Kdo posunul mou 99. percentil latence?
Spolutvůrce: Cuong Tran
Dlouhé latence ovlivňují členy každý den a zlepšení doby odezvy systémů i na 99. percentilu má zásadní význam pro zkušenosti členů. Příčin může být mnoho, například pomalé aplikace, pomalé přístupy na disk, chyby v síti a mnoho dalších. Setkali jsme se s hlavní příčinou mikroburstování provozu, kterou nelze snadno vyřešit strategií hedging your bet, tj. odesláním stejného požadavku na více serverů v naději, že jeden ze serverů nebude ovlivněn longtailovými latencemi. V tomto následujícím příspěvku se s vámi podělíme o naši metodiku odstraňování příčin longtailových latencí, zkušenosti a poznatky.
Síťové latence mezi stroji v rámci datového centra mohou být nízké. Obecně platí, že veškerá komunikace trvá několik mikrosekund, ale jednou za čas trvá některým paketům několik milisekund. Pakety, které trvají několik milisekund, obecně patří k 90. percentilu latencí nebo vyššímu. K dlouhým latencím dochází, když tyto vysoké percentily začnou mít hodnoty, které značně přesahují průměr a mohou být o mnohokrát větší než průměr. Průměrné latence tedy vypovídají pouze z poloviny. Následující graf ukazuje rozdíl mezi dobrým rozložením latencí a rozložením s dlouhým chvostem. Jak vidíte, 99. percentil je 30krát horší než medián a 99,9. percentil je 50krát horší!
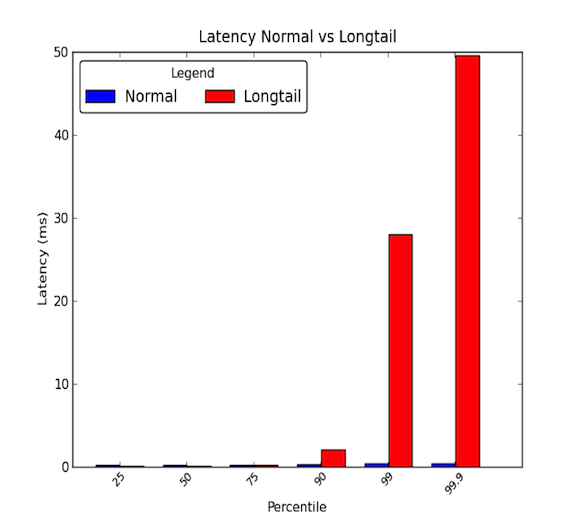
- Na dlouhých ocasech opravdu záleží!
- Případová studie
- Krok 1: Mějte kontrolované a zjednodušené prostředí
- Krok 2: Měření latence mezi koncovými body
- Krok 3: Eliminujte a experimentujte
- Mikrobursty, ach jo!
- Vliv kořenové příčiny
- Krok 4: Prototyp a ověření
- Najít hlavní příčinu longtailů může být obtížné.
- Naučení
- Poděkování
Na dlouhých ocasech opravdu záleží!
99. percentil latence 30 ms znamená, že každý 1 ze 100 požadavků má 30 ms zpoždění. U webových stránek s vysokou návštěvností, jako je LinkedIn, to může znamenat, že u stránky s 1 milionem zobrazení denně pak 10 000 z těchto zobrazení zažije zpoždění. Většina dnešních systémů jsou však distribuované systémy a 1 požadavek může ve skutečnosti vytvořit více následných požadavků. Takže 1 požadavek může vytvořit 2 požadavky, 10 nebo dokonce 100! Pokud více navazujících požadavků zasáhne jednu službu postiženou longtail latencí, náš problém se stává děsivějším.
Pro ilustraci řekněme, že 1 požadavek klienta vytvoří 10 navazujících požadavků na subsystém postižený longtail latencí. A předpokládejme, že má 1% pravděpodobnost pomalé odpovědi na jeden požadavek. Pak pravděpodobnost, že alespoň 1 z 10 navazujících požadavků je ovlivněn longtail latencí, odpovídá komplementu všech navazujících požadavků reagujících rychle (99% pravděpodobnost rychlé reakce na každý jednotlivý požadavek), což je:

