Uwaga? Uwaga!
Uwaga jest dość popularnym pojęciem i przydatnym narzędziem w społeczności głębokiego uczenia w ostatnich latach. W tym poście przyjrzymy się temu, jak wymyślono uwagę, oraz różnym mechanizmom i modelom uwagi, takim jak transformata i SNAIL.
Uwaga jest w pewnym stopniu motywowana tym, jak zwracamy uwagę wzrokową na różne regiony obrazu lub korelujemy słowa w jednym zdaniu. Weźmy za przykład zdjęcie Shiba Inu na Rys. 1.

Fig. 1. Shiba Inu w męskim stroju. The credit of the original photo goes to Instagram @mensweardog.
Ludzka uwaga wzrokowa pozwala nam skupić się na pewnym regionie z „wysoką rozdzielczością” (tj. spójrz na spiczaste ucho w żółtej ramce), jednocześnie postrzegając otaczający obraz w „niskiej rozdzielczości” (tj. teraz co z zaśnieżonym tłem i strojem?), a następnie odpowiednio dostosować punkt centralny lub wykonać wnioskowanie. Biorąc pod uwagę mały fragment obrazu, piksele w pozostałej części dostarczają wskazówek, co powinno być tam wyświetlane. Spodziewamy się zobaczyć spiczaste ucho w żółtej ramce, ponieważ widzieliśmy już nos psa, inne spiczaste ucho po prawej stronie oraz tajemnicze oczy Shiby (rzeczy w czerwonych ramkach). Jednak sweter i koc na dole nie byłyby tak pomocne jak te psie cechy.
Podobnie możemy wyjaśnić związek między słowami w jednym zdaniu lub bliskim kontekście. Kiedy widzimy „jedzenie”, spodziewamy się, że wkrótce napotkamy słowo jedzenie. Kolorowy termin opisuje jedzenie, ale prawdopodobnie nie tak bardzo z „jedzeniem” bezpośrednio.
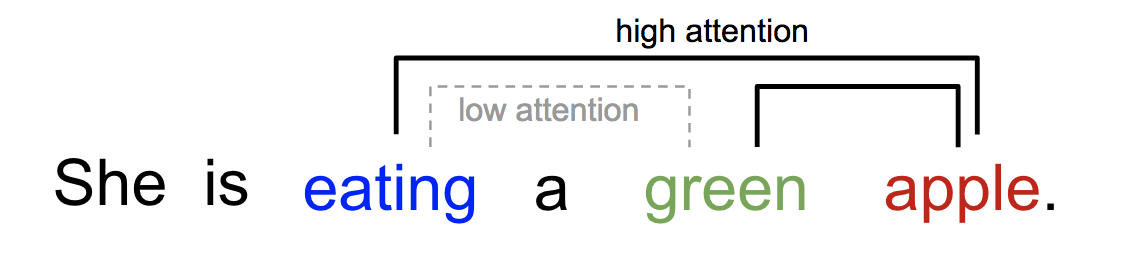
Fig. 2. Jedno słowo „przywiązuje” inaczej do innych słów w tym samym zdaniu.
W skrócie, uwaga w głębokim uczeniu może być szeroko interpretowana jako wektor wag ważności: aby przewidzieć lub wywnioskować jeden element, taki jak piksel w obrazie lub słowo w zdaniu, szacujemy za pomocą wektora uwagi, jak silnie jest on skorelowany z (lub „przywiązuje do”, jak mogłeś przeczytać w wielu pracach) innymi elementami i bierzemy sumę ich wartości ważonych przez wektor uwagi jako przybliżenie celu.
- What’s Wrong with Seq2Seq Model?
- Born for Translation
- Definicja
- A Family of Attention Mechanisms
- Podsumowanie
- Self-Attention
- Soft vs Hard Attention
- Global vs Local Attention
- Neuronowe maszyny Turinga
- Reading and Writing
- Mechanizmy uwagi
- Sieć wskaźnikowa
- Transformator
- Klucz, wartość i zapytanie
- Multi-Head Self-Attention
- Enkoder
- Dekoder
- Pełna architektura
- SNAIL
- Self-Attention GAN
What’s Wrong with Seq2Seq Model?
Model seq2seq narodził się w dziedzinie modelowania języka (Sutskever, et al. 2014). Najogólniej rzecz ujmując, jego celem jest transformacja sekwencji wejściowej (źródłowej) do nowej (docelowej), przy czym obie sekwencje mogą mieć dowolną długość. Przykłady zadań transformacji obejmują tłumaczenie maszynowe między wieloma językami w tekście lub audio, generowanie dialogów pytanie-odpowiedź, a nawet parsowanie zdań w drzewa gramatyczne.
Model seq2seq zwykle ma architekturę kodera-dekodera, składającą się z:
- An koder przetwarza sekwencję wejściową i kompresuje informacje do wektora kontekstu (znanego również jako wektor osadzania zdań lub wektor „myśli”) o stałej długości. Oczekuje się, że ta reprezentacja będzie dobrym podsumowaniem znaczenia całej sekwencji źródłowej.
- Dekoder jest inicjalizowany z wektorem kontekstu, aby emitować przekształcone wyjście. Wczesne prace wykorzystywały jedynie ostatni stan sieci kodera jako stan początkowy dekodera.
Zarówno koder jak i dekoder są rekurencyjnymi sieciami neuronowymi, tj. wykorzystującymi jednostki LSTM lub GRU.
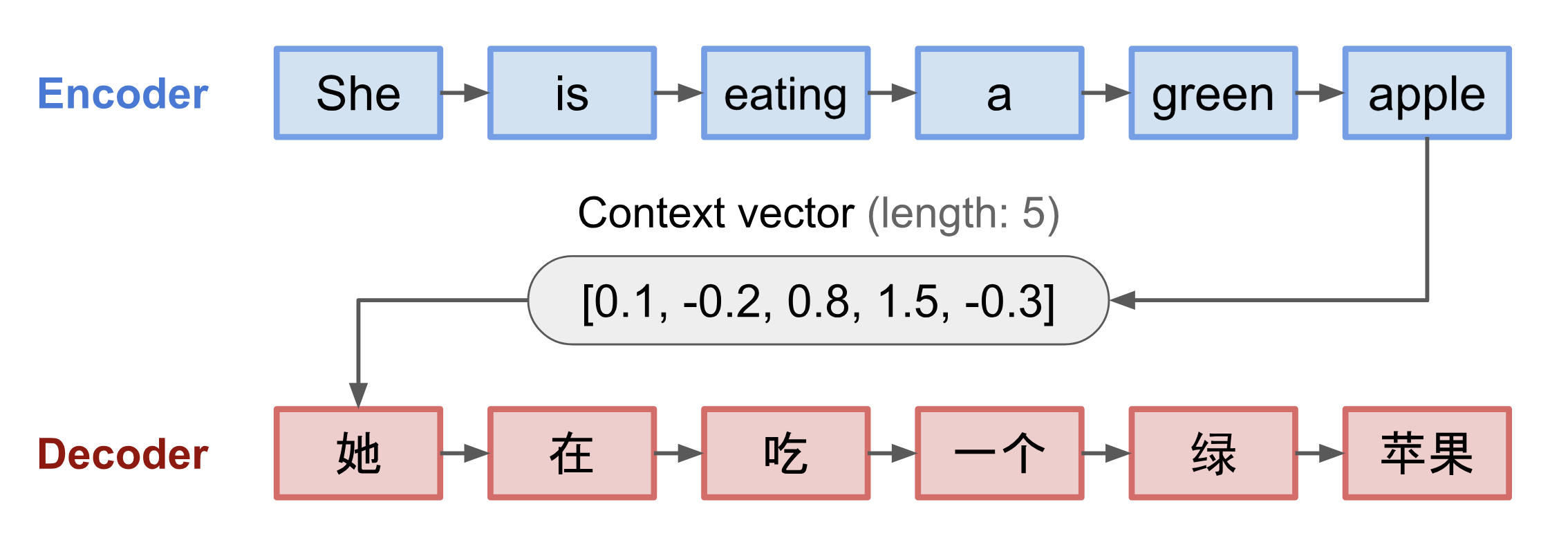
Fig. 3. Model koder-dekoder, tłumaczący na język chiński zdanie „ona je zielone jabłko”. Wizualizacja zarówno kodera jak i dekodera jest rozwijana w czasie.
