può essere dovuta a diverse ragioni reali e le richieste del 99° percentile possono influenzare il resto di un grande sistema distribuito.
- Non scontate il 99° percentile dei problemi di latenza come utenti di potenza; man mano che gli utenti di potenza si moltiplicano, lo faranno anche i problemi.
- Hedging your bet anche se una strategia generalmente buona in cui il sistema invia la stessa richiesta due volte nella speranza di una risposta veloce non aiuta quando le latenze della coda lunga sono indotte dall’applicazione. Infatti, peggiora solo il sistema aggiungendo più traffico al sistema che nel nostro caso causerebbe più microburst. Se avessimo implementato questa strategia senza un’analisi approfondita, saremmo rimasti delusi perché le prestazioni del sistema sarebbero state degradate e avremmo sprecato una notevole quantità di sforzi per implementare una tale soluzione.
- Gli approcci scatter/gather possono facilmente causare dei microburst di utilizzo della banda, causando ritardi di coda sulla granularità del millisecondo.
- Sono necessarie misure di granularità inferiore al secondo.
- A volte i miglioramenti hardware sono il modo più conveniente per aiutare ad alleviare i problemi, ma fino ad allora, ci sono ancora interessanti mitigazioni che gli sviluppatori possono fare, come comprimere i dati o essere selettivi su quali dati vengono inviati o utilizzati.
Infine, la lezione più importante che abbiamo imparato è stata quella di seguire la metodologia. Le metodologie danno una direzione alle indagini, specialmente quando le cose diventano confuse o iniziano a sembrare un viaggio attraverso la Terra di Mezzo.
Riconoscimenti
Vorrei ringraziare Andrew Carter per il suo lavoro e la sua collaborazione durante l’indagine e Steven Callister per aver fornito supporto operativo e feedback. Grazie anche a Badri Sridharan, Haricharan Ramachandra, Ritesh Maheshwari, e Zhenyun Zhuang per i loro feedback e suggerimenti su questo scritto.