Vem flyttade min 99:e percentilfördröjning?
Medförfattare: Cuong Tran
Longtail latencies påverkar medlemmarna varje dag och att förbättra svarstiderna i systemen även vid 99:e percentilen är avgörande för medlemmens upplevelse. Det kan finnas många orsaker, t.ex. långsamma program, långsamma diskåtkomster, fel i nätverket och många fler. Vi har stött på en grundorsak till mikrobristande trafik som inte enkelt kan lösas med hedging your bet-strategin, dvs. att skicka samma begäran till flera servrar i hopp om att en av servrarna inte kommer att påverkas av longtail latencies. I följande inlägg kommer vi att dela med oss av vår metodik för att hitta orsaken till longtail latenser, erfarenheter och lärdomar.
Nätverkslatenser mellan maskiner inom ett datacenter kan vara låga. I allmänhet tar all kommunikation några mikrosekunder, men då och då tar vissa paket några millisekunder. De paket som tar några millisekunder hör i allmänhet till den 90:e percentilen eller högre av latenstider. Longtail latencies uppstår när dessa höga percentiler börjar få värden som går långt utöver genomsnittet och kan vara storleksmässigt större än genomsnittet. De genomsnittliga latenstiderna ger alltså bara halva sanningen. Grafen nedan visar skillnaden mellan en bra latensfördelning och en med en lång svans. Som du kan se är den 99:e percentilen 30 gånger värre än medianen och den 99,9:e percentilen är 50 gånger värre!
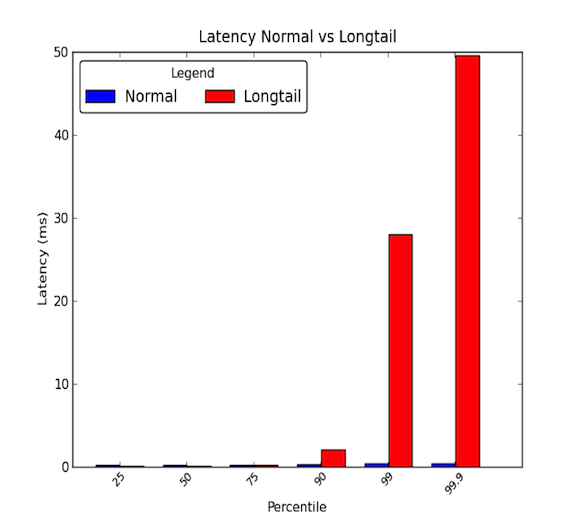
- Longtails spelar verkligen roll!
- Fallstudie
- Steg 1: Ha en kontrollerad och förenklad miljö
- Steg 2: Mätning av end-to-end-latency
- Steg 3: Eliminera och experimentera
- Microbursts, oh my!
- Impact of Root Cause
- Steg 4: Prototyp och validering
- Det kan vara svårt att hitta grundorsaken till longtails.
- Lärdomar
- Acknowledgements
Longtails spelar verkligen roll!
En 99:e percentil latenstid på 30 ms innebär att varannan av 100 förfrågningar drabbas av 30 ms försening. För en webbplats med mycket trafik som LinkedIn kan det innebära att för en sida med 1 miljon sidvisningar per dag kan det innebära att 10 000 av dessa sidvisningar drabbas av fördröjningen. De flesta system i dag är dock distribuerade system och en förfrågan kan faktiskt skapa flera förfrågningar i efterföljande led. En begäran kan alltså ge upphov till 2, 10 eller till och med 100 begäranden! Om flera nedströmsförfrågningar träffar en enda tjänst som drabbas av longtail latencies blir vårt problem mer skrämmande.
För att illustrera detta, låt oss säga att 1 klientförfrågan skapar 10 nedströmsförfrågningar till ett delsystem som drabbas av longtail latency. Och anta att det har 1 % sannolikhet att svara långsamt på en enskild begäran. Då är sannolikheten att minst 1 av de 10 nedströmsförfrågningarna påverkas av longtail latenstiderna likvärdig med komplementet av alla nedströmsförfrågningar som svarar snabbt (99 procents sannolikhet att svara snabbt på en enskild förfrågan), vilket är:

Det är 9,5 procent! Detta innebär att 1 klientförfrågan har en nästan 10-procentig chans att påverkas av ett långsamt svar. Det motsvarar att förvänta sig att 100 000 klientförfrågningar påverkas av 1 miljon klientförfrågningar. Det är många medlemmar!