Krytyczną i oczywistą wadą tej konstrukcji wektora kontekstu o stałej długości jest niezdolność do zapamiętywania długich zdań. Często zapomina on pierwszą część po zakończeniu przetwarzania całego wejścia. Mechanizm uwagi powstał (Bahdanau et al., 2015), aby rozwiązać ten problem.
Born for Translation
Mechanizm uwagi powstał, aby pomóc w zapamiętywaniu długich zdań źródłowych w neuronowym tłumaczeniu maszynowym (NMT). Zamiast budować pojedynczy wektor kontekstu z ostatniego ukrytego stanu kodera, sekretny sos wynaleziony przez uważność polega na tworzeniu skrótów pomiędzy wektorem kontekstu a całym wejściem źródłowym. Wagi tych połączeń skrótowych są konfigurowalne dla każdego elementu wyjściowego.
Podczas gdy wektor kontekstu ma dostęp do całej sekwencji wejściowej, nie musimy się martwić o zapominanie. Wyrównanie między źródłem a celem jest uczone i kontrolowane przez wektor kontekstowy. Zasadniczo wektor kontekstu konsumuje trzy informacje:
- stany ukryte kodera;
- stany ukryte dekodera;
- wyrównanie pomiędzy źródłem i celem.
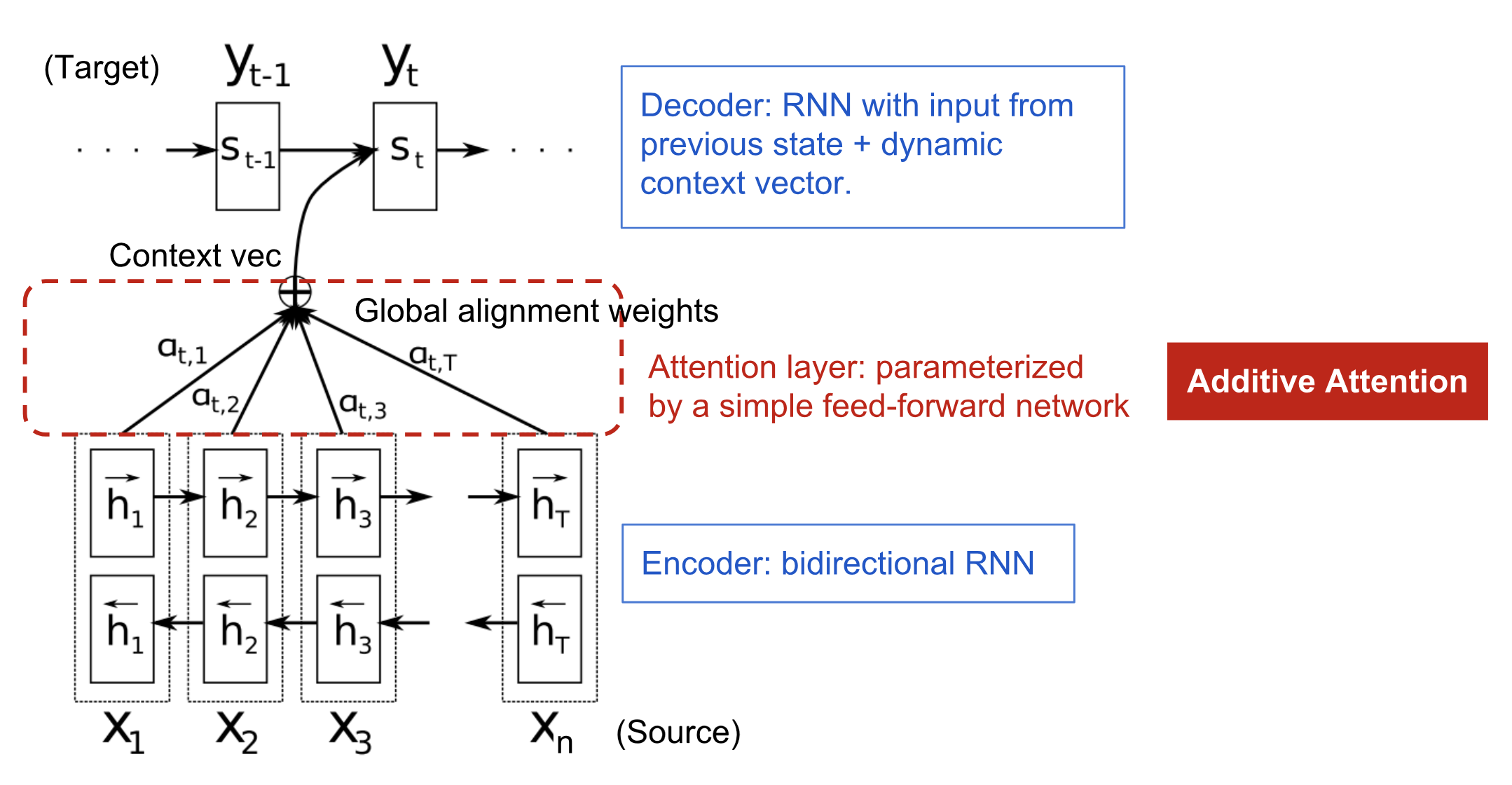
Rys. 4. Model kodera-dekodera z mechanizmem uwagi addytywnej w pracy Bahdanau et al., 2015.
Definicja
\\\\\\\\\\\ &= \end{aligned}]
(Zmienne pogrubione wskazują, że są wektorami; to samo dla wszystkiego innego w tym poście.)
Koder jest dwukierunkową RNN (lub innym ustawieniem sieci rekurencyjnej do wyboru) z forward hidden state \(\overrightarrow{\boldsymbol{h}}_i\) i backward one \(\overleftarrow{\boldsymbol{h}}_i\). Prosta konkatenacja tych dwóch reprezentuje stan kodera. Motywacją jest uwzględnienie zarówno poprzedzających, jak i następujących słów w adnotacji jednego słowa.
gdzie zarówno \(\mathbf{v}_a\), jak i \(\mathbf{W}_a\) są macierzami wagowymi, które mają być nauczone w modelu dopasowania.
Macierz wyników dopasowania jest miłym produktem ubocznym, pozwalającym jednoznacznie pokazać korelację między słowami źródłowymi i docelowymi.

Rys. 5. Macierz dopasowania „L’accord sur l’Espace économique européen a été signé en août 1992” (francuski) i jego angielskiego tłumaczenia „The agreement on the European Economic Area was signed in August 1992”. (Źródło obrazu: Fig 3 in Bahdanau et al., 2015)
Check out this nice tutorial by Tensorflow team for more implementation instructions.
A Family of Attention Mechanisms
Z pomocą uwagi, zależności pomiędzy sekwencjami źródłowymi i docelowymi nie są już ograniczone przez odległość in-between! Biorąc pod uwagę duże usprawnienie przez uwagę w tłumaczeniu maszynowym, wkrótce zostało ono rozszerzone na pole widzenia komputerowego (Xu et al. 2015) i ludzie zaczęli badać różne inne formy mechanizmów uwagi (Luong, et al., 2015; Britz et al., 2017; Vaswani, et al., 2017).
Podsumowanie
Poniżej znajduje się tabela podsumowująca kilka popularnych mechanizmów uwagi i odpowiadające im funkcje alignment score:
Tutaj znajduje się podsumowanie szerszych kategorii mechanizmów uwagi:
| Nazwa | Definicja | Cytowanie |
|---|---|---|
| Self-Attention(&) | Relacja różnych pozycji tej samej sekwencji wejściowej. Teoretycznie samo-uwaga może przyjąć dowolne powyższe funkcje punktowe, ale wystarczy zastąpić sekwencję docelową tą samą sekwencją wejściową. | Cheng2016 |
| Global/Soft | Uwzględnienie całej przestrzeni stanów wejściowych. | Xu2015 |
| Local/Hard | Atendencja do części wejściowej przestrzeni stanów; tj. łaty obrazu wejściowego. | Xu2015; Luong2015 |
(&) Również, określana jako „intra-attention” w Cheng i in, 2016 i kilku innych pracach.
