注意? アテンション!?
アテンションは、近年、深層学習コミュニティでかなり人気のあるコンセプトであり、便利なツールでもあります。 この記事では、アテンションがどのように発明されたのか、また、transformer や SNAIL など、さまざまなアテンションのメカニズムやモデルについて見ていきます。
アテンションは、ある程度、画像内の異なる領域に視覚的に注意を払う方法や、1 文中の単語の関連付けによって動機付けられるものです。 図1の柴犬の写真を例にとると、

図1. 男装した柴犬。 元写真のクレジットはInstagram @mensweardogです。
人間の視覚的注意は、「高解像度」で特定の領域に焦点を当て(例えば、黄色のボックス内のとがった耳を見てください)、一方で「低解像度」で周囲の画像を知覚し(例えば、今度は雪の背景と服はどうか)、それに応じて焦点位置を調整したり推測したりすることを可能にします。 ある画像の一部分が与えられたとき、残りの部分の画素がそこに表示されるべきものの手がかりとなる。 犬の鼻、右の耳、柴の目(赤い箱の中のもの)を見ているので、黄色い箱の中にとがった耳が見えると思います。 しかし、下のセーターや毛布は、それらの犬の特徴ほどには役に立たないだろう。
同様に、単語間の関係も1文や近い文脈で説明することができる。 私たちは「食べる」という言葉を目にしたとき、すぐに食べ物の言葉に出会うと予想します。 色彩用語は食べ物を説明するが、おそらく直接「食べる」とはあまり関係がない。
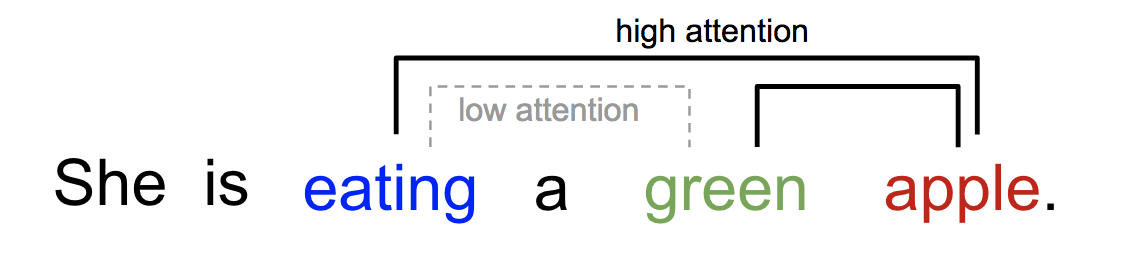
図2.色彩用語と食べ物の関係 ある単語が同じ文中の他の単語に異なる形で「注目」する。
一言で言えば、深層学習における注目とは、広義には重要度重みのベクトルと解釈できます。画像中のピクセルや文中の単語といったある要素を予測・推測するために、他の要素とどれだけ強く相関する(あるいは多くの論文にあるように「注目する」)かを注目ベクトルを使って推定し、その値を注目ベクトルで重み付けしたものの和を対象の近似値とするのです。
- Seq2Seq Modelの何が問題なのか
- 翻訳のために生まれた
- Definition
- A Family of Attention Mechanisms
- 概要
- Self-Attention
- Soft vs Hard Attention
- Global vs Local Attention
- Neural Turing Machines
- Reading and Writing
- Attention Mechanisms
- Pointer Network
- Transformer
- キー、値、クエリ
- Multi-Head Self-Attention
- エンコーダ
- Full Architecture
- SNAIL
- Self-Attention GAN
Seq2Seq Modelの何が問題なのか
seq2seq modelは言語モデリングの分野で生まれました(Sutskever, et al.2014)。 大まかに言うと、入力配列(ソース)を新しい配列(ターゲット)に変換することを目的としており、両方の配列は任意の長さであることが可能です。 変換タスクの例としては、テキストまたは音声での複数言語間の機械翻訳、質問と回答のダイアログ生成、あるいは文法ツリーへの文の構文解析などがある。 この表現はソースシーケンス全体の意味の良い要約であることが期待される。
エンコーダとデコーダの両方は再帰型ニューラルネットワーク、すなわち、LSTMまたはGRUユニットを使用している。 エンコーダ・デコーダのモデルで、「彼女は青リンゴを食べている」という文を中国語に翻訳している。
この固定長コンテキストベクトル設計の重大かつ明白な欠点は、長い文章を記憶することができないことである。 しばしば、入力全体を処理し終わると、最初の部分を忘れてしまうのである。 この問題を解決するために、アテンション機構が誕生しました(Bahdanau et al.、2015)。
翻訳のために生まれた
アテンション機構は、ニューラル機械翻訳(NMT)における長い原文を記憶するために生まれました。 エンコーダの最後の隠れた状態から単一のコンテキストベクトルを構築するのではなく、アテンションが発明した秘密のソースは、コンテキストベクトルとソース入力全体との間にショートカットを作成することである。 これらのショートカット接続の重みは、各出力要素に対してカスタマイズ可能です。
コンテキスト ベクトルは入力シーケンス全体にアクセスできますが、忘れることを心配する必要はありません。 ソースとターゲットの間のアライメントはコンテキスト ベクターによって学習され、制御されます。 基本的にコンテキストベクトルは3つの情報を消費する:
- エンコーダ隠れ状態;
- デコーダ隠れ状態;
- ソースとターゲットの間のアライメント。 Bahdanau et al., 2015のAdditive attention mechanismを用いたencoder-decoder model.
Definition
\mathbf{y}の項参照。 &= \end{aligned}}]
(Variables in bold indicate that they are vectors; the same for everything else in this post.)
