Wie heeft mijn 99e percentiel latency verplaatst?
Co-auteur: Cuong Tran
Lange latentietijden hebben dagelijks invloed op leden en het verbeteren van de responstijden van systemen, zelfs bij het 99e percentiel, is van cruciaal belang voor de ervaring van leden. Er kunnen vele oorzaken zijn zoals trage applicaties, trage schijftoegang, fouten in het netwerk, en nog veel meer. We zijn een hoofdoorzaak tegengekomen van microbursting verkeer die niet gemakkelijk kan worden opgelost door de hedging your bet strategie, d.w.z. hetzelfde verzoek naar meerdere servers sturen in de hoop dat een van de servers geen last zal hebben van longtail latencies. In dit volgende bericht zullen we onze methodologie delen om de oorzaak te achterhalen van longtail latencies, ervaringen, en geleerde lessen.
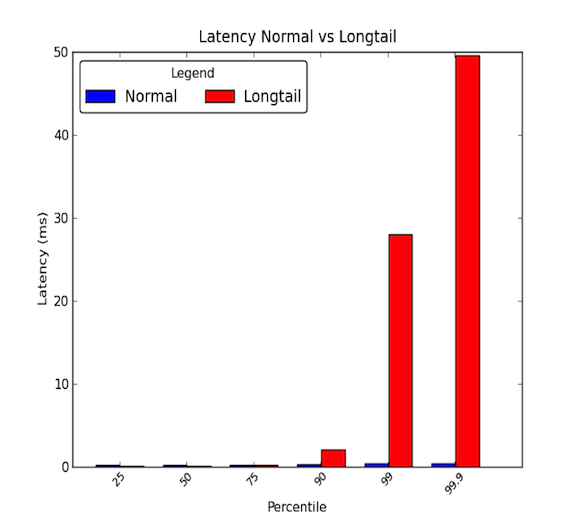
Netwerk latencies tussen machines binnen een datacenter kunnen laag zijn. Over het algemeen duurt alle communicatie een paar microseconden, maar zo nu en dan, sommige pakketten nemen een paar milliseconden. De pakketten die er een paar milliseconden over doen behoren meestal tot het 90e percentiel of hoger van de latencies. Longtail latenties treden op wanneer deze hoge percentielen waarden beginnen te vertonen die ver boven het gemiddelde liggen en magnitudes groter kunnen zijn dan het gemiddelde. Gemiddelde latenties geven dus maar de helft van het verhaal. De grafiek hieronder toont het verschil tussen een goede latency-verdeling en één met een longtail. Zoals u ziet, is het 99e percentiel 30 keer slechter dan de mediaan en het 99,9-percentiel 50 keer!
- Longtails zijn echt belangrijk!
- Gevalstudie
- Stap 1: Zorg voor een gecontroleerde en vereenvoudigde omgeving
- Step 2: Meet End-To-End Latency
- Stap 3: Elimineer en Experimenteer
- Microbursts, oh my!
- Impact van de hoofdoorzaak
- Stap 4: Prototype en Valideer
- Het vinden van de hoofdoorzaak van longtails kan moeilijk zijn.
- Lessen geleerd
- Acknowledgements
Longtails zijn echt belangrijk!
Een 99e percentiel latency van 30 ms betekent dat elke 1 op de 100 verzoeken 30 ms vertraging ondervindt. Voor een website met veel verkeer, zoals LinkedIn, zou dit kunnen betekenen dat voor een pagina met 1 miljoen pageviews per dag, 10.000 van die pageviews de vertraging ondervinden. De meeste systemen zijn tegenwoordig echter gedistribueerde systemen en één verzoek kan in feite meerdere downstream verzoeken creëren. Dus 1 verzoek kan 2 verzoeken creëren, of 10, of zelfs 100! Als meerdere downstream-verzoeken een enkele dienst raken die wordt beïnvloed door longtail-latencies, wordt ons probleem enger.
Om te illustreren, laten we zeggen dat 1 clientverzoek 10 downstream-verzoeken creëert naar een subsysteem dat wordt beïnvloed door longtail-latency. En stel dat het 1% kans heeft om traag te reageren op een enkel verzoek. Dan is de kans dat ten minste 1 van de 10 downstreamverzoeken wordt beïnvloed door de longtaillatenties gelijk aan het complement van alle downstreamverzoeken die snel reageren (99% kans om snel te reageren op een enkel verzoek) en dat is:

Dat is 9,5 procent! Dit betekent dat 1 clientaanvraag een kans van bijna 10 procent heeft om een trage reactie te krijgen. Dat komt overeen met de verwachting dat 100.000 van de 1 miljoen verzoeken van klanten worden beïnvloed. Dat zijn veel leden! Ons vorige voorbeeld houdt er echter geen rekening mee dat actieve leden over het algemeen meer dan één pagina bekijken en als die ene gebruiker hetzelfde clientverzoek meerdere keren doet, neemt de kans dat de gebruiker wordt beïnvloed door latency-problemen dramatisch toe. Daarom kan een zeer actieve backend dienst die last heeft van longtail latencies een serieuze site-brede impact hebben.
