Quem moveu a minha latência do percentil 99?
Co-author: Cuong Tran
Longtail latencies affect members every day and improving the response times of systems even at the 99th percentile is critical to the member’s experience. Podem existir muitas causas, tais como aplicações lentas, acessos lentos ao disco, erros na rede e muitas mais. Encontramos uma causa raiz do tráfego de micro-buscas que não pode ser facilmente resolvida pela estratégia de cobertura da sua aposta, ou seja, o envio do mesmo pedido para vários servidores na esperança de que um dos servidores não seja afetado por latências de cauda longa. Neste próximo post vamos compartilhar a nossa metodologia para causar latências de cauda longa, experiências e lições aprendidas.
Latências de rede entre máquinas dentro de um centro de dados podem ser baixas. Geralmente, toda a comunicação leva alguns microssegundos, mas de vez em quando, alguns pacotes levam alguns milissegundos. Os pacotes que levam alguns milissegundos geralmente pertencem ao percentil 90 ou superior das latências. Latências de cauda longa ocorrem quando esses percentis altos começam a ter valores que vão muito além da média e podem ser magnitudes maiores do que a média. Assim, as latências médias dão apenas metade da história. O gráfico abaixo mostra a diferença entre uma boa distribuição de latências em relação a uma de cauda longa. Como você pode ver, o percentil 99 é 30 vezes pior que a mediana e o percentil 99,9 é 50 vezes pior!
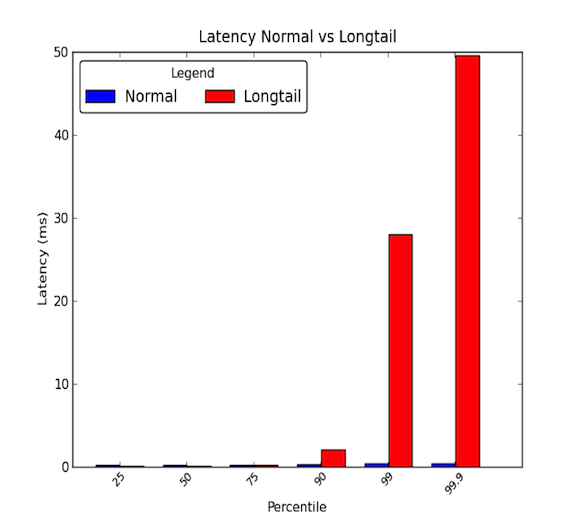
- Detalhes longos realmente importam!
- Case Study
- Passo 1: Tenha um Ambiente Controlado e Simplificado
- Passo 2: Medir Latência de Fim a Fim
- Passo 3: Eliminar e Experimentar
- Micro-explosões, oh meu!
- Impacto da causa raiz
- Passo 4: Protótipo e Validar
- Deve ser difícil encontrar a causa raiz dos longtails.
- Lessons learned
- Agradecimentos
Detalhes longos realmente importam!
Uma latência do percentil 99 de 30 ms significa que a cada 1 em 100 pedidos experimenta 30 ms de atraso. Para um site de alto tráfego como o LinkedIn, isso pode significar que para uma página com 1 milhão de page views por dia, então 10.000 dessas page views experimentam o atraso. No entanto, a maioria dos sistemas hoje em dia são sistemas distribuídos e 1 pedido pode realmente criar vários pedidos downstream. Portanto, 1 pedido pode criar 2 pedidos, ou 10, ou mesmo 100! Se múltiplas requisições downstream atingem um único serviço afetado com latências de cauda longa, nosso problema torna-se mais assustador.
Para ilustrar, digamos que 1 requisição de cliente cria 10 requisições downstream para um subsistema afetado por latências de cauda longa. E suponha que ele tenha 1% de probabilidade de responder lentamente a uma única requisição. Então a probabilidade de pelo menos 1 das 10 solicitações downstream ser afetada pelas latências de cauda longa é equivalente ao complemento de todas as solicitações downstream respondendo rapidamente (99% de probabilidade de responder rapidamente a qualquer solicitação única) que é:

É 9,5 por cento! Isto significa que o pedido de 1 cliente tem quase 10% de chance de ser afetado por uma resposta lenta. Isso equivale a esperar que 100.000 pedidos de clientes sejam afetados de 1 milhão de pedidos de clientes. Isso é um monte de membros!