Self-Attention
Self-attention, znany również jako intra-attention, jest mechanizmem uwagi odnoszącym różne pozycje pojedynczej sekwencji w celu obliczenia reprezentacji tej samej sekwencji. Wykazano, że jest ona bardzo przydatna w czytaniu maszynowym, abstrakcyjnym streszczaniu lub generowaniu opisów obrazów.
W artykule dotyczącym sieci pamięci długotrwałej krótkotrwałej wykorzystano samo-uwagę do czytania maszynowego. W poniższym przykładzie mechanizm auto-atencji pozwala na uczenie się korelacji pomiędzy bieżącymi słowami a poprzednią częścią zdania.

Fig. 6. Bieżące słowo jest w kolorze czerwonym, a wielkość niebieskiego cienia wskazuje na poziom aktywacji. (Źródło obrazu: Cheng et al., 2016)
Soft vs Hard Attention
W pracy Show, attend and tell mechanizm uwagi jest stosowany do obrazów w celu wygenerowania podpisów. Obraz jest najpierw kodowany przez CNN w celu wyodrębnienia cech. Następnie dekoder LSTM zużywa cechy konwolucji, aby wyprodukować słowa opisowe jedno po drugim, gdzie wagi są uczone poprzez uwagę. Wizualizacja wag uwagi jasno demonstruje, na które regiony obrazu model zwraca uwagę, aby otrzymać określone słowo.

Fig. 7. „Kobieta rzuca frisbee w parku.” (Źródło obrazu: Rys. 6(b) w Xu et al. 2015)
W artykule tym po raz pierwszy zaproponowano rozróżnienie pomiędzy „miękką” vs „twardą” uwagą, w oparciu o to, czy uwaga ma dostęp do całego obrazu, czy tylko do łaty:
- Miękka uwaga: wagi wyrównania są uczone i umieszczane „miękko” na wszystkich łatach w obrazie źródłowym; zasadniczo ten sam typ uwagi, co w Bahdanau et al., 2015.
- Pro: model jest gładki i różniczkowalny.
- Con: kosztowny, gdy wejście źródłowe jest duże.
- Hard Attention: wybiera tylko jedną łatę obrazu, aby uczestniczyć w tym samym czasie.
- Pro: mniej obliczeń w czasie wnioskowania.
- Con: model jest niezróżnicowany i wymaga bardziej skomplikowanych technik, takich jak redukcja wariancji lub uczenie wzmacniające, aby trenować. (Luong, et al., 2015)
Global vs Local Attention
Luong, et al., 2015 zaproponowali „globalną” i „lokalną” uwagę. Uwaga globalna jest podobna do uwagi miękkiej, natomiast lokalna jest ciekawą mieszanką uwagi twardej i miękkiej, ulepszeniem uwagi twardej, aby była rozróżnialna: model najpierw przewiduje pojedynczą wyrównaną pozycję dla bieżącego słowa docelowego, a okno wyśrodkowane wokół pozycji źródłowej jest następnie używane do obliczenia wektora kontekstu.
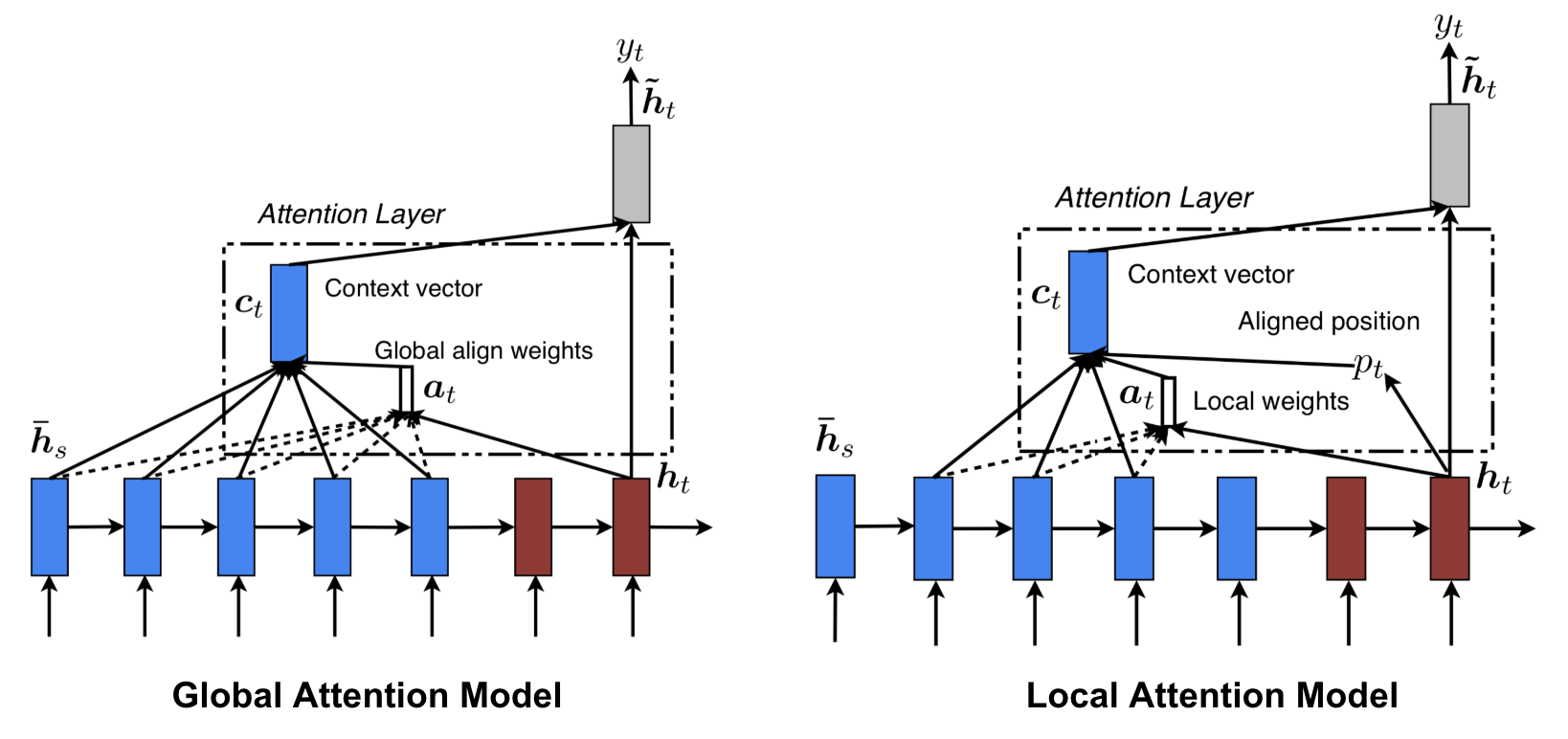
Fig. 8. Global vs local attention (Źródło obrazu: Rys. 2 & 3 w Luong, et al., 2015)
Neuronowe maszyny Turinga
Alan Turing w 1936 roku zaproponował minimalistyczny model obliczeń. Składa się on z nieskończenie długiej taśmy i głowicy, która wchodzi w interakcję z taśmą. Taśma ma na sobie niezliczoną ilość komórek, z których każda wypełniona jest symbolem: 0, 1 lub pustą (” „). Głowica operacyjna może odczytywać symbole, edytować symbole i poruszać się w lewo/w prawo na taśmie. Teoretycznie maszyna Turinga może symulować dowolny algorytm komputerowy, niezależnie od tego, jak skomplikowana lub kosztowna może być ta procedura. Nieskończona pamięć daje maszynie Turinga przewagę, że jest matematycznie nieograniczona. Jednak nieskończona pamięć nie jest możliwa do zastosowania w rzeczywistych współczesnych komputerach i wtedy rozważamy tylko maszynę Turinga jako matematyczny model obliczeń.

Rys. 9. Jak wygląda maszyna Turinga: taśma + głowica, która obsługuje taśmę. (Źródło obrazu: http://aturingmachine.com/)
Neuronowa maszyna Turinga (NTM, Graves, Wayne & Danihelka, 2014) to modelowa architektura sprzężenia sieci neuronowej z zewnętrznym magazynem pamięci. Pamięć naśladuje taśmę maszyny Turinga, a sieć neuronowa kontroluje głowice operacyjne do odczytu z lub zapisu na taśmę. Jednakże, pamięć w NTM jest skończona, a więc prawdopodobnie wygląda bardziej jak „Neuronowa Maszyna von Neumanna”.