エンコーダは双方向RNN(または他の任意のリカレントネットワーク設定)、前方の隠れ状態 \(overrightarrow{Th}_i}) と後方のもの \(overleftarrow{Th}_i}) であります。 この2つを単純に連結したものがエンコーダの状態です。
Thattop, i=1,\dots,n]\)
Weather (\mathbf{v}_a}) and \(\mathbf{W}_a) are both weight matrices to learn in the alignment model.これは1単語に対して先行語と後続語の両方がアノテーションに含まれるようにするための動機付けである。
アライメントスコアの行列は、原語と訳語の相関を明示的に示す良い副産物である。

図5. L’accord sur l’Espace économique européen a été signé en août 1992」(フランス語)とその英訳「The agreement on the European Economic Area was signed in August 1992」のアライメントマトリックス(英語)。 (画像出典: Bahdanau et al., 2015のFig 3)
より詳しい実装方法については、Tensorflowチームによる素敵なチュートリアルをご覧ください。
A Family of Attention Mechanisms
注意の助けにより、ソースとターゲットシーケンス間の依存性はもう中間距離で制限されない!注意の助けにより、ターゲットシーケンス間の依存性は、中間距離の制限がない!注意の助けにより、ターゲットシーケンス間の依存性は、中間距離の制限がない!
注目のメカニズム。 機械翻訳における注意による大きな改善を考えると、それはすぐにコンピュータビジョン分野に拡張され(Xuら、2015)、人々は他の様々な形式の注意メカニズムを探求し始めた(Luongら、2015;Britzら、2017;Vaswaniら、, 2017).
概要
以下は、いくつかの人気のある注意メカニズムと対応するアライメントスコア関数の要約表です:
以下は、注意メカニズムのより広いカテゴリの要約です。
Name Definition Citation Self-Attention(&) 同じ入力シーケンスの異なる位置に関連付けることです。 理論的には自己アテンションは上記の任意のスコア関数を採用できるが、ターゲット配列を同じ入力配列に置き換えるだけである。 Cheng2016 Global/Soft 入力状態空間全体にアテンションしている。 Xu2015 Local/Hard Attending to the part of input state space; as a patch of input image.Xu2015; Luong2015 (&)Also referred as “intra-attention” in Cheng et al, 2016や他のいくつかの論文では、
Self-Attention
自己注意は、イントラ注意とも呼ばれ、同じ配列の表現を計算するために、一つの配列の異なる位置を関連付ける注意機構である。 機械読み、抽象的要約、あるいは画像記述生成において非常に有用であることが示されている。
長期短期記憶ネットワークの論文では、機械読みを行うために自己注意を用いている。 下の例では、自己アテンション機構により、現在の単語と文の前の部分の相関を学習することができる。

図6. 現在の単語は赤で、青い影の大きさが活性化レベルを示す。 (画像出典:Cheng et al., 2016)