No entanto, nosso exemplo anterior não considera que membros ativos geralmente navegam mais de uma página e se esse único usuário faz a mesma solicitação de cliente várias vezes, a probabilidade do usuário ser afetado por problemas de latência aumenta drasticamente. Portanto, um serviço backend muito ativo afetado por latências de cauda longa pode ter um sério impacto em todo o site.
Case Study
Tivemos recentemente a oportunidade de investigar um de nossos sistemas distribuídos que experimentou latências de rede de cauda longa. Este problema estava à espreita há alguns meses com investigações rápidas que não mostravam nenhuma razão óbvia para as latências de rede de cauda longa. Decidimos levar a cabo uma investigação mais profunda para enraizar o problema. Neste post de blog, quisemos compartilhar nossa experiência e metodologia que usamos para identificar a causa raiz através do seguinte estudo de caso.
Passo 1: Tenha um Ambiente Controlado e Simplificado
Primeiro montamos um ambiente de teste do sistema de produção real. Simplificamos o sistema para algumas máquinas que poderiam reproduzir as latências de rede de cauda longa. Além disso, desligamos o registro e a persistência dos dados de cache no disco para eliminar o estresse do IO. Isto permitiu-nos concentrar a nossa atenção em componentes-chave, tais como a CPU e a rede. Também nos certificamos de configurar execuções simuladas de tráfego que pudéssemos repetir para ter testes reprodutíveis enquanto realizávamos experimentos e ajustes nos sistemas. O diagrama abaixo mostra nosso ambiente de testes que consistia de uma camada de API, um servidor de cache e um pequeno cluster de banco de dados.

A um alto nível, as solicitações de serviços externos chegam ao sistema distribuído através de uma camada de API. As requisições são então feitas a um servidor de cache para preencher as consultas. Se os dados não estiverem no cache, o servidor de cache fará requisições ao cluster de banco de dados para formar a resposta da consulta.
Passo 2: Medir Latência de Fim a Fim
O próximo passo foi olhar detalhadamente as latências de fim a fim. Ao fazer isso, pudemos tentar isolar nossas latências de cauda longa e ver qual componente em nosso sistema distribuído afetou as latências que estávamos vendo. Durante uma execução de tráfego simulada, usamos o utilitário ping entre os vários pares entre um host de camada API, um host de servidor de cache, e um dos hosts de cluster de banco de dados para medir as latências. O seguinte mostra as latências do percentil 99 entre o par de hosts:

Destas medidas iniciais, concluímos que o servidor de cache tinha o problema das latências de cauda longa. Experimentamos mais para verificar esses resultados e encontramos o seguinte:
- O problema principal foi as latências do percentil 99 para tráfego de entrada para o servidor Cache.
- 99 latências do percentil 99 foram medidas para outras máquinas host no mesmo rack que o servidor cache e nenhum outro host foi afetado.
- 99º percentil latências também foram medidas com tráfego TCP, UDP e ICMP e todo o tráfego de entrada para o Servidor Cache foi afetado.
O passo seguinte foi quebrar a pilha de rede e protocolo do servidor de cache suspeito. Ao fazer isso, esperávamos isolar a parte do servidor de cache que impactou as latências de cauda longa. Nossas medidas de latência de colapso de ponta a ponta são mostradas abaixo:

Fizemos essas medidas implementando uma simples aplicação de pedido/resposta UDP em C e utilizamos o timestamping fornecido pelo sistema Linux para o tráfego de rede. Você pode ver um exemplo na documentação do kernel para as características em timestamping.c para obter informações detalhadas sobre quando os pacotes atingiram a placa de interface de rede e soquetes. Também vale a pena notar que algumas placas de interface de rede fornecem um timestamping de hardware que permite a você obter informações sobre quando os pacotes realmente passam pela placa de interface de rede; no entanto, nem todas as placas suportam isso. Você pode ver este documento da RedHat para mais informações. Nós também usamos tcpdumps no sistema para poder ver quando os pedidos/respostas são processados no nível de protocolo pelo sistema operacional.