Gevalstudie
We hadden onlangs de gelegenheid om een van onze gedistribueerde systemen te onderzoeken die last had van longtail netwerk latencies. Dit probleem lag al een paar maanden op de loer en vluchtig onderzoek liet geen duidelijke redenen zien voor de lange netwerkvertragingen. We besloten een grondiger onderzoek in te stellen om de oorzaak van het probleem te achterhalen. In deze blogpost willen we onze ervaring en methodologie delen die we hebben gebruikt om de hoofdoorzaak te identificeren aan de hand van de volgende casestudy.
Stap 1: Zorg voor een gecontroleerde en vereenvoudigde omgeving
We hebben eerst een testomgeving opgezet van het huidige productiesysteem. We hebben het systeem vereenvoudigd tot een paar machines die de longtail netwerk latencies konden reproduceren. Verder hebben we logging en persistentie cache gegevens op de schijf uitgezet om IO-stress te elimineren. Hierdoor konden we onze aandacht richten op belangrijke componenten zoals CPU en het netwerk. We hebben ook gesimuleerde verkeersruns opgezet die we konden herhalen om reproduceerbare tests te hebben terwijl we experimenten en afstemmingen uitvoerden op de systemen. Het diagram hieronder toont onze testomgeving die bestond uit een API laag, een cache server, en een klein database cluster.

Op een hoog niveau komen verzoeken van externe diensten binnen op het gedistribueerde systeem via een API laag. De verzoeken worden vervolgens naar een cache-server gestuurd om de zoekopdrachten uit te voeren. Als de gegevens zich niet in de cache bevinden, doet de cache-server verzoeken aan de databasecluster om de query te beantwoorden.
Step 2: Meet End-To-End Latency
De volgende stap was om naar gedetailleerde end-to-end latencies te kijken. Op die manier konden we proberen onze longtail latencies te isoleren en te zien welke component in ons gedistribueerde systeem van invloed was op de latencies die we zagen. Tijdens een gesimuleerde verkeersrun gebruikten we de ping utility tussen de verschillende paren tussen een API layer host, een cache server host, en een van de database cluster hosts om de latencies te meten. Het volgende toont de 99e percentiel latencies tussen de paren van hosts:

Uit deze eerste metingen concludeerden we dat de cache server het longtail latencies probleem had. We experimenteerden verder om deze bevindingen te verifiëren en vonden het volgende:
- Het grootste probleem waren de 99e percentiel latenties voor inkomend verkeer naar de Cache Server.
- De 99ste percentiel latencies werden gemeten naar andere host machines in hetzelfde rack als de cache server en geen andere hosts werden beïnvloed.
- 99e percentiel latencies werden toen ook gemeten met TCP, UDP, en ICMP verkeer en al het inkomende verkeer naar de Cache Server werd beïnvloed.
De volgende stap was het ontleden van het netwerk en de protocol stack van de verdachte cache server. Door dit te doen, hoopten we het deel van de cache server te isoleren dat de longtail latencies beïnvloedde. Onze end-to-end uitsplitsing latency metingen is hieronder te zien:

We hebben deze metingen gedaan door een eenvoudige UDP request/response applicatie in C te implementeren en gebruik te maken van timestamping, geleverd door het Linux systeem voor het netwerk verkeer. U kunt een voorbeeld zien in de kernel documentatie voor de mogelijkheden in timestamping.c om gedetailleerde informatie te krijgen over wanneer de pakketten de netwerk interface kaart en sockets raken. Het is ook de moeite waard om op te merken dat sommige netwerkinterfacekaarten hardware timestamping bieden, waarmee u informatie kunt krijgen over wanneer pakketten daadwerkelijk door de netwerkinterfacekaart gaan; niet alle kaarten ondersteunen dit echter. U kunt dit document van RedHat bekijken voor meer informatie. We gebruikten ook tcpdumps op het systeem om te kunnen zien wanneer verzoeken/antwoorden op protocol niveau door het besturingssysteem worden verwerkt.