To je 9,5 %! To znamená, že 1 požadavek klienta má téměř 10procentní pravděpodobnost, že bude ovlivněn pomalou odezvou. To odpovídá očekávání, že bude ovlivněno 100 000 klientských požadavků z 1 milionu klientských požadavků. To je hodně členů!“
Naše předchozí ukázka však neuvažuje, že aktivní členové obvykle procházejí více než jednu stránku, a pokud tento jeden uživatel zadá stejný klientský požadavek vícekrát, pravděpodobnost, že bude ovlivněn problémy s latencí, se dramaticky zvyšuje. Proto může mít velmi aktivní backendová služba postižená longtailovými latencemi vážný dopad na celý web.
Případová studie
Nedávno jsme měli možnost prozkoumat jeden z našich distribuovaných systémů, který se potýkal s longtailovými síťovými latencemi. Tento problém se vyskytoval již několik měsíců, přičemž zběžná šetření neprokázala žádné zjevné příčiny dlouhých síťových latencí. Rozhodli jsme se provést hloubkové šetření, abychom zjistili příčinu problému. V tomto příspěvku na blogu jsme se chtěli podělit o naše zkušenosti a metodiku, kterou jsme použili k identifikaci hlavní příčiny prostřednictvím následující případové studie.
Krok 1: Mějte kontrolované a zjednodušené prostředí
Nejprve jsme vytvořili testovací prostředí skutečného produkčního systému. Zjednodušili jsme systém na několik strojů, které mohly reprodukovat dlouhé síťové latence. Dále jsme vypnuli protokolování a perzistenci dat cache na disku, abychom eliminovali IO-stress. To nám umožnilo zaměřit pozornost na klíčové komponenty, jako je procesor a síť. Dbali jsme také na nastavení simulovaných provozů, které jsme mohli opakovat, abychom měli reprodukovatelné testy, zatímco jsme prováděli experimenty a ladění systémů. Následující schéma ukazuje naše testovací prostředí, které se skládalo z vrstvy API, cache serveru a malého databázového clusteru.

Na vysoké úrovni přicházejí požadavky z externích služeb do distribuovaného systému prostřednictvím vrstvy API. Požadavky jsou pak předávány serveru mezipaměti, který plní dotazy. Pokud data nejsou v mezipaměti, server mezipaměti provede požadavky na databázový cluster, aby vytvořil odpověď na dotaz.
Krok 2: Měření latence mezi koncovými body
Dalším krokem bylo podívat se na podrobné latence mezi koncovými body. Tím jsme se mohli pokusit izolovat naše longtailové latence a zjistit, která komponenta v našem distribuovaném systému ovlivňuje pozorované latence. Během simulovaného provozu jsme použili nástroj ping mezi různými dvojicemi mezi hostitelem vrstvy API, hostitelem cache serveru a jedním z hostitelů databázového clusteru, abychom změřili latence. Následující tabulka ukazuje 99. percentil latencí mezi dvojicí hostitelů:

Na základě těchto počátečních měření jsme dospěli k závěru, že problém s dlouhými latencemi má server cache. Provedli jsme další experimenty, abychom tato zjištění ověřili, a zjistili jsme následující:
- Hlavním problémem byly latence 99. percentilu pro příchozí provoz na server mezipaměti.
- 99. percentil latence byl měřen k ostatním hostitelským počítačům ve stejném racku jako server mezipaměti a žádný jiný hostitel nebyl ovlivněn.
- 99. percentil latence byl poté změřen také u provozu TCP, UDP a ICMP a ovlivněn byl veškerý příchozí provoz na server mezipaměti.
Dalším krokem bylo rozebrání sítě a zásobníku protokolů podezřelého serveru cache. Tím jsme doufali, že se nám podaří izolovat tu část serveru mezipaměti, která měla vliv na dlouhé latence. Naše měření latence při rozpadu end-to-end je uvedeno níže:

Tato měření jsme provedli implementací jednoduché aplikace UDP request/response v jazyce C a pro síťový provoz jsme použili časovou značku poskytovanou systémem Linux. V dokumentaci k jádru si můžete prohlédnout příklad funkcí v souboru timestamping.c, který umožňuje získat podrobné informace o tom, kdy pakety dopadají na kartu síťového rozhraní a sokety. Za zmínku také stojí, že některé karty síťového rozhraní poskytují hardwarové časové razítkování, které umožňuje získat informace o tom, kdy pakety skutečně procházejí kartou síťového rozhraní; ne všechny karty to však podporují. Další informace naleznete v tomto dokumentu společnosti RedHat. V systému jsme také použili tcpdumps, abychom mohli zjistit, kdy jsou požadavky/odpovědi zpracovávány na úrovni protokolu operačním systémem.
Krok 3: Eliminujte a experimentujte
Poté, co jsme zjistili, že problém s latencí je mezi hardwarem karty síťového rozhraní a protokolovou vrstvou operačního systému, jsme se na tyto části systému intenzivně zaměřili. Vzhledem k tomu, že možným problémem mohla být karta síťového rozhraní (NIC), rozhodli jsme se prozkoumat nejprve ji a postupovat nahoru po zásobníku, abychom eliminovali různé vrstvy. Při zkoumání jednotlivých komponent jsme měli na paměti následující skutečnosti: Spravedlnost, soupeření a nasycení. Tyto tři klíčové oblasti pomáhají najít potenciální úzká místa nebo problémy s latencí.
- Spravedlnost: Dostávají entity v systému spravedlivý podíl času nebo prostředků na zpracování nebo dokončení? Dostává například každá aplikace v systému spravedlivé množství času na běh procesorů k dokončení svých úkolů? Pokud ne, způsobuje nespravedlnost nebo spravedlnost problém? Možná by například aplikace s vysokou prioritou měla být upřednostněna před ostatními; zpracování videa v reálném čase vyžaduje více času než úloha na pozadí, která umožňuje zálohovat soubory do cloudové služby.
- Spory: Bojují entity v systému o stejný prostředek? Pokud například dvě aplikace zapisují na jeden pevný disk, musí obě aplikace soupeřit o šířku pásma disku. To do značné míry souvisí se spravedlností, protože sporné situace musí být řešeny pomocí nějakého algoritmu spravedlnosti. Soupeření může být jednodušší hledat místo otázky spravedlnosti.
- Nasycení: Je prostředek nadměrně nebo zcela využíván? Pokud je prostředek nadměrně nebo úplně využíván, můžeme narazit na nějaké omezení, které způsobuje sporné situace nebo zpoždění, protože subjekty musí stát ve frontě na využití prostředků, jakmile jsou k dispozici.
Když jsme řešili síťovou kartu NIC, zaměřili jsme se hlavně na to, abychom zjistili a) zda nedochází k přeplňování front, což by se projevilo jako zahození a naznačilo by to možné omezení využití šířky pásma, nebo b) zda se nevyskytují nějaké chybné pakety, které by potřebovaly opakované přenosy, což by mohlo způsobit zpoždění. Během našich experimentů bylo zaznamenáno 0 discardů a 0 malformovaných paketů dopadajících na síťovou kartu a naše využití šířky pásma bylo zhruba 5 – 40 MB/s, což je na našem 1 Gb/s hardwaru málo.
Dále jsme se zaměřili na úroveň ovladače a protokolu. Tyto dvě části bylo obtížné oddělit; velkou část našeho zkoumání jsme však strávili zkoumáním různých ladění operačního systému, která se týkala plánování procesů, využití prostředků pro jádra, plánování obsluhy přerušení a afinity k přerušení pro využití jader. Tyto klíčové oblasti by mohly potenciálně způsobit zpoždění při zpracování síťových paketů a my jsme chtěli mít jistotu, že požadavky a odpovědi budou vyřizovány tak rychle, jak to stroj zvládne. Bohužel většina našich experimentů nepřinesla žádnou hlavní příčinu.
Příznaky, které jsme viděli na začátku, se zdály naznačovat systém s omezenou šířkou pásma. Při velkém provozu se latence zvyšují v důsledku zpoždění při řazení do fronty. Přesto, když jsme se podívali na vrstvu NIC, takový problém jsme nezaznamenali. Ale poté, co jsme vyřadili téměř vše v zásobníku, jsme si uvědomili, že naše výkonnostní metriky měří v granularitě 1 sekundy nebo 1 000 milisekund. Jak bychom mohli doufat, že se nám podaří zachytit problém s 30 ms dlouhou latencí?“
Mikrobursty, ach jo!
Mnoho našich systémů má karty síťového rozhraní s rychlostí 1 Gb/s. A jak bychom mohli doufat, že se nám to podaří? Když jsme se podívali na příchozí provoz, viděli jsme, že na serveru vyrovnávací paměti dochází zpravidla k provozu 5 – 40 MB/s. Takové využití šířky pásma nevyvolává žádné varovné signály; co kdybychom se však podívali na využití šířky pásma v milisekundách! První graf níže zobrazuje využití šířky pásma za sekundu a ukazuje nízké využití, zatímco druhý graf zobrazuje využití šířky pásma za milisekundu a ukazuje zcela jiný příběh.