Passo 3: Eliminar e Experimentar
Após identificarmos que o problema de latência estava entre o hardware da placa de interface de rede e a camada de protocolo do sistema operacional, nós focamos fortemente nestas porções do sistema. Como a placa de interface de rede (NIC) poderia ter sido um possível problema, decidimos examiná-la primeiro e trabalhar para cima da pilha para eliminar as várias camadas. Ao olharmos para cada componente, tivemos em mente o seguinte: Equidade, Contenções e Saturação. Estas três áreas chave ajudam a encontrar potenciais gargalos ou problemas de latência.
- Fairness: As entidades do sistema estão a receber a sua parte justa de tempo ou recursos para processar ou completar? Por exemplo, cada aplicativo em um sistema está recebendo uma quantidade justa de tempo para ser executado nas CPUs para completar suas tarefas? Se não, a injustiça ou justiça está causando um problema? Por exemplo, talvez uma aplicação de alta prioridade deva ser favorecida em relação a outras; o vídeo em tempo real requer mais tempo para processar do que um trabalho em segundo plano que permita fazer backup dos arquivos para um serviço em nuvem.
- Contenções: As entidades no sistema estão lutando pelo mesmo recurso? Por exemplo, se duas aplicações estão escrevendo em um único disco rígido, ambas as aplicações devem lutar pela largura de banda da unidade. Isto está muito relacionado com a justiça, já que as contenções devem ser resolvidas através de algum tipo de algoritmo de justiça. Contenções podem ser mais fáceis de serem procuradas em vez de uma questão de justiça.
- Saturação: Um recurso está a ser usado ou está a ser completamente utilizado? Se um recurso está sendo usado ou completamente utilizado, podemos atingir alguma limitação que cria contenções ou atrasos, pois as entidades têm que fazer fila para usar os recursos à medida que eles ficam disponíveis.
Quando abordamos o NIC, nos concentramos principalmente em olhar a) se as filas estavam transbordando, o que mostraria como descartes e indicaria possíveis limitações de uso de banda ou b) se havia pacotes mal-formados precisando de retransmissões, o que poderia causar atrasos. Havia 0 descartes e 0 pacotes malformados atingindo o NIC durante nossos experimentos e nosso uso de largura de banda era de aproximadamente 5 – 40 MB/s, o que é baixo em nosso hardware de 1 Gbps.
Next, nós focamos no nível do driver e do protocolo. Essas duas partes foram difíceis de separar; entretanto, gastamos uma boa parte de nossa investigação olhando para diferentes ajustes do sistema operacional que lidavam com agendamento de processos, utilização de recursos para núcleos, manipulação de interrupções de agendamento e afinidade de interrupções para utilizações de núcleos. Essas áreas chave podiam potencialmente causar atrasos no processamento de pacotes de rede e queríamos ter certeza de que os pedidos e respostas estavam sendo atendidos tão rápido quanto a máquina poderia lidar. Infelizmente, a maior parte de nossas experiências não produziu nenhuma causa raiz.
Os sintomas que vimos no início pareciam implicar em um sistema com largura de banda limitada. Quando muito tráfego é produzido, as latências aumentam devido aos atrasos na fila de espera. No entanto, quando olhamos para a camada NIC, não vimos tal problema. Mas depois que eliminamos quase tudo na pilha, percebemos que nossas métricas de desempenho medem em granularidades de 1 segundo ou 1.000 milissegundos. Com uma latência de cauda longa de 30 ms, como poderíamos esperar capturar o problema?
Micro-explosões, oh meu!
Muitos dos nossos sistemas têm placas de interface de rede de 1 Gbps. Quando olhamos para o tráfego de entrada, vimos que o Cache Server geralmente apresentava um tráfego de 5 – 40 MB/s. Este tipo de uso de largura de banda não levanta nenhuma bandeira vermelha; no entanto, e se olhássemos para o uso de largura de banda por milissegundo! O primeiro gráfico abaixo é de uso de largura de banda por segundo e mostra baixo uso, enquanto o segundo gráfico é de uso de largura de banda por milissegundo e mostra uma história completamente diferente.