NTM zawiera dwa główne komponenty, sieć neuronową kontrolera i bank pamięci. Kontroler: jest odpowiedzialny za wykonywanie operacji na pamięci. Może to być dowolny typ sieci neuronowej, feed-forward lub rekurencyjny.Pamięć: przechowuje przetwarzane informacje. Jest to macierz o rozmiarze \(N \ razy M\), zawierająca N wierszy wektorów, z których każdy ma \(M\) wymiary.
W jednej iteracji aktualizacji kontroler przetwarza dane wejściowe i odpowiednio oddziałuje z bankiem pamięci w celu wygenerowania danych wyjściowych. Interakcja ta jest obsługiwana przez zestaw równoległych głowic odczytujących i zapisujących. Zarówno operacje odczytu, jak i zapisu są „rozmyte” poprzez miękkie uwzględnienie wszystkich adresów pamięci.
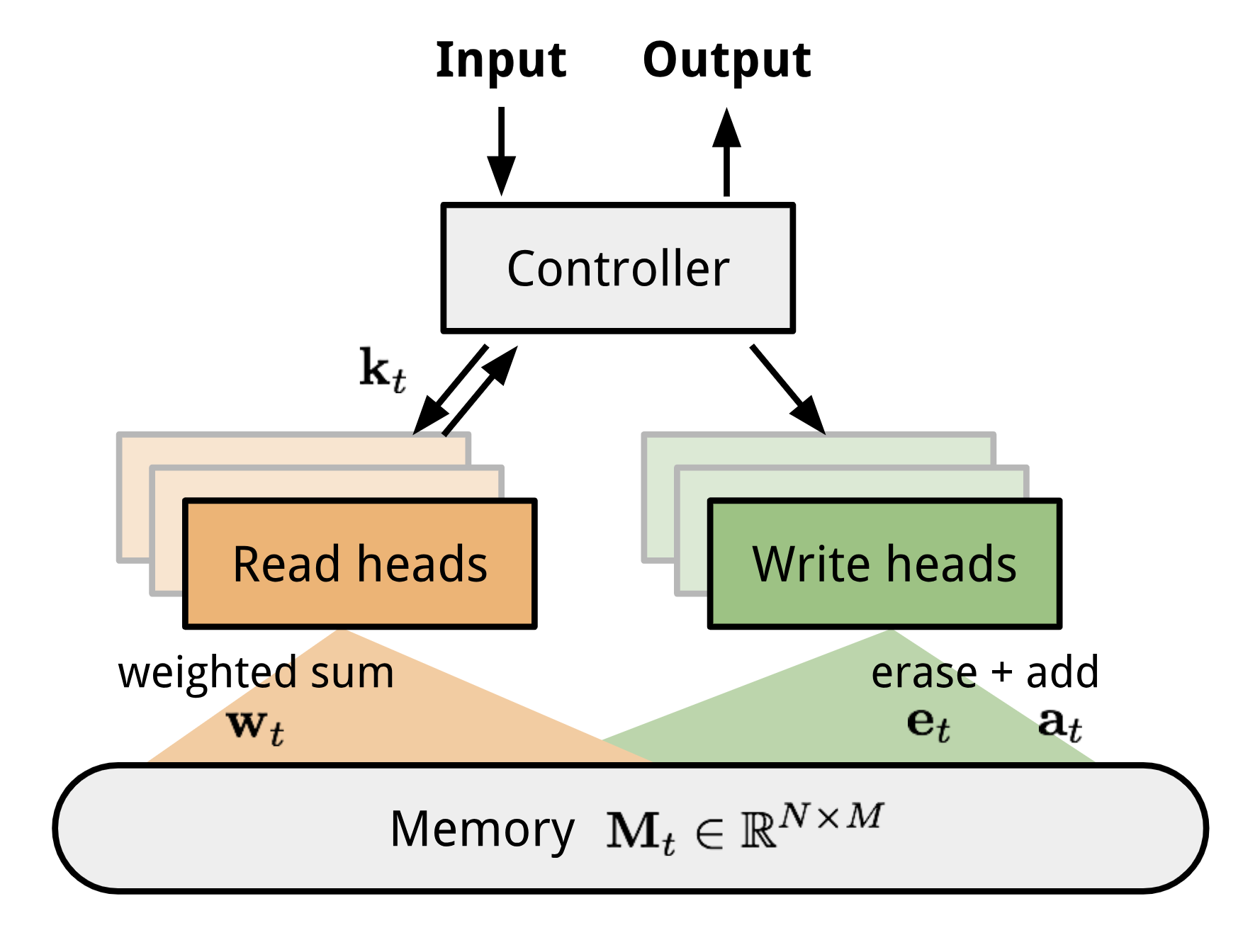
Rys. 10. Architektura neuronowej maszyny Turinga.
Reading and Writing
\>gdzie \(w_t(i)\) jest \t-tym elementem w \(\mathbf{w}_t\), a \(\mathbf{M}_t(i)\) jest \(i)\) wektorem wierszy w pamięci. & \scriptstyle{; erase}} \mathbf{M}_t(i) &= \tilde{mathbf{M}}_t(i) + w_t(i) \mathbf{a}_t & \scriptstyle{; erase}} add}end{aligned}]
Mechanizmy uwagi
W Neuronowej Maszynie Turinga, sposób generowania rozkładu uwagi \(\mathbf{w}_t) zależy od mechanizmów adresowania: NTM wykorzystuje mieszankę adresowania opartego na treści i adresowania opartego na lokalizacji.
Adresowanie oparte na treści
Adresowanie oparte na treści tworzy wektory uwagi na podstawie podobieństwa między wektorem kluczy \(\mathbf{k}_t\) wyodrębnionym przez kontroler z wierszy wejścia i pamięci. Wyniki uwagi oparte na treści są obliczane jako podobieństwo kosinusowe, a następnie normalizowane za pomocą softmax. Dodatkowo NTM dodaje mnożnik siły \(\beta_t\), aby wzmocnić lub stłumić ostrość rozkładu.\) = \frac{exp(\beta_t \frac{mathbf{k}_t \cdot \mathbf{M}_t(i)}} \mathbf{k}_t(i)} \sum_{j=1}^N \exp(\beta_t \frac{mathbf{k}_t \cdot
Interpolacja
Potem bramka interpolacyjna \(g_t) jest używana do mieszania nowo wygenerowanego wektora uwagi opartego na zawartościwektor uwagi oparty na treści z wagami uwagi w ostatnim kroku czasowym:
Adresowanie oparte na lokalizacji
Adresowanie oparte na lokalizacji sumuje wartości na różnych pozycjach w wektorze uwagi, ważone rozkładem wagowym nad dopuszczalnymi przesunięciami całkowitymi. Jest to równoważne konwolucji 1-d z jądrem \(\mathbf{s}_t(.)\), funkcją przesunięcia pozycji. Rozkład ten można zdefiniować na wiele sposobów. Zobacz Rys. 11. dla inspiracji.