Stap 3: Elimineer en Experimenteer
Nadat we vaststelden dat het latency probleem zich tussen de netwerk interface kaart hardware en de protocol laag van het besturingssysteem bevond, hebben we ons sterk op deze delen van het systeem gericht. Omdat de netwerk interface kaart (NIC) een mogelijk probleem zou kunnen zijn, besloten we om deze eerst te onderzoeken en zo verder te werken om de verschillende lagen te elimineren. Terwijl we naar elk onderdeel keken, hielden we het volgende in gedachten: Fairness, Contentions, en Saturation. Deze drie sleutelgebieden helpen bij het vinden van potentiële knelpunten of latentieproblemen.
- Eerlijkheid: Krijgen entiteiten in het systeem hun eerlijk deel van de tijd of middelen om te verwerken of te voltooien? Bijvoorbeeld, krijgt elke toepassing op een systeem een eerlijke hoeveelheid tijd om op de CPU’s te draaien om hun taken te voltooien? Zo niet, veroorzaakt de oneerlijkheid of eerlijkheid dan een probleem? Bijvoorbeeld, misschien moet een toepassing met hoge prioriteit worden bevoordeeld ten opzichte van andere; realtime video vereist meer tijd om te verwerken dan een achtergrondtaak waarmee u een back-up van bestanden naar een cloudservice kunt maken.
- Geschillen: Zijn entiteiten in het systeem aan het vechten om dezelfde bron? Bijvoorbeeld, als twee applicaties schrijven naar een enkele harde schijf, moeten beide applicaties strijden om de bandbreedte van de schijf. Dit heeft veel te maken met eerlijkheid, omdat conflicten moeten worden opgelost door een soort eerlijkheidsalgoritme. Het is wellicht eenvoudiger om te zoeken naar conflicten dan naar eerlijkheid.
- Verzadiging: Wordt een hulpbron over- of volledig benut? Als een bron over- of volledig wordt gebruikt, kunnen we tegen een beperking aanlopen die leidt tot conflicten of vertragingen omdat entiteiten in de rij moeten staan om de bronnen te gebruiken wanneer ze beschikbaar komen.
Toen we de NIC onder handen namen, richtten we ons vooral op het kijken naar a) of wachtrijen overliepen, wat zou worden weergegeven als discards en zou duiden op mogelijke beperkingen in het bandbreedtegebruik of b) of er misvormde pakketten waren die opnieuw moesten worden verzonden, wat vertragingen zou kunnen veroorzaken. Er waren 0 discards en 0 misvormde pakketten die de NIC raakten tijdens onze experimenten en ons bandbreedte gebruik was ruwweg 5 – 40 MB/s, wat laag is op onze 1 Gbps hardware.
Volgende, richtten we ons op het driver en protocol niveau. Deze twee delen waren moeilijk te scheiden; maar we hebben een groot deel van ons onderzoek besteed aan het bekijken van verschillende besturingssysteemafstemmingen die te maken hadden met proces scheduling, resource gebruik voor cores, scheduling interrupt afhandeling en interrupt affiniteit voor core gebruik. Deze sleutelgebieden kunnen mogelijk vertragingen veroorzaken in het verwerken van netwerkpakketten en we wilden er zeker van zijn dat verzoeken en antwoorden zo snel werden verwerkt als de machine aankon. Helaas leverden de meeste van onze experimenten geen hoofdoorzaak op.
De symptomen die we in het begin zagen, leken te wijzen op een systeem met beperkte bandbreedte. Als er veel verkeer is, nemen de latenties toe door vertragingen in de wachtrijen. Toch, toen we naar de NIC laag keken, zagen we niet zo’n probleem. Maar nadat we bijna alles in de stack hadden geëlimineerd, realiseerden we ons dat onze prestatiemetingen in 1 seconde of 1.000 milliseconde granulariteiten meten. Met een 30 ms longtail latency, hoe kunnen we dan hopen het probleem op te sporen?
Microbursts, oh my!
Veel van onze systemen hebben 1 Gbps netwerk interface kaarten. Toen we naar het inkomende verkeer keken, zagen we dat de Cache Server over het algemeen 5 – 40 MB/s verkeer ondervond. Dit soort bandbreedtegebruik roept geen rode vlaggen op; maar wat als we eens keken naar bandbreedtegebruik per milliseconde! De eerste grafiek hieronder is van bandbreedte gebruik per seconde en laat een laag gebruik zien, terwijl de tweede grafiek van bandbreedte gebruik per milliseconde is en een heel ander verhaal laat zien.