Soft vs Hard Attention
show, attend and tell論文では、注意メカニズムを画像に適用してキャプションを生成している。 画像はまずCNNで符号化され、特徴が抽出される。 次に、LSTMデコーダが畳み込み特徴を消費して説明語を一つずつ生成するが、このとき、重みはアテンションによって学習される。 注目重みの可視化により、モデルが画像のどの領域に注目して、ある単語を出力しているかが明確に示される。 “公園でフリスビーを投げている女性” (画像出典 Xuら2015の図6(b))
この論文は、注意が画像全体にアクセスできるかパッチのみにアクセスできるかに基づいて、「ソフト」対「ハード」注意の区別を最初に提案した:
- ソフト注意:アライメント重みは学習されて、ソース画像内のすべてのパッチにわたって「ソフトに」置かれる;Bahdanauら、2015と本質的に同じ種類の注意。
- Pro: モデルは滑らかで微分可能である。
- Con: ソース入力が大きい場合、高価である。
- Hard Attention: 一度に注意する画像のパッチを一つしか選択しない。
- Pro:推論時の計算が少ない。
- Con:モデルは非差別的で、学習には分散削減や強化学習などのより複雑な技術が必要である。 (Luong, et al., 2015)
Global vs Local Attention
Luong, et al., 2015は、「グローバル」「ローカル」アテンションを提唱している。 グローバル注意はソフト注意に似ているが、ローカル注意はハードとソフトの間の興味深いブレンドで、ハード注意を区別できるように改良したものである:モデルはまず現在のターゲット単語に対して単一の整列位置を予測し、次にソース位置を中心としたウィンドウがコンテキストベクトルを計算するのに用いられる
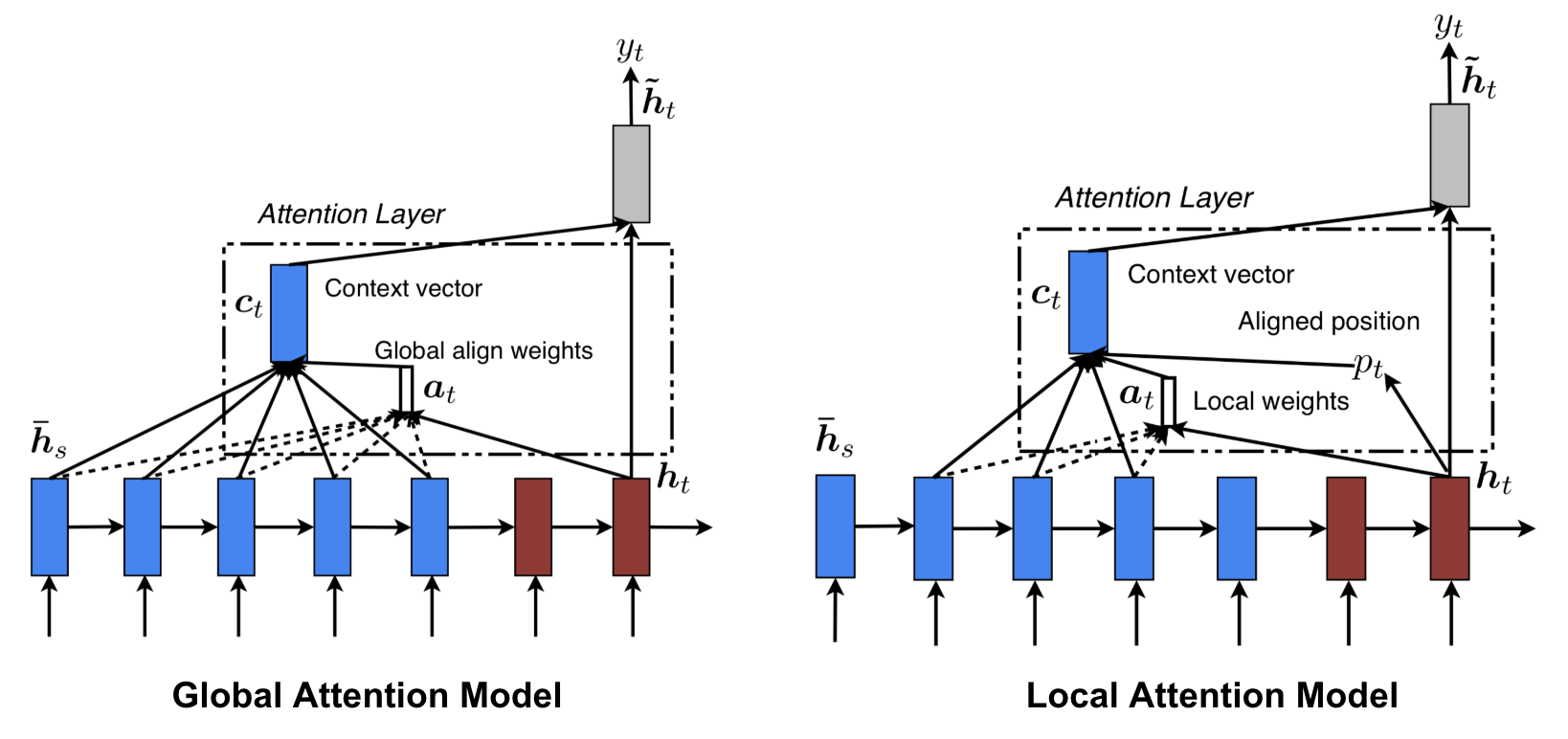
図8.グローバル注意はハード注意に似ているがローカル注意を区別できるように改良された。 Global vs Local attention (Image source: Fig 2 & 3 in Luong, et al., 2015)
Neural Turing Machines
Alan Turingは1936年に計算の最小化モデルを提案しました。 無限に長いテープと、そのテープと対話するヘッドで構成されている。 テープには無数のセルがあり、各セルには記号が記入されている。 0、1、または空白(” “)で埋め尽くされている。 操作ヘッドは、記号の読み取り、記号の編集、テープの左右への移動が可能である。 チューリング機械は、理論的には、どんな複雑で高価なコンピュータのアルゴリズムでもシミュレートすることができる。 無限のメモリは、チューリングマシンが数学的に無限であることを意味する。 しかし、現実の現代のコンピュータでは無限メモリは実現不可能であり、チューリングマシンを計算の数学的モデルとしてのみ考えることになる。 チューリングマシンの外観:テープ+テープを処理するヘッド。 (画像出典:http://aturingmachine.com/)
Neural Turing Machine(NTM, Graves, Wayne & Danihelka, 2014)は、ニューラルネットワークと外部メモリストレージを結合するためのモデルアーキテクチャである。 メモリはチューリングマシンのテープを模しており、ニューラルネットワークは操作ヘッドを制御してテープからの読み出しやテープへの書き込みを行う。 しかし、NTMのメモリは有限であるため、おそらく「ニューラル・フォン・ノイマンマシン」のように見えるだろう。