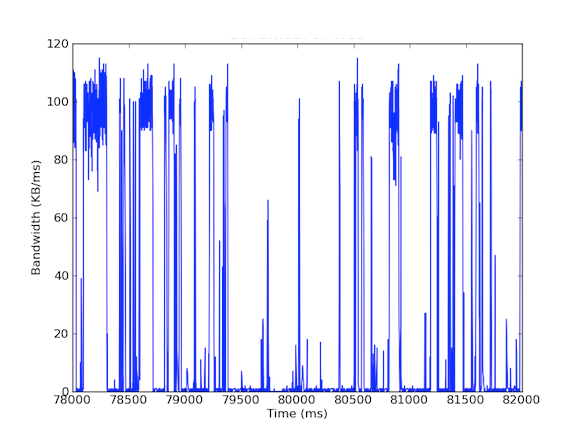
Para medir o tráfego de entrada de largura de banda por milissegundo, nós usamos o tcpdump para reunir o tráfego por um período de tempo definido. Isto exigiu cálculos offline, mas como o tcpdumps tem carimbos de tempo ao nível do microssegundo, fomos capazes de calcular a utilização da largura de banda de entrada por milissegundo. Ao fazer estas medições, fomos capazes de identificar a causa das latências de rede de cauda longa. Como você pode ver nos gráficos acima, a utilização da largura de banda por milissegundo mostra breves estouros de poucas centenas de milissegundos de cada vez que atingem quase 100 kB/ms. Tal taxa de 100 kB/ms sustentados por um segundo completo seria equivalente a 100 MB/s, que é 80% da capacidade teórica de placas de interface de rede de 1 Gbps! Estas explosões são conhecidas como micro explosões e são criadas pelo cluster de banco de dados distribuído respondendo ao servidor de cache de uma só vez, criando assim um link totalmente utilizado para o tempo de subsegundo. Abaixo está um gráfico de utilização da largura de banda como uma percentagem de 1 Gbps de velocidade em relação às latências medidas durante o mesmo período de tempo. Como você pode ver, há uma alta correlação entre os picos de latência e o tráfego de ruptura:
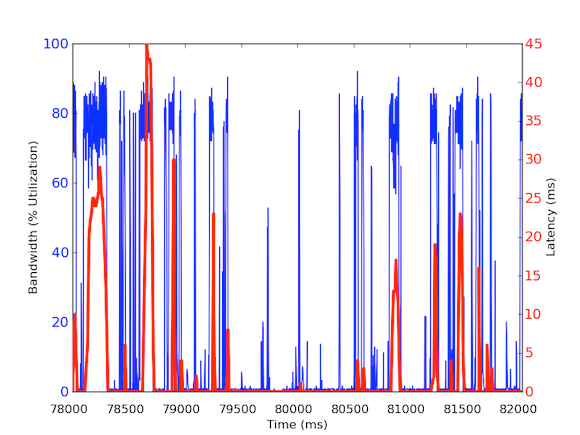
Estes gráficos mostram a importância das medições de subsegundo! Apesar de ser difícil manter uma infra-estrutura completa com tais dados, pelo menos para investigações de dívias profundas, deve ser uma go to granularity porque em performance, milisegundos realmente importam!
Impacto da causa raiz
Esta causa raiz tem um efeito interessante em nosso sistema distribuído. Geralmente sistemas como o de alto rendimento, portanto ter uma utilização extremamente alta é uma coisa boa. Mas o nosso servidor de cache lida com dois tipos de tráfego: (1) dados de alta taxa de transferência da base de dados (2) pequenas consultas a partir da camada da API. É verdade que as solicitações da Camada API podem causar os dados de alta taxa de transferência do banco de dados, mas aqui está a chave: ela só é necessária quando a solicitação não pode ser atendida pelo cache. Se a requisição estiver em cache, o servidor de cache deve retornar os dados rapidamente sem ter que esperar pelos cálculos do banco de dados. Mas o que acontece se uma requisição em cache entrar durante uma resposta de micro-busca para uma requisição não em cache? O microburst pode causar 30 ms de atraso para qualquer outro tráfego de entrada e, portanto, o pedido em cache pode sofrer um atraso extra de 30 ms que é completamente desnecessário!