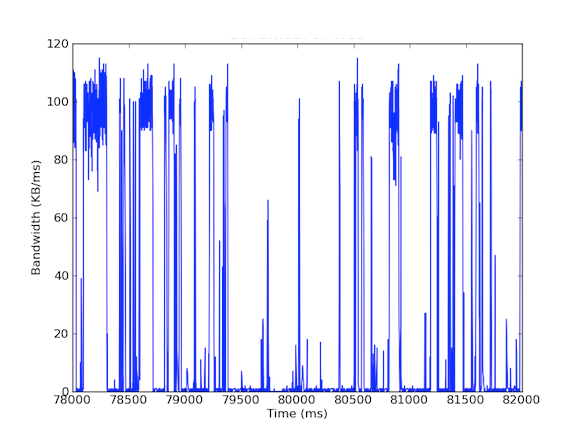
Om het per milliseconde inkomende bandbreedte verkeer te meten, gebruikten we tcpdump om verkeer te verzamelen voor een bepaalde periode van tijd. Dit vereiste offline berekeningen, maar omdat tcpdumps tijdstempels hebben op microseconde niveau, waren we in staat om het inkomende bandbreedte gebruik per milliseconde te berekenen. Door deze metingen te doen, waren we in staat om de oorzaak van de lange netwerk latenties te identificeren. Zoals u in de bovenstaande grafieken kunt zien, vertoont het bandbreedtegebruik per milliseconde korte uitbarstingen van enkele honderden milliseconden per keer die in de buurt van 100 kB/ms komen. Een dergelijke snelheid van 100 kB/ms gedurende een volledige seconde zou gelijk staan aan 100 MB/s, wat 80% is van de theoretische capaciteit van 1 Gbps netwerk interface kaarten! Deze uitbarstingen staan bekend als microbursts en worden gecreëerd door het gedistribueerde database cluster dat in één keer reageert op de cache server, waardoor een volledig gebruikte link ontstaat voor een subseconde tijd. Hieronder staat een grafiek van het bandbreedtegebruik als percentage van 1 Gbps snelheden versus de gemeten latencies gedurende hetzelfde tijdsbestek. Zoals u kunt zien, is er een hoge correlatie tussen latency pieken en het bursty verkeer:
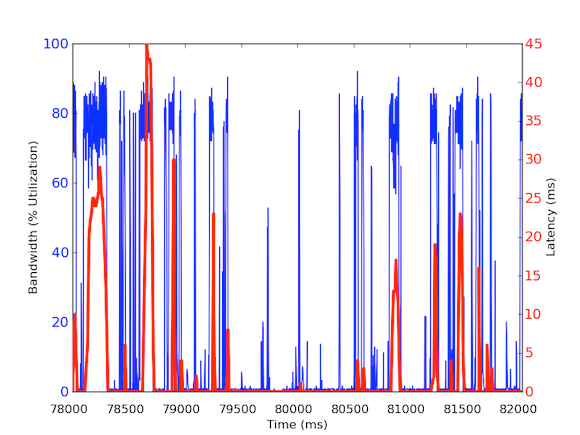
Deze grafieken tonen het belang aan van sub-seconde metingen! Hoewel het moeilijk is om een volledige infrastructuur met dergelijke gegevens te onderhouden, althans voor diep-gravend onderzoek, zou het een go-to-granulariteit moeten zijn, omdat in prestaties, milliseconden er echt toe doen!
Impact van de hoofdoorzaak
Deze hoofdoorzaak heeft een interessant effect op ons gedistribueerde systeem. Over het algemeen houden systemen van een hoge doorvoer, dus een extreem hoge bezettingsgraad is een goede zaak. Maar onze caching server heeft te maken met twee soorten verkeer: (1) hoge doorvoer data uit de database (2) kleine queries van de API laag. Toegegeven, de API Layer verzoeken kunnen de hoge doorvoer data uit de database veroorzaken, maar hier is de sleutel: Het is alleen nodig als het verzoek niet door de cache kan worden voldaan. Als het verzoek in de cache zit, zou de caching server snel gegevens moeten terugsturen zonder te hoeven wachten op database berekeningen. Maar wat gebeurt er als een in de cache opgeslagen verzoek binnenkomt tijdens een microburst voor een niet in de cache opgeslagen verzoek? De microburst kan 30 ms vertraging veroorzaken voor al het andere inkomende verkeer en daardoor kan het cache verzoek een extra 30 ms vertraging oplopen die totaal onnodig is!