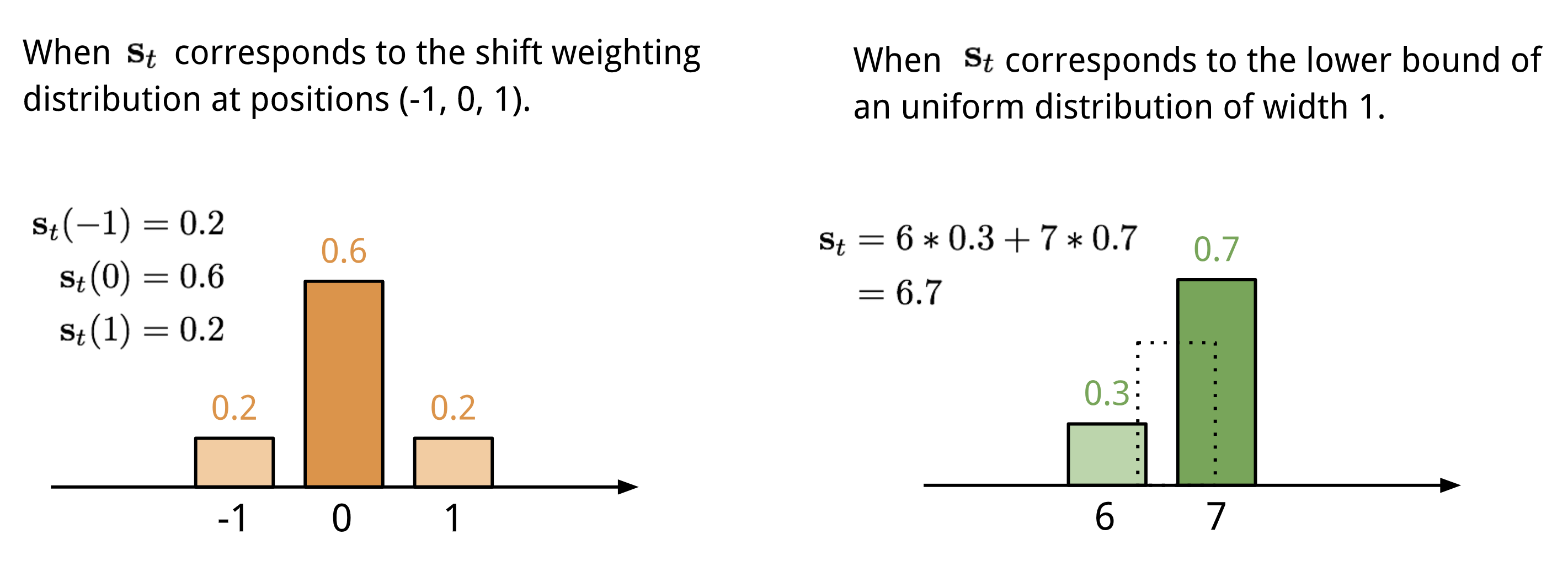
Fig. 11. Dwa sposoby reprezentacji rozkładu wagi przesunięcia \(\mathbf{s}_t\).
W końcu rozkład uwagi jest wzmacniany przez skalar wyostrzający \(\gamma_t \geq 1\).
Pełny proces generowania wektora uwagi \(\mathbf{w}_t\) w kroku czasowym t jest zilustrowany na Rys. 12. Wszystkie parametry wytwarzane przez sterownik są unikalne dla każdej głowicy. Jeśli równolegle istnieje wiele głowic odczytujących i zapisujących, sterownik wyprowadzałby wiele zestawów.
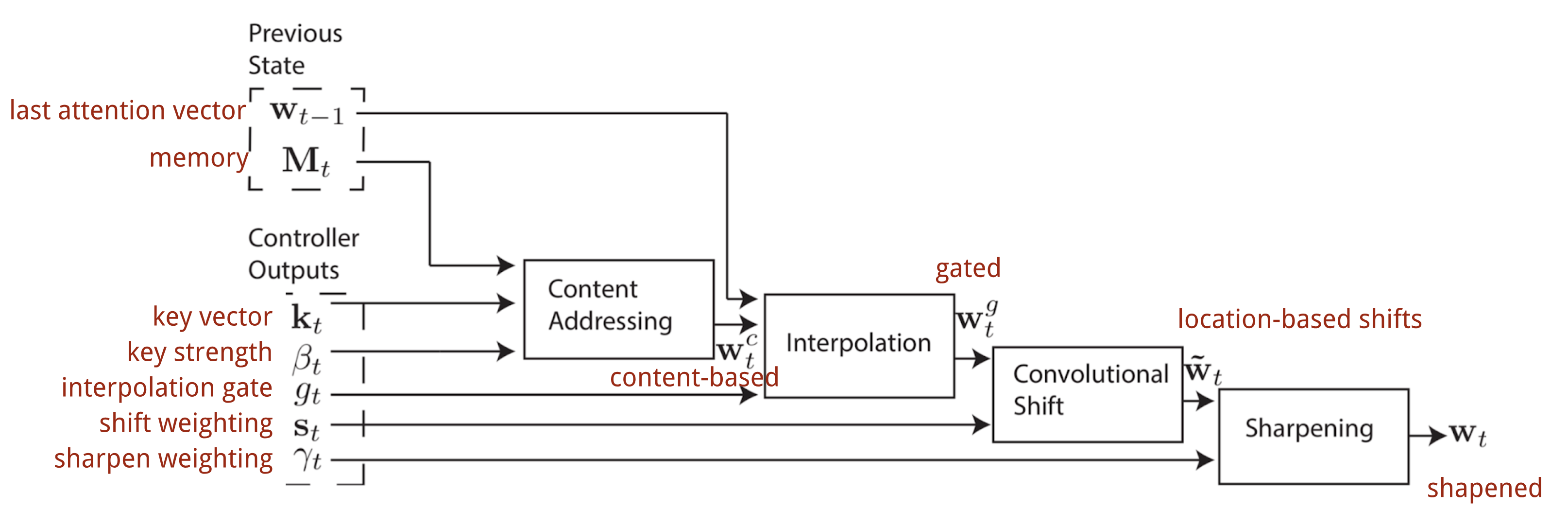
Fig. 12. Schemat przepływu mechanizmów adresowania w Neuronowej Maszynie Turinga. (Źródło obrazu: Graves, Wayne & Danihelka, 2014)
Sieć wskaźnikowa
W problemach takich jak sortowanie czy podróżujący sprzedawca, zarówno wejście, jak i wyjście są danymi sekwencyjnymi. Niestety, nie mogą być one łatwo rozwiązane przez klasyczne modele seq-2-seq lub NMT, biorąc pod uwagę, że dyskretne kategorie elementów wyjściowych nie są z góry określone, lecz zależą od zmiennej wielkości wejściowej. Do rozwiązania tego typu problemów zaproponowano sieć pointerową (Ptr-Net; Vinyals, et al. 2015): Gdy elementy wyjściowe odpowiadają pozycjom w sekwencji wejściowej. Zamiast używać uwagi do mieszania ukrytych jednostek kodera w wektor kontekstu (Patrz Rys. 8), Pointer Net stosuje uwagę nad elementami wejściowymi, aby wybrać jeden jako wyjściowy w każdym kroku dekodera.