Vårt exempel tar dock inte hänsyn till att aktiva medlemmar i allmänhet bläddrar på mer än en sida och om en enskild användare gör samma klientförfrågan flera gånger ökar sannolikheten för att användaren påverkas av latensproblem dramatiskt. Därför kan en mycket aktiv backend-tjänst som påverkas av longtail latencies få allvarliga konsekvenser för hela webbplatsen.
Fallstudie
Vi fick nyligen möjlighet att undersöka ett av våra distribuerade system som drabbades av longtail nätverkslatencies. Problemet hade legat på lur i några månader och ytliga undersökningar visade inte på några uppenbara orsaker till de långa nätverksfördröjningarna. Vi bestämde oss för att göra en mer djupgående undersökning för att hitta orsaken till problemet. I det här blogginlägget ville vi dela med oss av våra erfarenheter och den metod som vi använde för att identifiera grundorsaken genom följande fallstudie.
Steg 1: Ha en kontrollerad och förenklad miljö
Vi satte först upp en testmiljö av det faktiska produktionssystemet. Vi förenklade systemet till ett fåtal maskiner som kunde reproducera de långa nätverksfördröjningarna. Dessutom stängde vi av loggning och persistance cache data på disken för att eliminera IO-stress. Detta gjorde det möjligt för oss att fokusera vår uppmärksamhet på nyckelkomponenter som processor och nätverk. Vi såg också till att ställa in simulerade trafikkörningar som vi kunde upprepa för att få reproducerbara tester medan vi utförde experiment och inställningar på systemen. Diagrammet nedan visar vår testmiljö som bestod av ett API-skikt, en cache-server och ett litet databaskluster.

På en hög nivå kommer förfrågningar från externa tjänster in till det distribuerade systemet via ett API-skikt. Förfrågningar skickas sedan till en cacheserver för att uppfylla förfrågningar. Om data inte finns i cacheminnet gör cacheservern förfrågningar till databasklustret för att bilda frågesvaret.
Steg 2: Mätning av end-to-end-latency
Nästa steg var att titta på detaljerade end-to-end-latencies. På så sätt kunde vi försöka isolera våra longtailfördröjningar och se vilken komponent i vårt distribuerade system som påverkade de fördröjningar vi såg. Under en simulerad trafikkörning använde vi verktyget ping mellan de olika paren mellan en värd för API-skiktet, en värd för cache-servern och en av värdarna för databasklustret för att mäta latenstiderna. Följande visar den 99:e percentilen av latenstiderna mellan värdparen:

Utifrån dessa inledande mätningar drog vi slutsatsen att det var cacheserveren som hade problemet med latenstiderna med långa svansar. Vi experimenterade mer för att verifiera dessa resultat och fann följande:
- Det största problemet var 99:e percentilens latenser för inkommande trafik till cacheserveren.
- 99th percentile latencies mättes till andra värddatorer i samma rack som cache-servern och inga andra värddatorer påverkades.
- 99th percentile latencies mättes sedan också med TCP-, UDP- och ICMP-trafik och all inkommande trafik till Cache Server påverkades.
Nästa steg var att bryta ner nätverket och protokollstacken för den misstänkta cache-servern. Genom att göra detta hoppades vi kunna isolera den del av cache-servern som påverkade longtailfördröjningarna. Våra mätningar av latenstider från slut till slut visas nedan:

Vi utförde dessa mätningar genom att implementera en enkel UDP-förfrågan/respons-applikation i C och använde tidsstämpling som tillhandahålls av Linux-systemet för nätverkstrafik. Du kan se ett exempel i kärnans dokumentation för funktionerna i timestamping.c för att få detaljerad information om när paketen träffade nätverksgränssnittskortet och socklarna. Det är också värt att notera att vissa nätverksgränssnittskort tillhandahåller hårdvarutidsstämpling som gör det möjligt att få information om när paketen faktiskt passerar genom nätverksgränssnittskortet; alla kort har dock inte stöd för detta. Du kan se detta dokument från RedHat för mer information. Vi använde också tcpdumps på systemet för att kunna se när förfrågningar/svar behandlas på protokollnivå av operativsystemet.
