Who moved my 99th percentile latency?
Co-author: Cuong Tran
ロングテールのレイテンシは毎日メンバーに影響を与え、99 パーセントでもシステムの応答時間を改善することは、メンバーのエクスペリエンスにとって重要です。 遅いアプリケーション、遅いディスクアクセス、ネットワークでのエラーなど、多くの原因が考えられます。 私たちは、マイクロバーストトラフィックの根本的な原因を発見しました。それは、ロングテール遅延の影響を受けないサーバーがあることを期待して、複数のサーバーに同じリクエストを送るという、賭け事のヘッジ戦略では簡単に解決できないものです。 この投稿では、ロングテール遅延を根本的に解決するための私たちの方法論、経験、および学んだ教訓を共有します。
データ センター内のマシン間のネットワーク遅延は低いことがあります。 一般に、すべての通信は数マイクロ秒かかりますが、たまに、数ミリ秒かかるパケットもあります。 数ミリ秒かかるパケットは、一般に90パーセンタイル以上のレイテンシに属します。 ロングテール遅延は、これらの高いパーセンタイルの値が平均値を大きく超え、平均値より何倍も大きくなり始めると発生します。 このように、平均的なレイテンシは、話の半分しか伝えていないのです。 以下のグラフは、良いレイテンシ分布とロングテールの分布の違いを示しています。
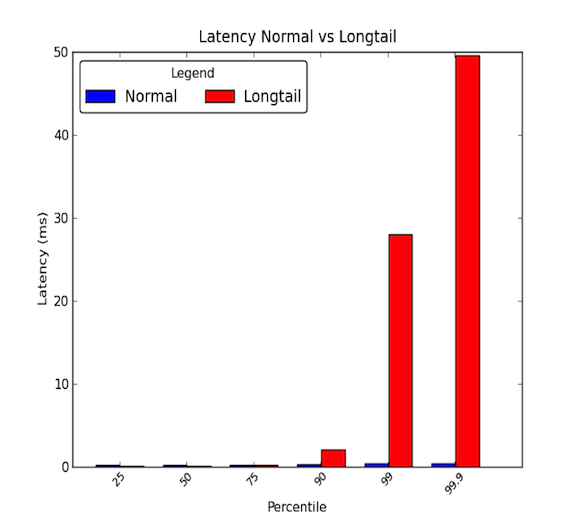
Longtails really matter!
99th percentile latency of 30ms means that every one in 100 requests experience 30 ms of delay.これは、100リクエストのうち1リクエストに30ミリ秒の遅延が発生することを意味します。 LinkedIn のようなトラフィック量の多い Web サイトでは、これは、1 日あたり 100 万ページ ビューのページに対して、そのうち 1 万ページ ビューが遅延を経験することを意味します。 しかし、最近のほとんどのシステムは分散システムであり、1つのリクエストが実際には複数の下流のリクエストを作成することができます。 つまり、1つのリクエストが2つのリクエストを生み出すこともあれば、10、100のリクエストを生み出すこともあるのです。 8147>
説明するために、1 つのクライアント リクエストが、ロングテール遅延の影響を受ける 1 つのサブシステムに 10 のダウンストリーム リクエストを作成するとしましょう。 そして、それが 1 つの要求に対して遅い応答をする確率が 1% であると仮定します。 すると、10個の下流リクエストのうち少なくとも1個がロングテール遅延の影響を受ける確率は、すべての下流リクエストが高速に応答する(単一のリクエストに対して高速に応答する確率が99%)ことの補数と等しく、それは:

これは9.5%です! これは、1つのクライアントリクエストが遅い応答の影響を受ける確率がほぼ10%であることを意味します。 これは、100 万のクライアント リクエストのうち、10 万のクライアント リクエストが影響を受けると予想することに相当します。 これは、多くのメンバーです。
しかし、先ほどの例では、アクティブなメンバーは通常複数のページを閲覧し、その1人のユーザーが同じクライアント要求を複数回行うと、そのユーザーが遅延問題の影響を受ける可能性が劇的に高くなることは考慮されていません。 したがって、ロングテール遅延の影響を受ける非常にアクティブなバックエンド サービスは、サイト全体に深刻な影響を及ぼします。
ケーススタディ
私たちは最近、ロングテールネットワーク遅延が発生する分散システムの 1 つを調査する機会を得ました。 この問題は、数か月間潜伏していましたが、ざっと調査したところ、ネットワーク遅延のロングテールの明白な理由は見つかりませんでした。 そこで、この問題の根本的な原因を探るため、より詳細な調査を行うことにしました。 このブログ投稿では、次のケーススタディを通じて、根本原因を特定するために使用した私たちの経験と方法論を共有したいと思います。
Step 1: 制御された簡略化した環境を持つ
私たちはまず、実際の生産システムのテスト環境をセットアップしました。 ロングテールのネットワーク遅延を再現できる数台のマシンにシステムを簡素化しました。 さらに、IOストレスがかからないように、ロギングやディスク上の永続化キャッシュデータをOFFにしました。 これにより、CPUやネットワークといった主要なコンポーネントに注意を向けることができるようになりました。 また、実験やチューニングを行う際に、再現性のあるテストを行うために、シミュレーショントラフィックを繰り返し実行できるように設定しました。 下の図は、API レイヤー、キャッシュ サーバー、および小規模なデータベース クラスターで構成されるテスト環境です。

高いレベルでは、外部サービスからのリクエストは API レイヤー経由で分散システムに入ってきます。 次に、リクエストはクエリを満たすためにキャッシュサーバーに送られる。 データがキャッシュ内にない場合、キャッシュ サーバーはデータベース クラスターに要求を出し、クエリ応答を形成します。