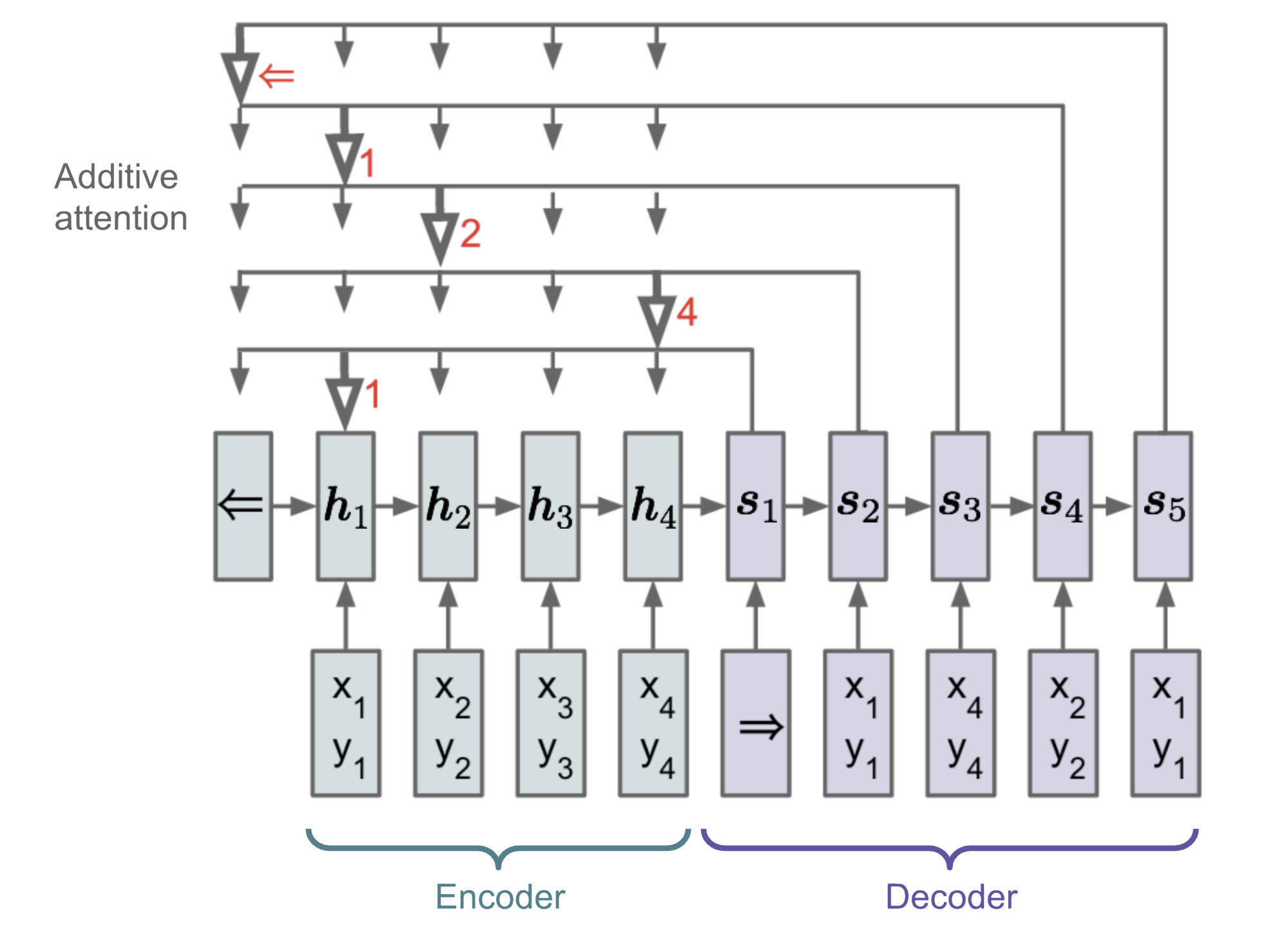
Fig. 13. Architektura modelu sieci wskaźnikowej. (Źródło obrazu: Vinyals, et al. 2015)
Mechanizm uwagi jest uproszczony, ponieważ Ptr-Net nie wtapia stanów kodera w wyjście za pomocą wag uwagi. W ten sposób wyjście reaguje tylko na pozycje, ale nie na treść wejściową.
Transformator
„Attention is All you Need” (Vaswani, et al., 2017), bez wątpienia, jest jednym z najbardziej wpływowych i interesujących papierów w 2017 roku. Przedstawił on wiele ulepszeń do miękkiej uwagi i umożliwia wykonanie modelowania seq2seq bez jednostek sieci rekurencyjnej. Zaproponowany model „transformatora” jest całkowicie zbudowany na mechanizmach samo-uwagi bez użycia architektury rekurencyjnej wyrównanej sekwencyjnie.
Sekretny przepis jest przenoszony w jego architekturze modelu.
Klucz, wartość i zapytanie
Transformator przyjmuje skalowaną uwagę dot-produktową: wyjście jest ważoną sumą wartości, gdzie waga przypisana do każdej wartości jest określona przez iloczyn kropkowy zapytania ze wszystkimi kluczami:
Multi-Head Self-Attention
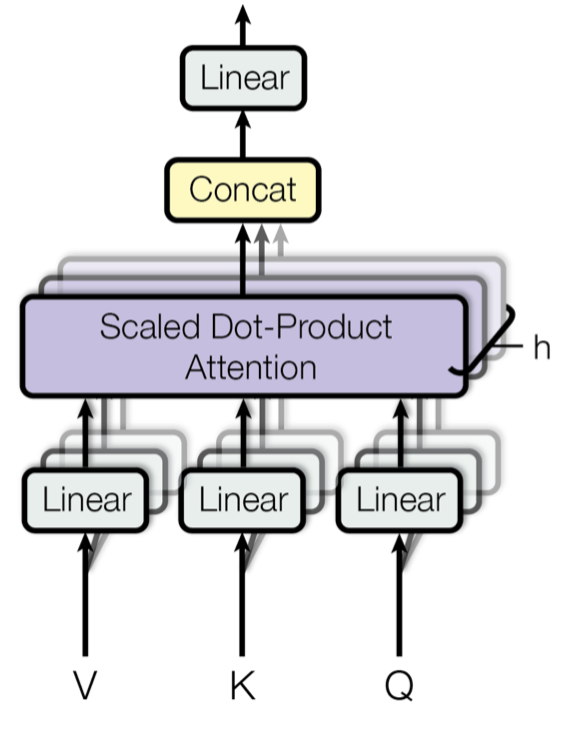
Fig. 14. Wielogłowy skalowany mechanizm uwagi typu dot-product. (Źródło obrazu: Rys. 2 w Vaswani, et al., 2017)
Zamiast obliczać uwagę tylko raz, mechanizm wielogłowicowy przebiega przez skalowaną uwagę punktowo-produktową wielokrotnie równolegle. Niezależne wyjścia uwagi są po prostu konkatenowane i liniowo przekształcane w oczekiwane wymiary. Zakładam, że motywacją jest to, że ensembling zawsze pomaga 😉 Zgodnie z artykułem, „uwaga wielogłowicowa pozwala modelowi wspólnie uczestniczyć w informacjach z różnych podprzestrzeni reprezentacji w różnych pozycjach. Przy pojedynczej głowie uwagi, uśrednianie to hamuje.”
gdzie head}_i &= \tekst{Attention}(\mathbf{Q} \mathbf{W}^Q_i, \mathbf{K} \mathbf{W}^K_i, \mathbf{V} \mathbf{W}^V_i)\end{aligned}]
gdzie \(\mathbf{W}^Q_i\), \(\mathbf{W}^K_i\), \(\mathbf{W}^V_i\) i \(\mathbf{W}^O\) są macierzami parametrów do nauczenia.
Enkoder
![]()
Fig. 15. Enkoder transformatora. (Źródło obrazu: Vaswani, et al., 2017)
Koder generuje reprezentację opartą na uwadze ze zdolnością do zlokalizowania konkretnego fragmentu informacji z potencjalnie nieskończenie dużego kontekstu.
- Stos N=6 identycznych warstw.
- Każda warstwa ma wielogłowicową warstwę samoobsługową i prostą pozycyjną w pełni połączoną sieć feed-forward.
- Każda podwarstwa przyjmuje połączenie resztowe i normalizację warstw.Wszystkie podwarstwy wyprowadzają dane o tym samym wymiarze \(d_tekst{model} = 512).
Dekoder
![]()
Fig. 16. Dekoder transformatora. (Źródło obrazu: Vaswani, et al., 2017)
Dekoder jest w stanie odzyskać dane z zakodowanej reprezentacji.
- Stos N = 6 identycznych warstw
- Każda warstwa ma dwie podwarstwy wielogłowicowych mechanizmów uwagi i jedną podwarstwę w pełni połączonej sieci typu feed-forward.
- Podobnie jak w koderze, każda podwarstwa przyjmuje połączenie szczątkowe i normalizację warstwy.
- Pierwsza podwarstwa wielogłowicowych mechanizmów uwagi jest zmodyfikowana tak, aby uniemożliwić pozycjom uczestniczenie w kolejnych pozycjach, ponieważ nie chcemy patrzeć w przyszłość sekwencji docelowej podczas przewidywania bieżącej pozycji.
Pełna architektura
Wreszcie, oto pełny widok architektury transformatora:
- Zarówno sekwencje źródłowe, jak i docelowe przechodzą najpierw przez warstwy osadzania, aby wytworzyć dane o tym samym wymiarze \(d_tekst{model} =512\).
- Aby zachować informację o położeniu, stosowane jest kodowanie pozycyjne oparte na sinusoidach i sumowane z wyjściem osadzania.
- Do ostatecznego wyjścia dekodera dodawane są softmax i warstwa liniowa.
![]()
Fig. 17. Architektura pełnego modelu transformatora. (Źródło obrazu: Fig 1 & 2 w Vaswani, et al., 2017.)
Próba implementacji modelu transformatora jest ciekawym doświadczeniem, oto moja: lilianweng/transformer-torflow. Przeczytaj komentarze w kodzie, jeśli jesteś zainteresowany.