Steg 3: Eliminera och experimentera
När vi identifierat att latensproblemet fanns mellan nätverksgränssnittskortens hårdvara och operativsystemets protokollskikt fokuserade vi starkt på dessa delar av systemet. Eftersom nätverksgränssnittskortet (NIC) kunde ha varit ett möjligt problem bestämde vi oss för att undersöka det först och arbeta oss uppåt i stapeln för att eliminera de olika lagren. När vi undersökte varje komponent hade vi följande i åtanke: Rättvisa, konkurrens och mättnad. Dessa tre nyckelområden hjälper till att hitta potentiella flaskhalsar eller latensproblem.
- Rättvisa: Får enheterna i systemet en rättvis andel av tiden eller resurserna för att bearbeta eller slutföra en process? Får till exempel varje program i ett system en rimlig mängd tid att köra på processorerna för att slutföra sina uppgifter? Om inte, orsakar orättvisan eller rättvisan ett problem? Till exempel kanske ett högprioriterat program bör gynnas framför andra; video i realtid kräver mer tid att bearbeta än ett bakgrundsjobb som gör att du kan säkerhetskopiera filer till en molntjänst.
- Tvister: Kämpar enheter i systemet om samma resurs? Om t.ex. två program skriver till en enda hårddisk måste båda programmen slåss om bandbredden på hårddisken. Detta har stor betydelse för rättvisan eftersom tvister måste lösas med hjälp av någon form av algoritm för rättvisan. Det kan vara lättare att leta efter tvister i stället för en rättvisefråga.
- Mättnad: Är en resurs överutnyttjad eller helt utnyttjad? Om en resurs är överutnyttjad eller helt utnyttjad kan vi stöta på en begränsning som skapar tvister eller förseningar eftersom enheterna måste ställa sig i kö för att använda resurserna när de blir tillgängliga.
När vi tog itu med NIC fokuserade vi främst på att titta på a) om köerna var överfulla, vilket skulle visa sig som kassationer och indikera eventuella begränsningar i bandbreddsutnyttjandet eller b) om det fanns några missbildade paket som behövde sändas om, vilket skulle kunna orsaka förseningar. Det fanns 0 diskar och 0 missbildade paket som nådde NIC under våra experiment och vår bandbreddsanvändning var ungefär 5 – 40 MB/s, vilket är lågt på vår 1 Gbps-hårdvara.
Nästan fokuserade vi på drivrutins- och protokollnivå. Dessa två delar var svåra att separera, men vi ägnade en stor del av vår undersökning åt att titta på olika inställningar av operativsystemet som handlade om processplanering, resursutnyttjande för kärnor, schemaläggning av avbrottshantering och avbrottsaffinitet för kärnutnyttjande. Dessa nyckelområden kan potentiellt orsaka fördröjningar i behandlingen av nätverkspaket och vi ville försäkra oss om att förfrågningar och svar behandlas så snabbt som maskinen kan hantera. Tyvärr gav de flesta av våra experiment ingen grundorsak.
Symtomen vi såg i början verkade antyda ett system med begränsad bandbredd. När mycket trafik produceras ökar latenstiderna på grund av köfördröjningar. Men när vi tittade på NIC-skiktet såg vi inget sådant problem. Men efter att vi eliminerat nästan allt i stacken insåg vi att våra prestandamätningar mäter i granulariteter på 1 sekund eller 1 000 millisekunder. Med en longtail latenstid på 30 ms, hur skulle vi då kunna hoppas på att upptäcka problemet?
Microbursts, oh my!
Många av våra system har nätverksgränssnittskort på 1 Gbps. När vi tittade på den inkommande trafiken såg vi att Cache Server i allmänhet hade 5-40 MB/s trafik. Denna typ av bandbreddsanvändning ger inte upphov till några röda flaggor, men vad händer om vi tittar på bandbreddsanvändning per millisekund? Den första grafen nedan visar bandbreddsanvändning per sekund och visar låg användning, medan den andra grafen visar bandbreddsanvändning per millisekund och visar en helt annan historia.