Step 2: End-To-End Latency
次のステップは、詳細なエンド ツー エンド レテンシーを調べることでした。 そうすることで、ロングテール遅延を分離し、分散システムのどのコンポーネントが遅延に影響を及ぼしているかを確認することを試みました。 シミュレーション トラフィックの実行中に、API レイヤー ホスト、キャッシュ サーバー ホスト、およびデータベース クラスター ホストの 1 つの間のさまざまなペアで ping ユーティリティを使用して遅延を測定しました。 8147> 
これらの最初の測定結果から、キャッシュ サーバーにロングテールの遅延の問題があると結論づけられました。 これらの調査結果を検証するためにさらに実験を行い、次のことがわかりました。
- 主要な問題は、Cache Server への受信トラフィックの 99 パーセントのレイテンシーでした。
- 99th パーセンタイル遅延は、キャッシュ サーバーと同じラック上の他のホスト マシンに対して測定され、他のホストは影響を受けませんでした。
- 99パーセンタイルの遅延は、TCP、UDP、およびICMPトラフィックでも測定され、Cacheサーバーへのすべての受信トラフィックに影響がありました。
次のステップは、疑わしいキャッシュ サーバーのネットワークとプロトコル スタックを分解することでした。 そうすることで、ロングテールのレイテンシに影響を与えるキャッシュ サーバーの一部を分離することが期待されました。 8147> 
私たちは、シンプルな UDP リクエスト/レスポンス アプリケーションを C 言語で実装し、Linux システムがネットワーク トラフィックに提供するタイムスタンプを使用して、これらの測定を実施しました。 パケットがネットワークインターフェースカードやソケットに当たったときの詳細な情報を得るために、timestamping.cの機能についてカーネルのドキュメントで例を見ることができます。 また、いくつかのネットワークインターフェースカードは、パケットが実際にネットワークインターフェースカードを通過したときの情報を得ることができるハードウェアタイムスタンプを提供することは注目に値しますが、すべてのカードがこれをサポートしているわけではありません。 しかし、すべてのカードがこれをサポートしているわけではありません。詳細については、RedHat によるこのドキュメントを参照してください。
ステップ 3: 排除と実験
遅延の問題がネットワーク インターフェイス カード ハードウェアとオペレーティング システムのプロトコル層の間にあることを確認した後、システムのこれらの部分に大きく焦点を当てました。 ネットワーク インターフェイス カード (NIC) が問題の可能性があったため、まずそれを調査し、さまざまな層を排除するためにスタックを上げていくことにしました。 各コンポーネントを見ていく中で、以下のことを念頭に置きました。 公平性」「争点」「飽和度」です。 これらの 3 つの重要な領域は、潜在的なボトルネックまたは遅延の問題を見つけるのに役立ちます。 システム内のエンティティは、処理または完了するための時間またはリソースを公平に分配されていますか? たとえば、システム上の各アプリケーションは、タスクを完了するために CPU で実行する公正な時間を受け取っているか。 そうでない場合、不公平感や公平性が問題を引き起こしていませんか? たとえば、優先度の高いアプリケーションは他のアプリケーションよりも優先されるべきかもしれません。リアルタイムのビデオは、クラウドサービスにファイルをバックアップするためのバックグラウンドジョブよりも処理に時間が必要なのです。
NIC に取り組んだとき、私たちは主に a) キューがオーバーフローしていないか、これは廃棄として表示され、帯域幅使用の制限を示す可能性があります、または b) 再送を必要とする不正なパケットがあるか、これは遅延を引き起こすかもしれません、を調べることに焦点を当てました。 実験中、NIC を襲った廃棄物は 0 個、不正なパケットは 0 個で、帯域幅の使用はおよそ 5 ~ 40 MB/s で、1 Gbps ハードウェアでは低レベルでした。 この 2 つの部分を切り離すことは困難でしたが、プロセスのスケジューリング、コアのリソース利用、スケジューリング割り込み処理、およびコア利用に対する割り込み親和性に対処するさまざまなオペレーティング システムのチューニングを調査することに、かなりの時間を費やしました。 これらの主要な領域は、ネットワークパケットの処理に遅れを生じさせる可能性があり、マシンが処理できる範囲でリクエストとレスポンスが処理されることを確認したかったのです。
私たちが最初に見た症状は、帯域幅が制限されたシステムを示唆しているように思えました。 多くのトラフィックが生成されると、待ち行列の遅延により待ち時間が増加します。 しかし、NIC レイヤーを見たとき、そのような問題は見当たりませんでした。 しかし、スタック内のほぼすべてを削除した後、私たちの性能指標は1秒または1,000ミリ秒の粒度で測定されることに気づきました。
Microbursts, oh my!