SNAIL
Transformator nie ma struktury rekurencyjnej ani konwolucyjnej, nawet z kodowaniem pozycyjnym dodanym do wektora osadzania, kolejność sekwencyjna jest tylko słabo włączona. Dla problemów wrażliwych na zależności pozycyjne, takich jak uczenie wzmacniające, może to być duży problem.
Prosty Neural Attention Meta-Learner (SNAIL) (Mishra i in., 2017) został opracowany częściowo w celu rozwiązania problemu z pozycjonowaniem w modelu transformaty poprzez połączenie mechanizmu samo-uwagi w transformacie z czasowymi konwolucjami. Wykazano, że jest on dobry zarówno w zadaniach uczenia nadzorowanego, jak i uczenia wzmacniającego.
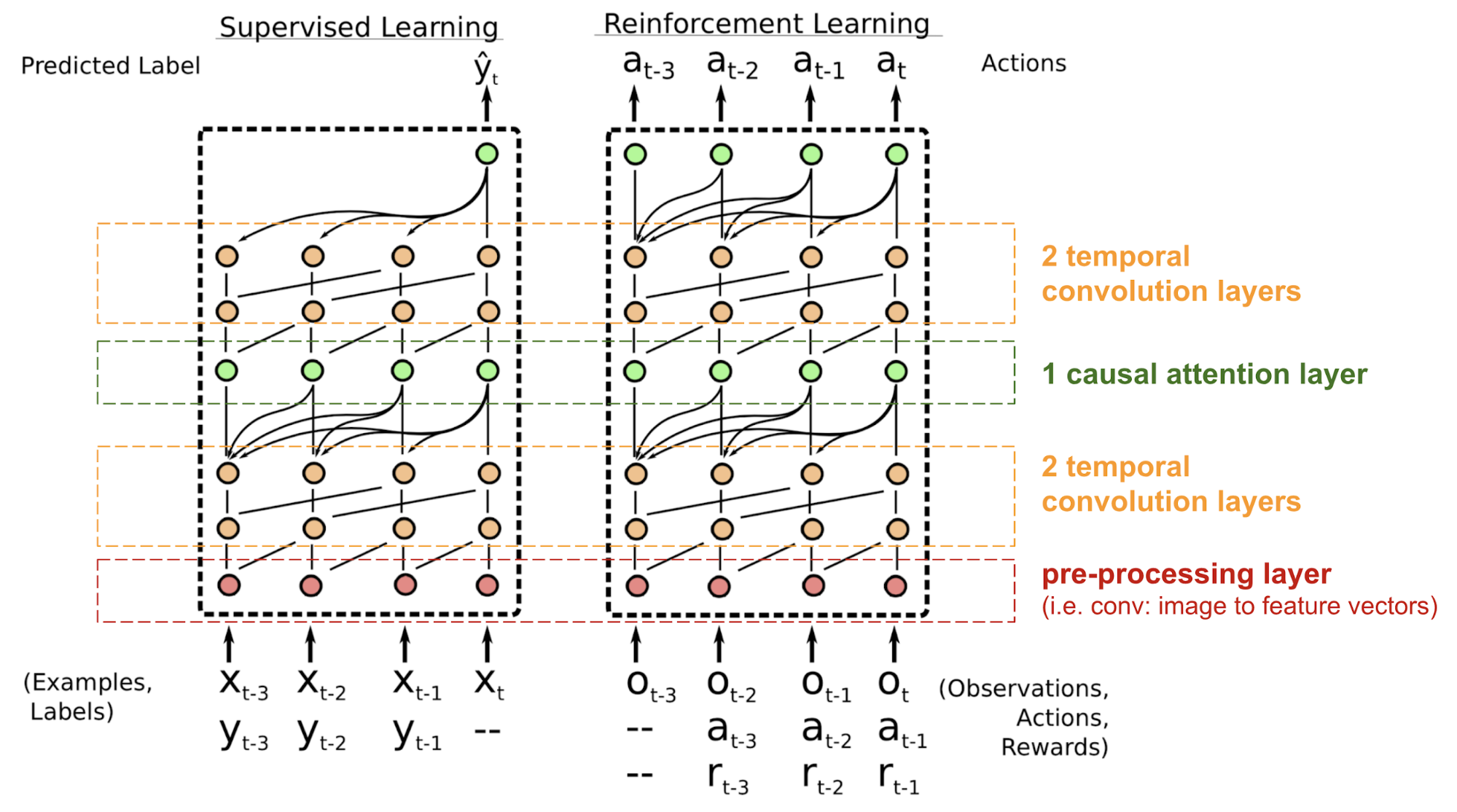
Fig. 18. Architektura modelu SNAIL (Źródło obrazu: Mishra et al., 2017)
SNAIL narodził się na polu meta-uczenia, które jest kolejnym dużym tematem wartym wpisu samego w sobie. Ale w prostych słowach, oczekuje się, że model meta-uczenia się będzie generalizowany do nowych, niewidzianych zadań w podobnej dystrybucji. Przeczytaj to ładne wprowadzenie, jeśli jesteś zainteresowany.
Self-Attention GAN
Self-Attention GAN (SAGAN; Zhang et al., 2018) dodaje warstwy samo-uwagi do GAN, aby umożliwić zarówno generatorowi, jak i dyskryminatorowi lepsze modelowanie relacji między regionami przestrzennymi.
Klasyczny DCGAN (Deep Convolutional GAN) reprezentuje zarówno dyskryminator, jak i generator jako wielowarstwowe sieci konwolucyjne. Jednak możliwości reprezentacji sieci są ograniczone przez rozmiar filtra, ponieważ cecha jednego piksela jest ograniczona do małego lokalnego regionu. Aby połączyć odległe od siebie regiony, cechy muszą być rozcieńczane poprzez warstwy operacji konwolucyjnych, a zależności nie są gwarantowane do zachowania.
Jako że (miękka) auto-atencja w kontekście wizyjnym jest zaprojektowana do jawnego uczenia się relacji pomiędzy jednym pikselem a wszystkimi innymi pozycjami, nawet odległymi od siebie regionami, może ona łatwo uchwycić globalne zależności. Stąd oczekuje się, że GAN wyposażony w auto-atencję będzie lepiej radził sobie ze szczegółami, hurra!
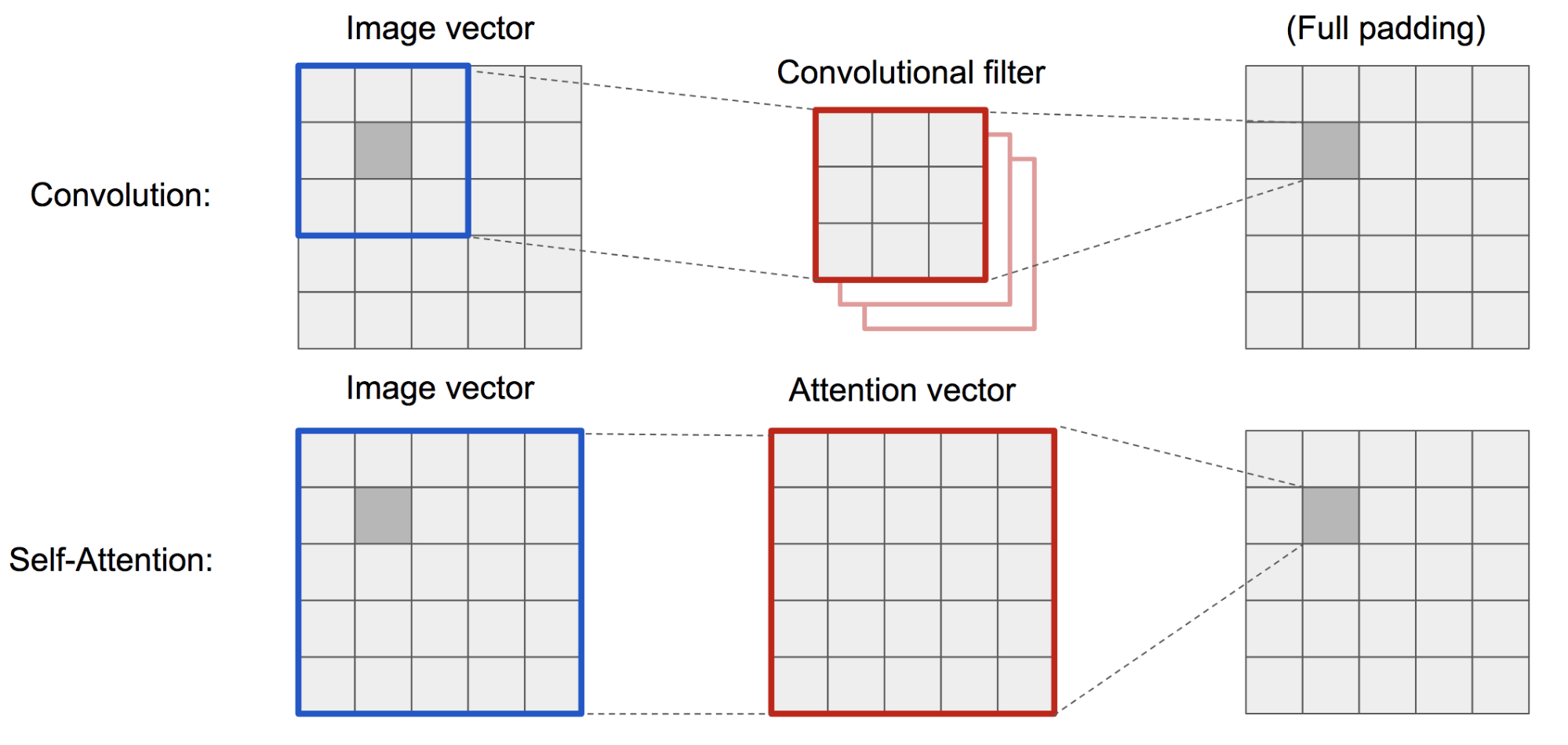
Fig. 19. Operacja konwolucji i auto-atencja mają dostęp do regionów o bardzo różnych rozmiarach.