NTM には、コントローラのニューラルネットワークとメモリバンクという二つの主要なコンポーネントが含まれている。 コントローラ:メモリに対する演算の実行を担当する。 メモリ:処理された情報を格納する。 Memory: 処理された情報を格納し、N個のベクトル行を含む大きさΓ(NΓ×MΓ)の行列で、それぞれがΓ(MΓ×M)次元である。
1回の更新反復で、コントローラは入力とメモリバンクを処理し出力を生成する。 この相互作用は、並列に配置されたリードとライトのヘッドによって処理される。 読み出しと書き込みの両方の操作は、すべてのメモリ・アドレスにソフトにアテンションすることによって「ぼかす」。 Neural Turing Machine Architecture.
Reading and Writing
where \(w_t(i)\) is the \(i)-thth element in \(mathbf{w}_tenta) and \(\mathbf{M}_t(i)\) is the row vector in the memory, the \(i)-th row vector in the \ (i)-th (mathbf)-th (i)は、メモリーの中の重要な要素。
\ &Text{; erase}}_t(i) &= \tilde{mathbf{M}}_t(i) + w_t(i) \mathbf{a}_t &Text{scriptstyle{text{; add}} end{aligned}]
Attention Mechanisms
Neural Turing Machineでは、注意分布の生成方法はアドレッシングメカニズムに依存する。 NTMでは、content-based addressingとlocation-based addressingが混在している。
Content-based addressing
コンテンツアドレッシングは、コントローラが入力とメモリ行から抽出したキーベクトルⒶ(\mathbf{k}_t73 )との類似性に基づいて注目ベクトルを生成する。 内容に基づく注目スコアはコサイン類似度として計算され、softmaxによって正規化されます。 さらに、NTMは分布の焦点を増幅または減衰させるための強度乗数(strength multiplier)を追加します。
= \frac{¦exp(\beta_t \frac{Tmathbf{k}_t \cdot_t(i)}{}│mathbf{k}_t {})}{}sum_{j=1}^N \exp(\beta_t \frac{Tmathbf{k}_t \cdot) \mathbf{M}_t(j)}{Θ| Θmathbf{k}_t\| \cdot|Θmathbf{M}_t(j)})}]
Interpolation
次に、補間ゲートスカラー(g_tatta)は新しく生成したコンテンツとブレンドするのに使用されます。に基づく注目ベクトルと、前回のタイムステップの注目重みを比較する。
Location-based addressing
ロケーションベースアドレッシングは、許容される整数のシフトに対する重み付け分布によって、注意ベクトルの異なる位置の値を合計する。 これは、位置オフセットの関数であるカーネル㊧(㊦)を用いた1-d畳み込みと等価である。 この分布の定義方法は複数ある。 図11.を参考にされたい。
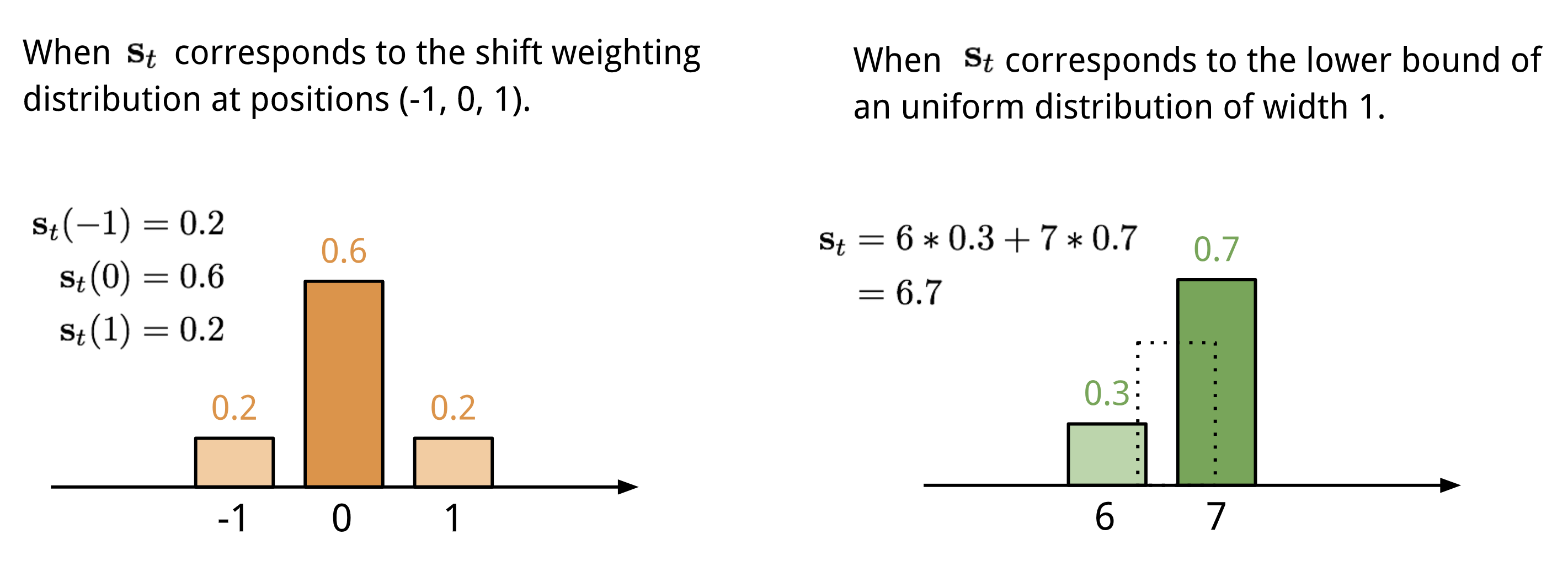