Passo 4: Protótipo e Validar
Após descobrirmos uma causa raiz plausível, queríamos validar os nossos resultados. Uma vez que este uso de largura de banda pode causar atrasos nos acessos ao cache, pudemos isolar estas requisições das consultas do servidor de cache para o cluster da base de dados. Para fazer isso, criamos um ambiente experimental onde um único servidor de cache tem duas placas de rede, cada uma com seus próprios endereços IP. Com esta configuração, todas as requisições de camadas de API para o servidor de cache passam por uma interface e todas as consultas do servidor de cache para o cluster de banco de dados passam pela outra interface. O diagrama abaixo ilustra isso:

Com essa configuração, medimos as latências a seguir e, como você pode ver, as latências entre a camada de API e o servidor de cache são na verdade o que esperamos – saudáveis e abaixo de 1 ms. Latências com o cluster de banco de dados não podem ser evitadas sem um hardware melhorado; porque queremos maximizar a taxa de transferência, sempre ocorrerão estouros e assim os pacotes serão enfileirados na interface.

Por isso, um tráfego diferente merece prioridades diferentes e pode ser uma solução ideal para lidar com o tráfego de micro explosão. Outras soluções incluem a melhoria do hardware, como o uso de hardware de 10 Gbps, compressão de dados ou mesmo o uso de qualidade de serviço.
Deve ser difícil encontrar a causa raiz dos longtails.
A causa raiz das latências de cauda longa pode ser difícil de encontrar, pois são efêmeras e podem iludir as métricas de desempenho. A maioria das métricas de desempenho que coletamos aqui no LinkedIn estão em granularidades de 1 segundo e algumas em 1 minuto. No entanto, levando isso em perspectiva, latências de cauda longa que duram 30 ms podem ser facilmente perdidas por medições com granularidades de até 1.000 ms (1 segundo). Não só isso, as latências de cauda longa podem ser devidas a diferentes problemas de hardware ou software e podem ser bastante difíceis de enraizar em um sistema distribuído complexo. Alguns exemplos de causas podem ser o uso de recursos de hardware lidando com justiça, contenção e saturação, ou problemas de padrões de dados como distribuições multi-nodais ou usuários de energia causando latências de cauda longa para suas cargas de trabalho.
Para resumir, nós encorajamos fortemente a lembrar estes quatro passos de nossa metodologia para investigações futuras:
- Dispor de um ambiente controlado e simplificado.
- Encerrar medições detalhadas de latência de ponta a ponta.
- Eliminar e experimentar.
- Protótipo e validar.
Lessons learned
- Longtail latency is not just noise! Pode ser devido a diferentes razões reais e as solicitações do percentil 99 podem afetar o resto de um sistema distribuído de grande porte.
- Não desconte o percentil 99 de problemas de latência como usuários de energia; como usuários de energia se multiplicam, os problemas também se multiplicarão.
- Abtendo sua aposta embora uma estratégia geralmente boa onde o sistema envia o mesmo pedido duas vezes na esperança de uma resposta rápida não ajuda quando as latências de cauda longa são induzidas pela aplicação. Na verdade, apenas piora o sistema ao adicionar mais tráfego ao sistema o que, no nosso caso, causaria mais micro explosões. Se tivéssemos implementado esta estratégia sem uma análise completa, teríamos ficado decepcionados porque o desempenho do sistema teria sido degradado e teria desperdiçado uma quantidade considerável de esforços para implementar tal solução.
- Reuniões de dispersão podem facilmente causar micro explosões de uso de largura de banda, causando atrasos de fila na granularidade de milissegundos.
- Medidas de granularidade de subsegundo são necessárias.
- Algumas vezes melhorias de hardware são a maneira mais econômica de ajudar a aliviar os problemas, mas até lá, ainda há mitigações interessantes que os desenvolvedores podem fazer, tais como comprimir dados ou ser seletivo sobre quais dados são enviados ou usados.
Finalmente, a lição mais importante que aprendemos foi a de seguir a metodologia. As metodologias dão direção às investigações, especialmente quando as coisas se tornam confusas ou começam a parecer uma viagem pela Terra Média.
Agradecimentos
Gostaria de agradecer a Andrew Carter pelo seu trabalho e colaboração durante a investigação e a Steven Callister por fornecer suporte operacional e feedback. Agradeço também a Badri Sridharan, Haricharan Ramachandra, Ritesh Maheshwari e Zhenyun Zhuang pelo seu feedback e sugestões sobre este escrito.