Stap 4: Prototype en Valideer
Toen we eenmaal een plausibele hoofdoorzaak hadden gevonden, wilden we onze resultaten valideren. Omdat dit bandbreedte gebruik vertragingen kan veroorzaken bij cache hits, konden we deze aanvragen isoleren van de cache server’s queries naar de database cluster. Om dit te doen hebben we een experimentele omgeving opgezet waar een enkele cache server host twee NICs heeft, elk met hun eigen IP adressen. Met deze setup gaan alle API Layer requests naar de cache server via de ene interface en alle cache server queries naar het database cluster gaan via de andere interface. Het diagram hieronder illustreert dit:

Met deze setup hebben we de volgende latencies gemeten en zoals je kunt zien, zijn de latencies tussen de API Layer en de cache server eigenlijk wat we verwachten – gezond en onder de 1 ms. Latencies met de database cluster kunnen niet worden vermeden zonder verbeterde hardware; omdat we de doorvoer willen maximaliseren, zullen er altijd bursts optreden en dus zullen de pakketten in de wachtrij op de interface worden geplaatst.

Daarom verdient verschillend verkeer verschillende prioriteiten en kan het een ideale oplossing zijn om microbursting verkeer af te handelen. Andere oplossingen zijn het verbeteren van de hardware, zoals het gebruik van 10 Gbps-hardware, het comprimeren van gegevens, of zelfs het gebruik van quality of service.
Het vinden van de hoofdoorzaak van longtails kan moeilijk zijn.
De hoofdoorzaak van longtail latencies kan moeilijk te vinden zijn, omdat ze kortstondig zijn en prestatiemetingen kunnen ontgaan. De meeste prestatiecijfers die we hier bij LinkedIn verzamelen zijn op 1 seconde granulariteiten en sommige op 1 minuut. Maar als we dat in perspectief plaatsen, kunnen longtail latenties die 30 ms duren gemakkelijk gemist worden door metingen met een granulariteit van zelfs 1.000 ms (1 seconde). Niet alleen dat, longtail latencies kunnen te wijten zijn aan verschillende problemen in hardware of software en kunnen vrij moeilijk met wortel en al uit te roeien zijn in een complex gedistribueerd systeem. Enkele voorbeelden van oorzaken kunnen zijn het gebruik van hardwarebronnen die te maken hebben met eerlijkheid, contingentie en verzadiging, of datapatroonkwesties zoals multi-nodale distributies of krachtige gebruikers die longtail latencies veroorzaken voor hun werklasten.
Om samen te vatten raden we sterk aan om deze vier stappen van onze methodologie te onthouden voor toekomstige onderzoeken:
- Heb een gecontroleerde en vereenvoudigde omgeving.
- Geef gedetailleerde end-to-end latency metingen.
- Elimineer en experimenteer.
- Prototypeer en valideer.
Lessen geleerd
- Longtail latency is niet alleen maar ruis! Het kan door verschillende echte redenen komen en de 99ste percentiel verzoeken kunnen de rest van een groot gedistribueerd systeem beïnvloeden.
- Doe het 99e percentiel van latency problemen niet af als power users; als power users zich vermenigvuldigen, zullen de problemen ook toenemen.
- Het afdekken van je weddenschap, hoewel een over het algemeen goede strategie waarbij het systeem twee keer hetzelfde verzoek verstuurt in de hoop op één snelle reactie, helpt niet wanneer de lange wachttijden door de toepassing worden veroorzaakt. In feite maakt het het systeem alleen maar slechter door meer verkeer aan het systeem toe te voegen, wat in ons geval meer microbursts zou veroorzaken. Als we deze strategie hadden toegepast zonder een grondige analyse, zouden we teleurgesteld zijn geweest omdat de systeemprestaties zouden zijn verslechterd en het zou een aanzienlijke hoeveelheid inspanning hebben verspild om een dergelijke oplossing toe te passen.
- Scatter/gather benaderingen kunnen gemakkelijk micro-uitbarstingen van bandbreedtegebruik veroorzaken, waardoor wachtrijvertragingen op het milliseconde-granulariteitsniveau ontstaan.
- Metingen van subseconden zijn noodzakelijk.
- Soms zijn hardwareverbeteringen de meest kosteneffectieve manier om de problemen te helpen verlichten, maar tot die tijd zijn er nog steeds interessante mitigaties die ontwikkelaars kunnen doen, zoals het comprimeren van gegevens of selectief zijn op welke gegevens worden verzonden of gebruikt.
Ten slotte was de belangrijkste les die we leerden het volgen van methodologieën. Methodologieën geven richting aan onderzoeken, vooral wanneer dingen verwarrend worden of beginnen aan te voelen als een reis door Midden-aarde.
Acknowledgements
Ik wil Andrew Carter bedanken voor zijn werk en medewerking tijdens het onderzoek en Steven Callister voor zijn operationele ondersteuning en feedback. Ook dank aan Badri Sridharan, Haricharan Ramachandra, Ritesh Maheshwari, en Zhenyun Zhuang voor hun feedback en suggesties op dit schrijven.