図11. Two ways to represent the shift weighting distribution \(\mathbf{s}_t}).
Finally the attention distribution is enhanced by a sharpening scalar \(\gamma_t \geq 1).
The complete process of generating the attention vector \(\mathbf{w}_t} at time step t is illustrated by Fig. 12. コントローラが生成するパラメータはすべて各ヘッドで一意である。 もし、複数の読み書きのヘッドが並列にあれば、コントローラは複数のセットを出力することになる。
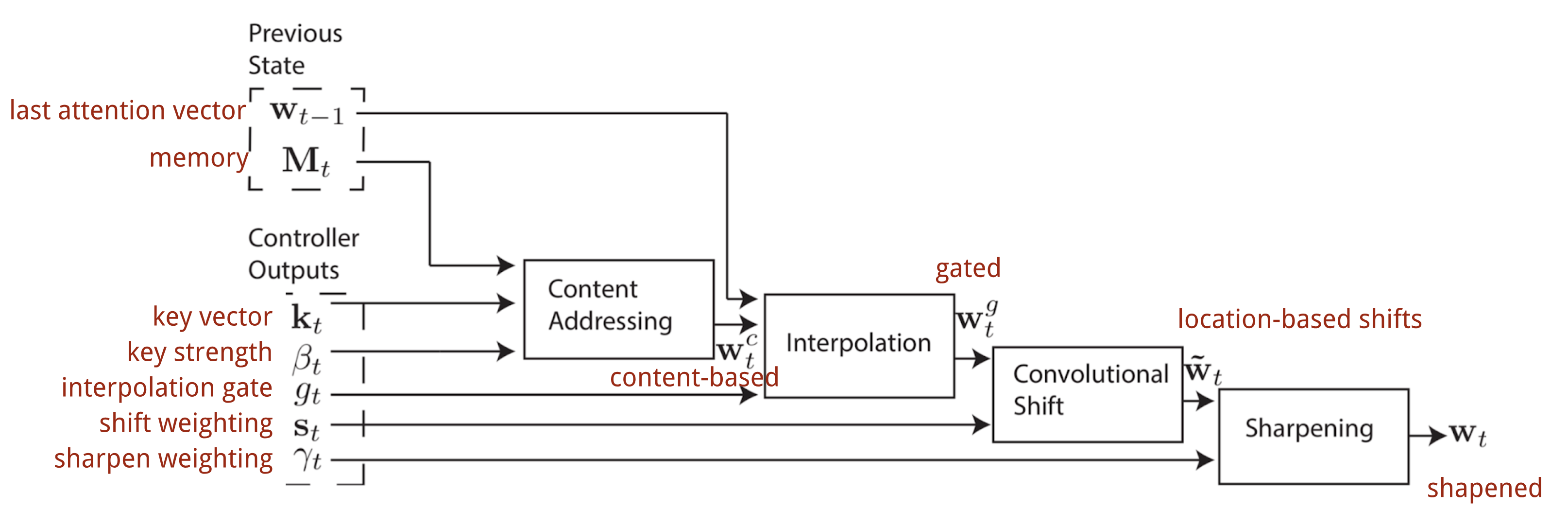
図12. ニューラルチューリングマシンにおけるアドレス指定機構のフロー図。 (画像出典:Graves, Wayne & Danihelka, 2014)
Pointer Network
ソートや巡回セールスマンなどの問題では、入力も出力も連続したデータである。 残念ながら、出力要素の離散的なカテゴリが事前に決定されず、可変入力サイズに依存することから、古典的なseq-2-seqモデルやNMTモデルでは容易に解決することができない。 この種の問題を解決するために、Pointer Net (Ptr-Net; Vinyals, et al. 2015) が提案されている。 出力要素が入力列の位置に対応する場合。 エンコーダの隠れユニットをコンテキストベクトルにブレンドするために注意を使用するのではなく(図8参照)、ポインタネットは入力要素に注意を適用して、各デコーダステップで出力として1つを選択する<1731><6050><7760><1731><7089>図13. ポインタ・ネットワーク・モデルのアーキテクチャ。 (Image source: Vinyals, et al. 2015)
\end{aligned}}[Ptr-Net は注目重みでエンコーダ状態を出力にブレンドしないため、注目機構は簡略化される。 このようにして、出力は位置のみに反応し、入力内容には反応しません。
Transformer
“Attention is All you Need” (Vaswani, et al., 2017), without doubt, is one of the most impactful and interesting paper in 2017.これは、2017年の最もインパクトのある興味深い論文の1つです。 それは、ソフトアテンションに多くの改良を加え、リカレントネットワークユニットなしでseq2seqモデリングを可能にすることを提示した。 提案された「トランスフォーマー」モデルは、配列整列リカレントアーキテクチャを使用せずに、完全に自己注意のメカニズムで構築されています
秘密のレシピは、そのモデルアーキテクチャに運ばれています。
キー、値、クエリ
トランスフォーマーはスケールドットプロダクトアテンションを採用する:出力は値の加重和であり、各値に割り当てられた重みはすべてのキーとクエリのドットプロダクトにより決定される:
Multi-Head Self-Attention
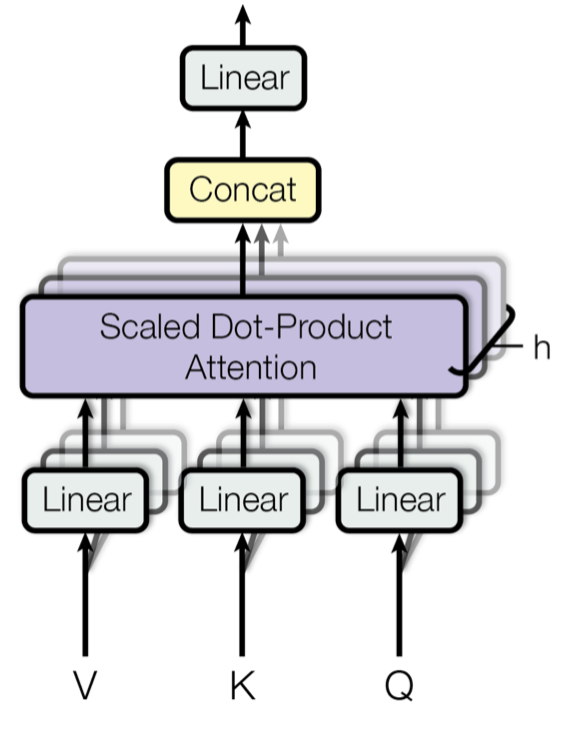
図14. マルチヘッド鱗片状ドットプロダクトアテンション機構。 (画像ソース:Vaswani, et al., 2017のFig 2)