SAGAN przyjmuje nielokalną sieć neuronową do zastosowania obliczeń uwagi. Konwolucyjne mapy cech obrazu \(\) są rozgałęzione na trzy kopie, odpowiadające pojęciom klucza, wartości i zapytania w transformatorze:
- Klucz: \(f(\mathbf{x}) = \mathbf{W}_f \mathbf{x})
- Kwerenda: \(g(\mathbf{x}) = \mathbf{W}_g \mathbf{x})
- Wartość: \h(h(\mathbf{x}) = \mathbf{W}_h \mathbf{x})
Następnie stosujemy iloczyn kropkowy uwagi, aby wyprowadzić mapy cech samoobserwacji:
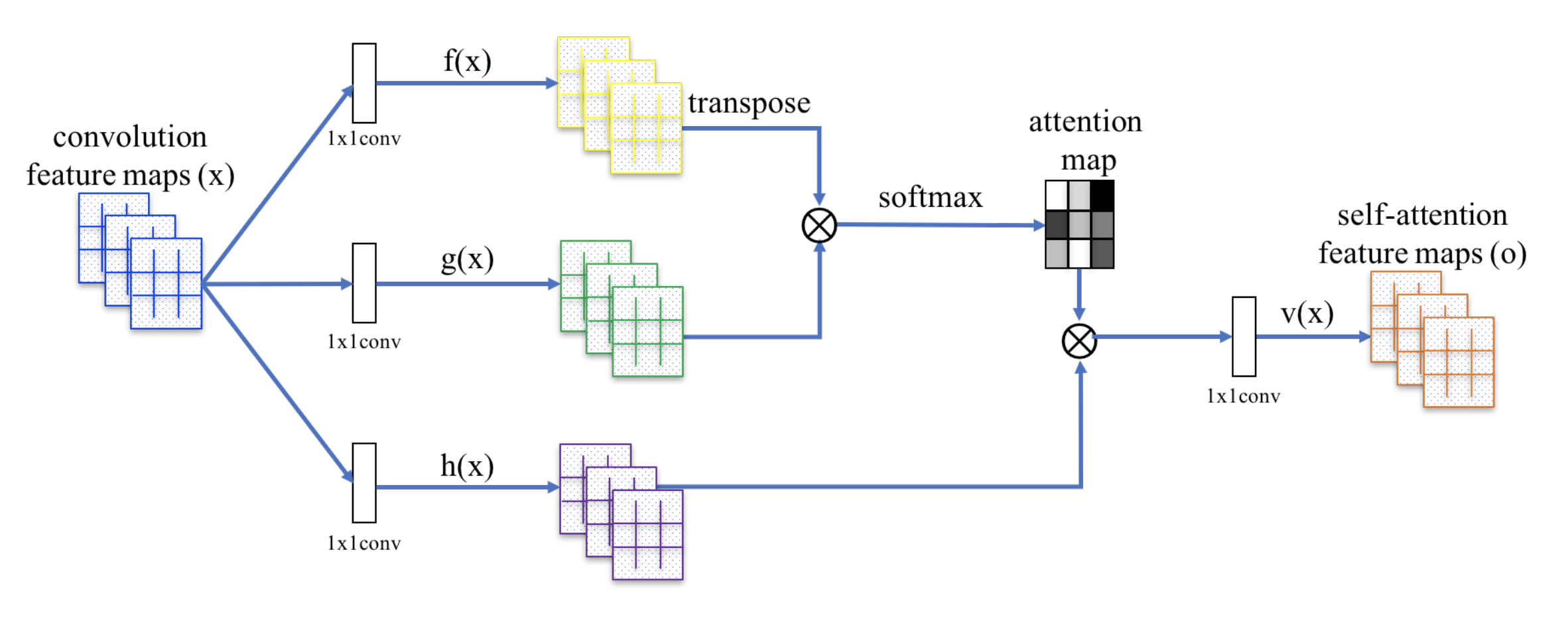
Fig. 20. Mechanizm samo-uwagi w programie SAGAN. (Źródło obrazu: Rys. 2 w Zhang i in, 2018)
Ponadto, wyjście warstwy uwagi jest mnożone przez parametr skalowania i dodawane z powrotem do oryginalnej wejściowej mapy cech:
Podczas gdy parametr skalowania ∗ jest zwiększany stopniowo od 0 podczas treningu, sieć jest skonfigurowana tak, aby najpierw polegać na wskazówkach w lokalnych regionach, a następnie stopniowo uczyć się przypisywać większą wagę regionom, które są dalej.

Fig. 21. Przykładowe obrazy 128×128 wygenerowane przez SAGAN dla różnych klas. (Źródło obrazu: Partial Fig. 6 w Zhang et al., 2018)
Cytowane jako:
Jeśli zauważysz błędy i pomyłki w tym poście, nie wahaj się skontaktować ze mną na , a ja bardzo chętnie od razu je poprawię!
Do zobaczenia w następnym poście 😀
„Attention and Memory in Deep Learning and NLP”. – Jan 3, 2016 by Denny Britz
„Neural Machine Translation (seq2seq) Tutorial”
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. „Neural machine translation by jointly learning to align and translate”. ICLR 2015.
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. „Pokaż, weź udział i powiedz: Neuronowe generowanie podpisów do obrazów z uwagą wzrokową.” ICML, 2015.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. „Sequence to sequence learning with neural networks.” NIPS 2014.
Thang Luong, Hieu Pham, Christopher D. Manning. „Effective Approaches to Attention-based Neural Machine Translation”. EMNLP 2015.
Denny Britz, Anna Goldie, Thang Luong, and Quoc Le. „Massive exploration of neural machine translation architectures” (Masowa eksploracja neuronowych architektur tłumaczenia maszynowego). ACL 2017.
Ashish Vaswani, et al. „Attention is all you need.” NIPS 2017.
Jianpeng Cheng, Li Dong, and Mirella Lapata. „Long short-term memory-networks for machine reading.” EMNLP 2016.
Xiaolong Wang, et al. „Non-local Neural Networks.” CVPR 2018
Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, and Pieter Abbeel. „A simple neural attentive meta-learner.” ICLR 2018.
„WaveNet: A Generative Model for Raw Audio” – Sep 8, 2016 przez DeepMind.
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. „Pointer networks.” NIPS 2015.
Alex Graves, Greg Wayne, and Ivo Danihelka. „Neural turing machines.” arXiv preprint arXiv:1410.5401 (2014).
.