私たちのシステムの多くには 1 Gbps のネットワーク インターフェイス カードがあります。 受信トラフィックを見ると、Cache Server は通常 5 ~ 40 MB/s のトラフィックを経験していることがわかりました。 このような帯域幅の使用は、赤旗を表示しませんが、ミリ秒あたりの帯域幅の使用を見てみるとどうでしょう! 以下の最初のグラフは、1 秒あたりの帯域幅使用量であり、使用量が少ないことを示しています。一方、2 番目のグラフは、ミリ秒あたりの帯域幅使用量であり、まったく異なることを示しています。

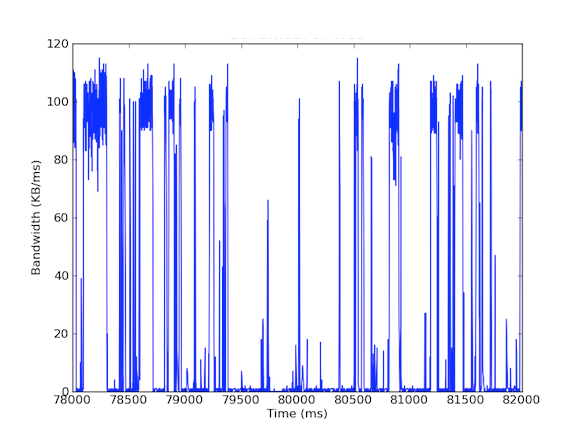
ミリ秒あたりの受信帯域幅トラフィックを測定するには、tcpdump を使用して一定期間のトラフィックを集めました。 これにはオフラインでの計算が必要でしたが、tcpdumpにはマイクロ秒レベルのタイムスタンプがあるため、ミリ秒あたりの受信帯域幅の使用量を計算することができました。 こうした計測を行うことで、ロングテールのネットワーク遅延の原因を特定することができました。 上のグラフを見ると、1ミリ秒あたりの帯域使用量を見ると、数百ミリ秒の短いバーストがあり、100kB/ms近くに達していることがわかります。 このような100kB/msの速度が1秒間続くと、100MB/sに相当し、これは1Gbpsネットワークインターフェースカードの理論容量の80%に相当する! このようなバーストはマイクロバーストと呼ばれ、分散データベースクラスタがキャッシュサーバに一斉に応答することで発生し、秒単位で完全に利用されるリンクが形成される。 下のグラフは、同じ時間帯に測定された1Gbpsの速度に対する帯域幅の使用率のパーセンテージとレイテンシーのグラフです。 8147> 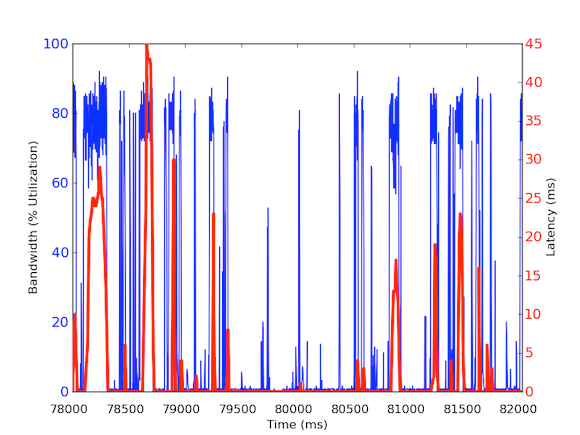
これらのグラフは、サブ秒計測の重要性を示しています! このようなデータで完全なインフラストラクチャを維持することは困難ですが、少なくとも深く掘り下げた調査においては、パフォーマンスではミリ秒が本当に重要なので、この粒度を使用すべきです!