一度だけ注意を計算するのではなく、マルチヘッド機構はスケーリングされたドットプロダクトアテンションを複数回並行して実行します。 独立した注意の出力は単純に連結され、期待される次元に線形変換される。 この動機は、アンサンブルは常に役に立つからだと思うのだが?) この論文によると、「マルチヘッド注意は、モデルが異なる位置の異なる表現部分空間からの情報に共同で注意を向けることを可能にする。 単一注意の場合、平均化がこれを抑制する。”
\mathbf{W}^O \text{where head}_i &= \text{Attention}(\mathbf{Q}\mathbf{W}^Q_i, \mathbf{K}יmathbf{W}^K_i, \mathbf{V}mathbf{W}^V_i)\end{aligned}}
where \(\mathbf{W}^Q_i), \(\mathbf{W}^K_i), \(\mathbf{W}^V_i), and \(\mathbf{W}^O) are parameters matrices to do you be learned.
エンコーダ
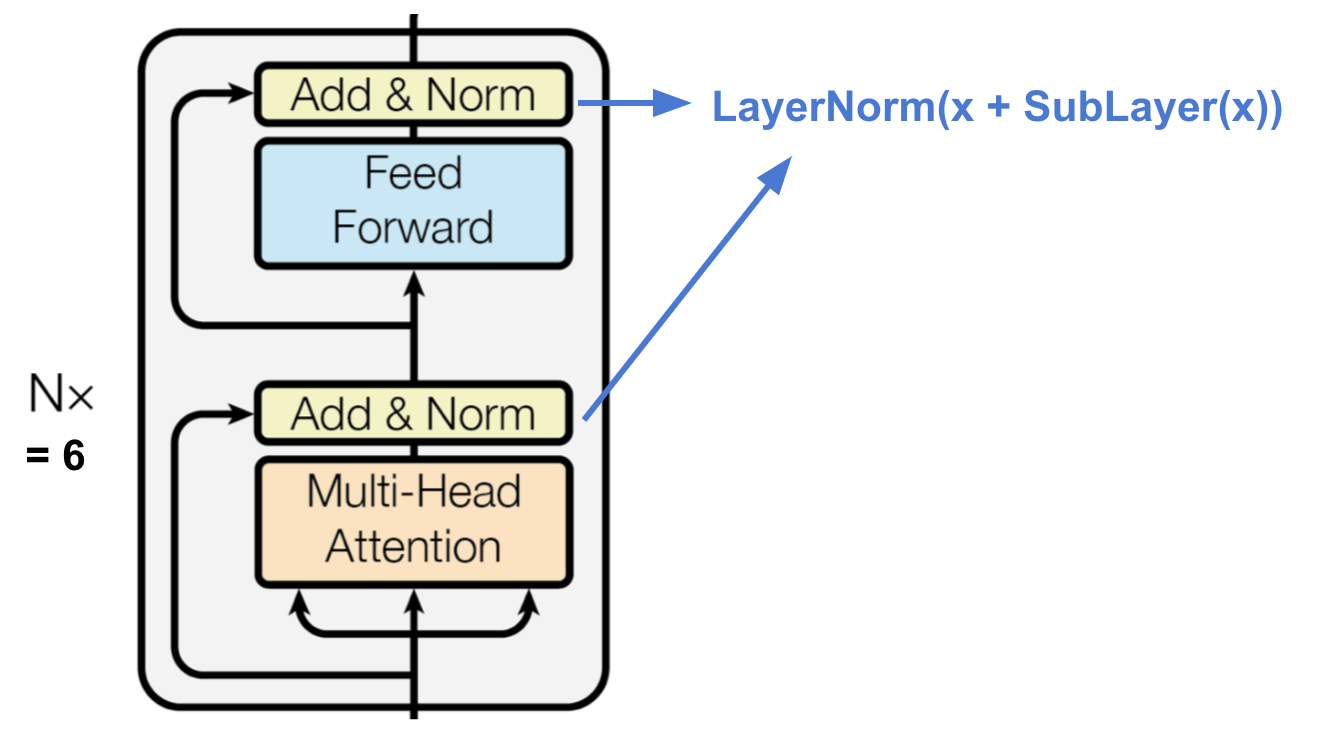
Fig.15. トランスフォーマーのエンコーダ (画像出典:Vaswani, et al, 2017)
エンコーダーは、潜在的に無限に大きな文脈から特定の情報の断片を探し出す能力を持つ注意ベースの表現を生成する。
- N=6の同一レイヤーのスタックである。
- 各層は多頭自己注意層と単純な位置方向完全接続フィードフォワードネットワークを持ち、各副層は残差接続と層正規化を採用している。全ての副層は同じ次元のデータ(d_text{model} = 512쇼)を出力する。 トランスフォーマーのデコーダ。 (画像出典:Vaswani, et al, 2017)
デコーダは、符号化された表現から検索することができる
- N=6個の同一層のスタック
- 各層は、マルチヘッド注意メカニズムの2つのサブレイヤーと完全接続フィードフォワードネットワークの1つのサブレイヤーを有している。
- エンコーダと同様に、各副層は残差接続と層正規化を採用している。
- 最初のマルチヘッド注目副層は、現在の位置を予測する際に目標配列の将来を見たくないため、位置が後続の位置に注目しないように変更されている。
Full Architecture
最後に、変換器のアーキテクチャの全体像を示します。
- ソースシーケンスとターゲットシーケンスともに、まず埋め込み層を通って同じ次元(d_text{model} =512)のデータが生成されます。
- 位置情報を保持するために、正弦波ベースの位置符号化を適用し、埋め込み出力と合計する。
- 最終デコーダ出力にはソフトマックスと線形層が加えられる。 変圧器のフルモデルアーキテクチャ。 (画像ソース: Vaswani, et al., 2017のFig 1 & 2。)
Try to implement the transformer model is an interesting experience, here is mine: lilianweng/transformer-tensorflow.The transformation model architecture is interesting experience. 興味があればコードのコメントを読んでみてください。
SNAIL
トランスフォーマーは再帰構造や畳み込み構造を持たず、埋め込みベクトルに位置符号化を加えても、順次順序は弱くしか取り込まれません。 強化学習のような位置依存性に敏感な問題では、これは大きな問題になり得る。