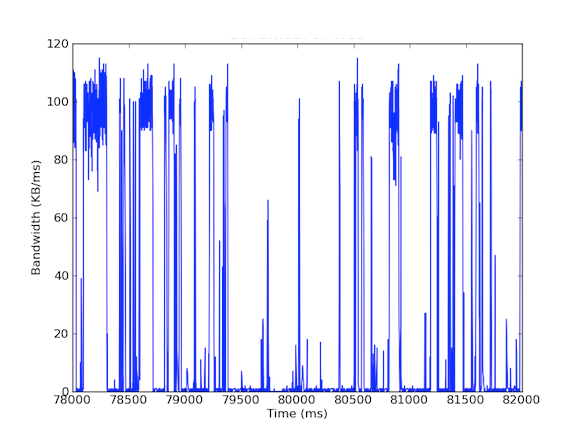
För att mäta inkommande bandbreddstrafik per millisekund använde vi tcpdump för att samla in trafiken under en viss tidsperiod. Detta krävde offlineberäkningar, men eftersom tcpdumps har tidsstämplar på mikrosekundsnivå kunde vi beräkna den inkommande bandbreddsanvändningen per millisekund. Genom att göra dessa mätningar kunde vi identifiera orsaken till de långa nätverksfördröjningarna. Som ni kan se i graferna ovan visar bandbreddsanvändningen per millisekund korta utbrott på några hundra millisekunder i taget som når nära 100 kB/ms. En sådan hastighet på 100 kB/ms under en hel sekund skulle motsvara 100 MB/s, vilket är 80 % av den teoretiska kapaciteten hos nätverksgränssnittskort med 1 Gbps! Dessa störningar kallas microbursts och skapas av det distribuerade databasklustret som svarar på cacheserveren på en gång, vilket skapar en fullt utnyttjad länk under subsekunder. Nedan visas ett diagram över bandbreddsutnyttjandet i procent av 1 Gbps-hastigheterna i förhållande till de latenser som uppmättes under samma tidsram. Som du kan se finns det en hög korrelation mellan latensspikar och den burstartade trafiken:
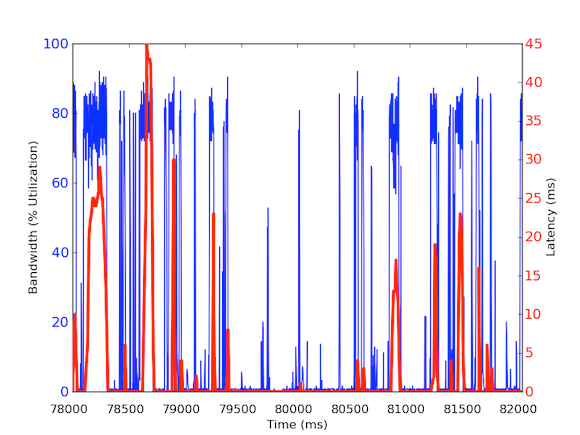
Dessa grafer visar vikten av subsekundersmätningar! Även om det är svårt att upprätthålla en fullständig infrastruktur med sådana data, åtminstone för djupgående undersökningar, bör det vara en granularitet att gå till eftersom millisekunder verkligen spelar roll när det gäller prestanda!
Impact of Root Cause
Denna grundorsak har en intressant effekt på vårt distribuerade system. Generellt sett gillar system hög genomströmning, därför är det bra att ha extremt hög utnyttjandegrad. Men vår caching-server hanterar två typer av trafik: (1) data med hög genomströmning från databasen (2) små förfrågningar från API-lagret. Förvisso kan API-lagrets förfrågningar orsaka data med hög genomströmning från databasen, men här är nyckeln: Det behövs bara när förfrågan inte kan tillgodoses av cacheminnet. Om förfrågan finns i cachen ska caching-servern returnera data snabbt utan att behöva vänta på databasberäkningar. Men vad händer om en cachelagrad begäran kommer in under ett microburst-svar för en begäran som inte är cachelagrad? Microbursten kan orsaka 30 ms fördröjning för all annan inkommande trafik och därför kan den cachade förfrågan uppleva en extra 30 ms fördröjning som är helt onödig!