Impact of Root Cause
この根本原因は、分散システムに興味深い影響を及ぼします。 一般に、システムは高いスループットを好み、したがって、非常に高い使用率を持つことは良いことです。 しかし、私たちのキャッシュ サーバーでは、2 種類のトラフィックを処理しています。 (1) データベースからの高スループットのデータ (2) API レイヤーからの小さなクエリ。 APIレイヤーのリクエストは、データベースからの高スループットのデータを引き起こす可能性がありますが、ここで重要なのは、リクエストがキャッシュによって満たされない場合にのみ必要とされることです。 リクエストがキャッシュにあれば、キャッシュサーバーはデータベースの計算を待つことなく、素早くデータを返すはずだ。 しかし、キャッシュされていないリクエストのマイクロバースト・レスポンス中にキャッシュされたリクエストが来たらどうなるのでしょうか? マイクロバーストは、他の受信トラフィックに 30ms の遅延を引き起こす可能性があり、したがって、キャッシュされたリクエストは、完全に不要な 30ms の遅延を余分に経験する可能性があります。 このバースト的な帯域幅の使用はキャッシュ ヒットへの遅延を引き起こす可能性があるので、これらの要求をキャッシュ サーバーのデータベース クラスターへのクエリから分離することができました。 そのために、1台のキャッシュサーバーホストが2つのNICを持ち、それぞれが独自のIPアドレスを持つ実験環境を構築しました。 このセットアップでは、キャッシュサーバーへのすべてのAPI Layerリクエストは一方のインターフェースを経由し、データベースクラスタへのすべてのキャッシュサーバーのクエリはもう一方のインターフェースを経由します。 このセットアップで、次のレイテンシーを測定しました。API レイヤーとキャッシュ サーバーの間のレイテンシーは、実際に期待したとおりで、1 ms 未満の健全な状態でした。 スループットを最大化したいので、バーストは常に発生し、したがって、パケットはインターフェイスでキューに入れられます。

したがって、異なるトラフィックは異なる優先度に値するので、マイクロバースト トラフィックを処理する理想的なソリューションになりえます。 他のソリューションとしては、10 Gbps ハードウェアの使用などのハードウェアの改善、データの圧縮、あるいは QoS の使用などがあります。
Finding the root cause of longtails can be hard.
The root cause of longtail latencies may be find hard, as they are ephemeral and elude performance metrics. LinkedIn で収集するパフォーマンス メトリクスのほとんどは 1 秒の粒度であり、1 分の粒度のものもあります。 しかし、それを考慮すると、30ミリ秒のロングテール遅延は、1,000ミリ秒(1秒)の粒度の測定でも簡単に見逃してしまう可能性があります。 それだけでなく、ロングテール遅延は、ハードウェアまたはソフトウェアのさまざまな問題に起因する可能性があり、複雑な分散システムにおいて根本原因を突き止めることはかなり困難です。 原因のいくつかの例は、公平性、競合、および飽和に対処するハードウェアリソースの使用、またはマルチノード分布やパワーユーザーによる作業負荷のロングテール遅延などのデータパターンの問題です。
Lessons learned
- ロングテール遅延は単なるノイズではありません! それはさまざまな実際の理由によるもので、99 パーセンタイルのリクエストは大規模な分散システムの残りの部分に影響を与える可能性があります。
- 99% の遅延の問題をパワー ユーザーとして割り引かないでください。
- システムが 1 つの高速応答を期待して同じ要求を 2 回送信する一般的に良い戦略ですが、ロングテール遅延がアプリケーションによって引き起こされる場合は、賭けをヘッジすることは役に立ちません。 実際、それはシステムにさらにトラフィックを追加することでシステムを悪化させ、私たちの場合はさらにマイクロバーストを発生させることになります。 もし、徹底的な分析なしにこの戦略を実行していたら、システム性能は低下し、そのような解決策を実行するためにかなりの労力を無駄にすることになり、私たちは失望したことでしょう。
- Scatter/gather アプローチは、帯域幅使用のマイクロバーストを容易に引き起こし、ミリ秒単位でのキュー遅延を引き起こします。
- サブ秒の粒度の測定が必要です。
- 場合によっては、ハードウェアの改良が問題の軽減に役立つ最もコスト効率の良い方法ですが、それまでは、データの圧縮や送信または使用するデータの選択など、開発者ができる興味深い緩和策があります。
最後に、私たちが学んだ最も重要な教訓は、方法論に従うということです。 8147>
Acknowledgements
私は、調査中のAndrew Carterの仕事と協力、および運用サポートとフィードバックを提供するSteven Callisterに感謝したいと思います。 また、Badri Sridharan、Haricharan Ramachandra、Ritesh Maheshwari、Zhenyun Zhuangには、この執筆に対するフィードバックと提案をいただき、感謝いたします。