Simple Neural Attention Meta-Learner (SNAIL) (Mishra et al., 2017) は、transformerの自己注意機構と時間畳み込みを組み合わせて、transformerモデルの位置に関する問題の一部を解決するために開発されたものである。 教師あり学習と強化学習タスクの両方に優れていることが実証されている
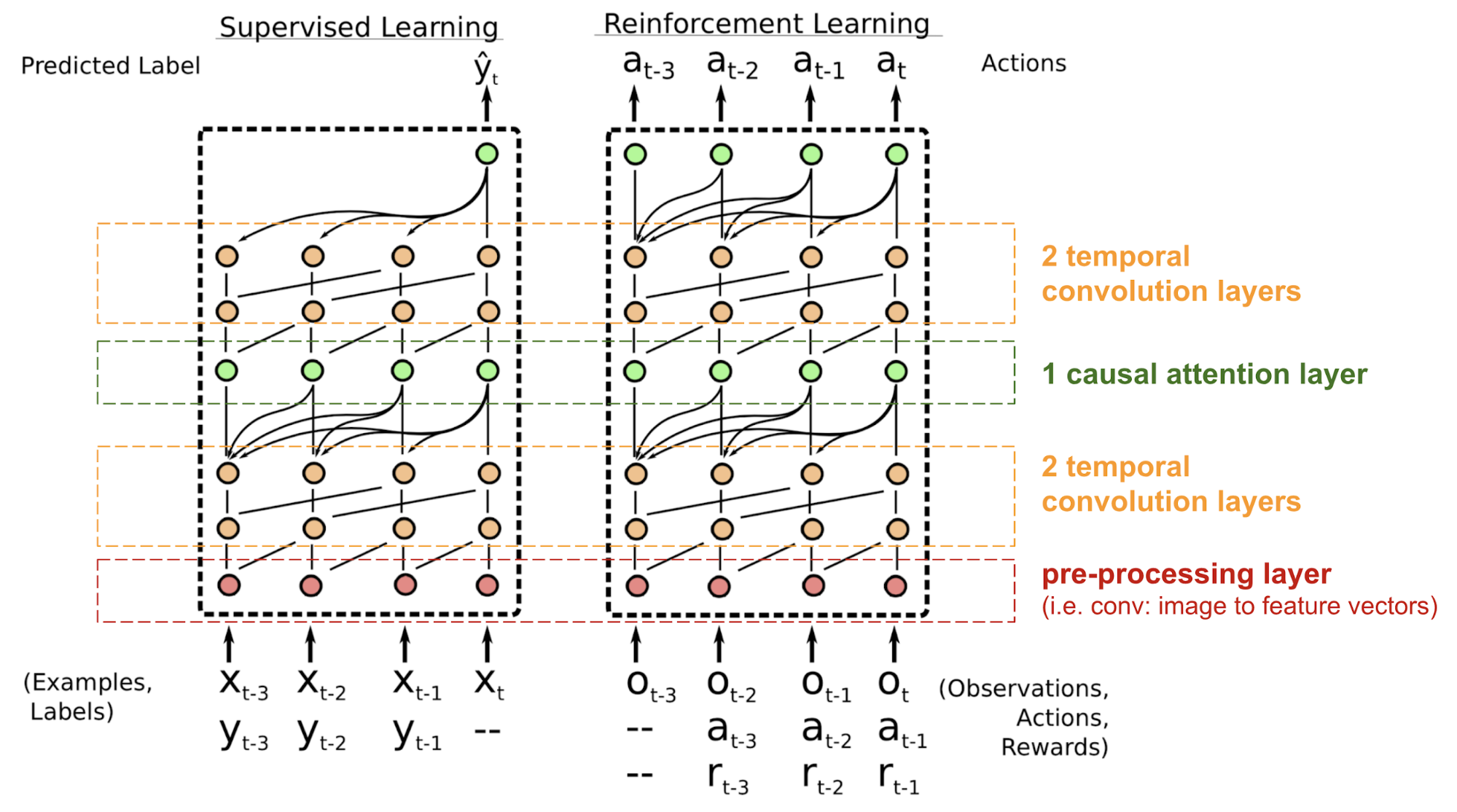
図18.SNAIL(Mishra et al. 2017)は、教師あり学習と強化学習タスクの両方に優れている。 SNAILモデルアーキテクチャ(画像出典:Mishra et al., 2017)
SNAILはメタ学習の分野で生まれたが、これはそれだけで記事に値する別の大きなトピックである。 しかし、簡単に言えば、メタ学習モデルは、類似分布の新規の未経験のタスクに一般化できることが期待されるのです。 興味があれば、この素敵な紹介を読んでください。
Self-Attention GAN
Self-Attention GAN (SAGAN; Zhang et al., 2018) はGANに自己注意層を加え、生成器と識別器の両方が空間領域間の関係をよりよくモデル化できるようにします。
The classic DCGAN (Deep Convolutional GAN) is represented both discriminator and generator as multi-layer convolutional networks. しかし、1画素の特徴は小さな局所領域に限られるため、ネットワークの表現能力はフィルタサイズによって制限される。
視覚の文脈における(ソフト)自己注意は、ある画素と他のすべての位置との関係を明示的に学習するように設計されており、たとえ遠く離れた領域でも、グローバルな依存関係を容易に捉えることが可能である。 したがって、自己注意を備えたGANは、細部をよりよく処理することが期待される、万歳!
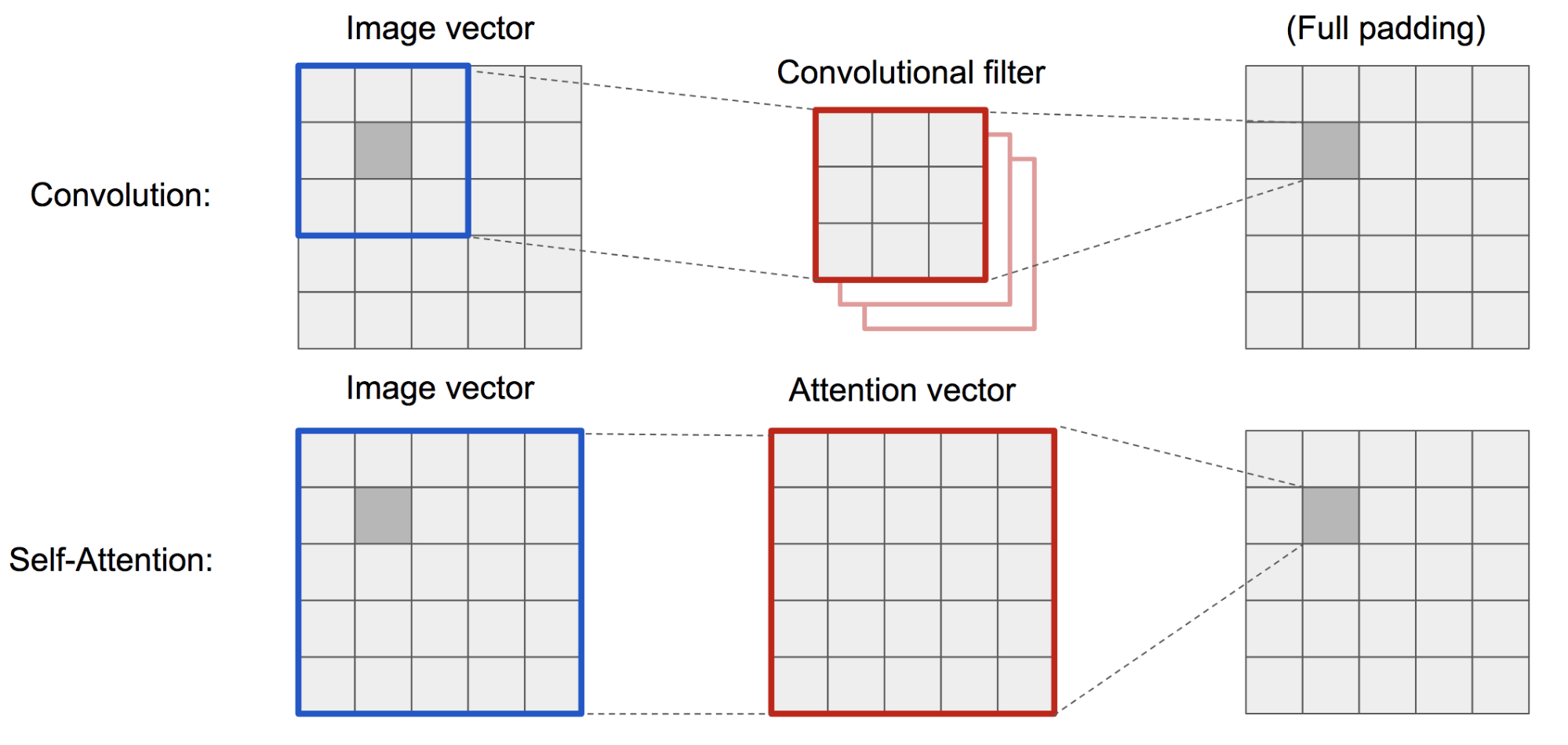
図19. 畳み込み演算と自己注意は、非常に異なるサイズの領域にアクセスできる。
SAGANは、注意の計算を適用するために、非局所ニューラルネットワークを採用する。 畳み込み画像特徴量マップ(feature map)のkey, value, queryの3つのコピーに分岐し、変換器の概念に対応させる:
- Key.Key.Value.Value.Value.Query.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value.Value: \(f(\mathbf{x}) = \mathbf{W}_f \mathbf{x}})
- Query: ゙゙゙゙゙゙。 \(g(\mathbf{x}) = \mathbf{W}_g \mathbf{x}})
- Value: \h(\mathbf{x}) = \mathbf{W}_h \mathbf{x}}
次に、ドットプロダクトアテンションを適用して自己注意特徴マップを出力する:
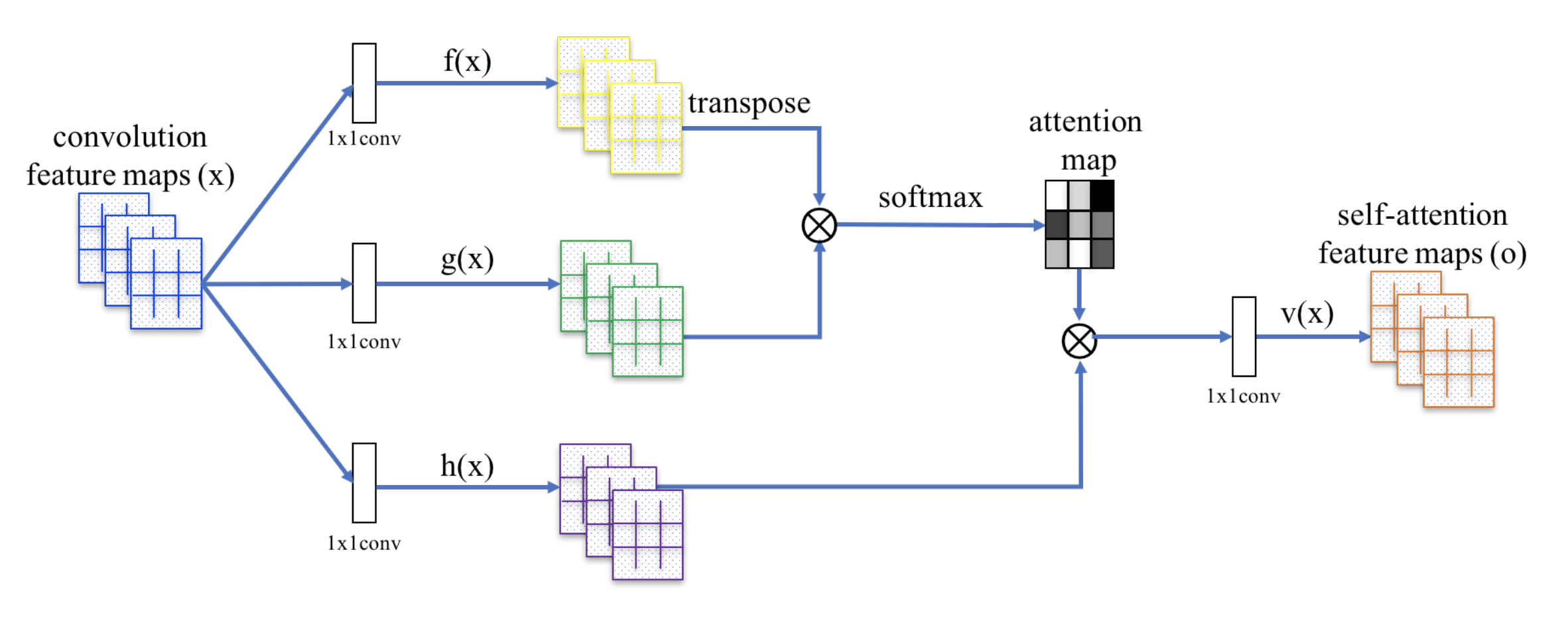
図20. SAGANにおける自己アテンション機構。 (画像出典:Zhang et al.のFig, 2018)
さらに、注意層の出力にスケールパラメータを乗じ、元の入力特徴マップに戻す:
学習中にスケールパラメータ(Σ)を0から徐々に増加させながら、まず局所領域の手がかりに頼り、徐々に遠く離れた領域に重みを割り当てるよう学習するネットワーク構成となっている

Fig. 21. SAGANで生成された128×128のクラス別画像例。 (画像ソース: Zhang et al., 2018のPartial Fig. 6)
引用元:
この投稿で間違いや間違いに気づいたら、遠慮なくで私に連絡すれば、すぐに修正させていただきます!
See you in the next post 😀
“Attention and Memory in Deep Learning and NLP”. – 2016年1月3日 by Denny Britz
“Neural Machine Translation (seq2seq) Tutorial”
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. “整列と翻訳の共同学習によるニューラル機械翻訳”. ICLR 2015.
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio.「整列と翻訳の共同学習によるニューラル機械翻訳」. “Show, attend and tell: 視覚的注意を伴うニューラル画像キャプション生成.” ICML, 2015.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le.(イリヤ・スーツケバー、オリオル・ビニャルズ、クオック・V・レ)。 “ニューラルネットワークによる配列間学習” NIPS 2014.
Thang Luong, Hieu Pham, Christopher D. Manning. “注意に基づくニューラル機械翻訳への効果的なアプローチ” EMNLP 2015.
Denny Britz, Anna Goldie, Thang Luong, and Quoc Le. “ニューラル機械翻訳アーキテクチャの大量探索” ACL 2017.
Ashish Vaswani, et al. “Attention is all you need.”(注意力があれば大丈夫です。 NIPS 2017.
Jianpeng Cheng, Li Dong, and Mirella Lapata. “機械読みのための長期短期記憶-ネットワーク” EMNLP 2016.
Xiaolong Wang, et al. “Non-local Neural Networks”(非局所的ニューラルネットワーク)。 CVPR 2018
Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, and Pieter Abbeel. “シンプルなニューラル・アテンド・メタ・ラーナー” ICLR 2018.
“WaveNet: A Generative Model for Raw Audio” – 2016年9月8日 by DeepMind.
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly.によるものです。 “ポインターネットワーク” NIPS 2015.
Alex Graves, Greg Wayne, and Ivo Danihelka. “Neural turing machines.” arXiv preprint arXiv:1410.5401 (2014).
.
- ソフト注意:アライメント重みは学習されて、ソース画像内のすべてのパッチにわたって「ソフトに」置かれる;Bahdanauら、2015と本質的に同じ種類の注意。