Steg 4: Prototyp och validering
När vi väl hade upptäckt en plausibel grundorsak ville vi validera våra resultat. Eftersom den här burstartade bandbreddsanvändningen kan orsaka fördröjningar för cacheträffar kunde vi isolera dessa förfrågningar från cacheserverns förfrågningar till databasklustret. För att göra detta satte vi upp en experimentell miljö där en enda cache-server värd har två NIC:er, var och en med egna IP-adresser. Med den här inställningen går alla API Layer-förfrågningar till cacheservern via ett gränssnitt och alla cacheserverförfrågningar till databasklustret går via det andra gränssnittet. Diagrammet nedan illustrerar detta:

Med den här inställningen mätte vi följande latenser och som du kan se är latenserna mellan API-lagret och cacheserveren faktiskt vad vi förväntar oss – friska och under 1 ms. Latenser med databasklustret kan inte undvikas utan förbättrad hårdvara; eftersom vi vill maximera genomströmningen kommer bursts alltid att inträffa och därmed kommer paketen att ställas i kö vid gränssnittet.

Därmed förtjänar olika trafik olika prioriteringar och kan vara en idealisk lösning för att hantera microbursting-trafik. Andra lösningar är att förbättra hårdvaran, till exempel genom att använda hårdvara med 10 Gbps, komprimering av data eller till och med använda tjänstekvalitet.
Det kan vara svårt att hitta grundorsaken till longtails.
Rotorsaken till longtail latenstider kan vara svår att hitta, eftersom de är flyktiga och kan undgå prestandamätningar. De flesta prestandamätningar som vi samlar in här på LinkedIn har en granularitet på en sekund och vissa på en minut. Om man tar detta i perspektiv kan dock longtail latenser som varar 30 ms lätt missas av mätningar med granularitet på till och med 1 000 ms (1 sekund). Dessutom kan långsamma fördröjningar bero på olika problem i hårdvara eller mjukvara och det kan vara ganska svårt att fastställa orsaken i ett komplext distribuerat system. Några exempel på orsaker kan vara användning av hårdvaruresurser som handlar om rättvisa, konkurrens och mättnad, eller problem med datamönster, t.ex. fördelning på flera noder eller kraftfulla användare som orsakar långsamma latenser för sina arbetsbelastningar.
För att sammanfatta uppmuntrar vi till att komma ihåg de här fyra stegen i vår metodik för framtida undersökningar:
- Har en kontrollerad och förenklad miljö.
- Få detaljerade mätningar av latenstiden från slut till slut.
- Eliminera och experimentera.
- Prototypera och validera.
Lärdomar
- Longtail latens är inte bara buller! Den kan bero på olika verkliga orsaker och 99:e percentilen av förfrågningar kan påverka resten av ett stort distribuerat system.
- Du får inte bortse från den 99:e percentilen av latensproblem som maktanvändare; när maktanvändarna blir fler och fler kommer problemen också att öka.
- Att säkra sin satsning även om det är en generellt sett bra strategi där systemet skickar samma begäran två gånger i hopp om ett snabbt svar hjälper inte när de långa latenstiderna är applikationsinducerade. I själva verket gör det bara systemet sämre genom att det läggs till mer trafik till systemet, vilket i vårt fall skulle leda till att fler microbursts uppstår. Om vi hade genomfört denna strategi utan en grundlig analys skulle vi ha blivit besvikna eftersom systemets prestanda skulle ha försämrats och det skulle ha varit bortkastat en avsevärd mängd arbete att genomföra en sådan lösning.
- Spridnings-/samlingsstrategier kan lätt orsaka mikrostoppar av bandbreddsanvändning, vilket leder till köfördröjningar på millisekundnivå.
- Mätningar med en granularitet på under en sekund är nödvändiga.
- Ibland är förbättringar av maskinvaran det mest kostnadseffektiva sättet att lindra problemen, men tills dess finns det fortfarande intressanta åtgärder som utvecklare kan vidta, t.ex. komprimering av data eller selektivitet när det gäller vilka data som skickas eller används.
Den viktigaste läxan vi lärde oss var slutligen att följa metodiken. Metodologier ger riktning åt utredningar, särskilt när saker och ting blir förvirrande eller börjar kännas som en resa genom Midgård.
Acknowledgements
Jag vill tacka Andrew Carter för hans arbete och samarbete under utredningen och Steven Callister för att ha gett operativt stöd och återkoppling. Tack även till Badri Sridharan, Haricharan Ramachandra, Ritesh Maheshwari och Zhenyun Zhuang för deras feedback och förslag på denna skrift.