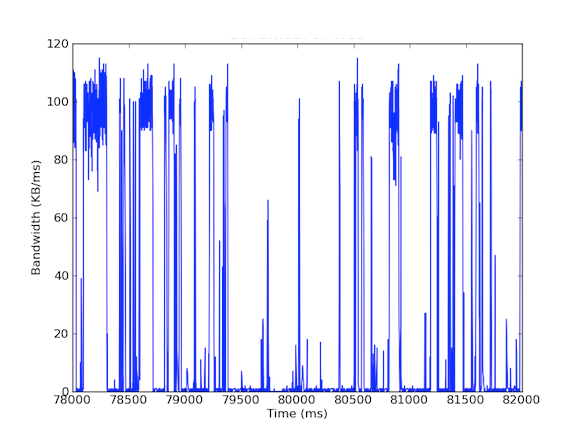
Pro měření příchozího provozu za milisekundu jsme použili tcpdump, který shromažďoval provoz po stanovenou dobu. To vyžadovalo offline výpočty, ale protože tcpdump má časové značky na úrovni mikrosekund, mohli jsme vypočítat využití příchozí šířky pásma na milisekundu. Díky těmto měřením jsme byli schopni identifikovat příčinu dlouhých latencí sítě. Jak je vidět na výše uvedených grafech, využití šířky pásma za milisekundu vykazuje krátké výpadky po několika stovkách milisekund, které dosahují téměř 100 kB/ms. Taková rychlost 100 kB/ms trvající po celou sekundu by odpovídala 100 MB/s, což je 80 % teoretické kapacity karet síťového rozhraní 1 Gb/s! Tyto dávky se nazývají microbursts a jsou vytvářeny distribuovaným databázovým clusterem, který odpovídá cache serveru najednou, čímž vzniká plně využitá linka na dobu pod sekundou. Níže je uveden graf využití šířky pásma v procentech rychlosti 1 Gb/s v porovnání s latencemi naměřenými ve stejném časovém úseku. Jak je vidět, existuje vysoká korelace mezi skokovými změnami latence a burstovním provozem:
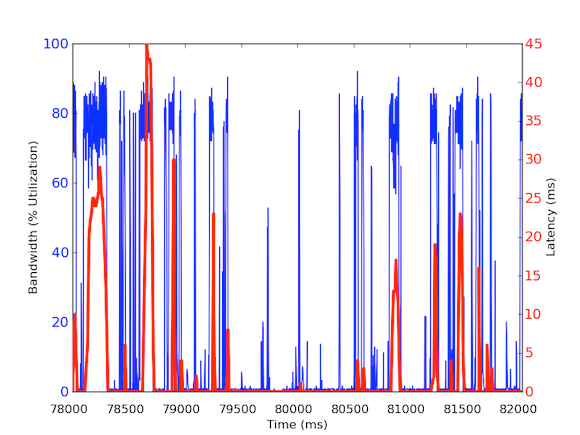
Tyto grafy ukazují důležitost subsekundových měření! I když je obtížné udržovat plnou infrastrukturu s takovými daty, alespoň pro hloubkové zkoumání by to měla být granularita, protože ve výkonu na milisekundách opravdu záleží!“
Vliv kořenové příčiny
Tato kořenová příčina má zajímavý vliv na náš distribuovaný systém. Obecně mají systémy rády vysokou propustnost, proto je extrémně vysoké vytížení dobrá věc. Náš cachovací server se však zabývá dvěma typy provozu: (1) data z databáze s vysokou propustností (2) malé dotazy z vrstvy API. Připouštíme, že požadavky vrstvy API mohou způsobit vysokou propustnost dat z databáze, ale zde je klíč: Je to potřeba pouze tehdy, když požadavek nemůže být splněn pomocí mezipaměti. Pokud je požadavek v mezipaměti, měl by server mezipaměti vrátit data rychle, aniž by musel čekat na výpočty v databázi. Co se však stane, pokud požadavek uložený v mezipaměti přijde v průběhu mikroburzovní odpovědi na požadavek, který není uložen v mezipaměti? Mikrobursta může způsobit 30 ms zpoždění jakéhokoli jiného příchozího provozu, a proto by požadavek uložený v mezipaměti mohl zaznamenat dalších 30 ms zpoždění, které je zcela zbytečné!“
Krok 4: Prototyp a ověření
Když jsme objevili pravděpodobnou příčinu, chtěli jsme naše výsledky ověřit. Protože toto nárazové využití šířky pásma může způsobit zpoždění zásahů do mezipaměti, mohli jsme tyto požadavky izolovat od dotazů serveru mezipaměti na databázový cluster. Za tímto účelem jsme vytvořili experimentální prostředí, ve kterém má jeden hostitel cache serveru dvě síťové karty, každá s vlastní IP adresou. Při tomto nastavení procházejí všechny požadavky vrstvy API na server cache přes jedno rozhraní a všechny dotazy serveru cache na databázový cluster přes druhé rozhraní. Níže uvedený diagram to ilustruje:

Při tomto nastavení jsme naměřili následující latence a jak vidíte, latence mezi vrstvou API a serverem cache jsou skutečně takové, jaké očekáváme – zdravé a pod 1 ms. Latencím s databázovým clusterem se bez lepšího hardwaru nevyhneme; protože chceme maximalizovat propustnost, budou se vždy vyskytovat bursty, a proto se pakety budou řadit do fronty na rozhraní.

Různý provoz si proto zaslouží různé priority a může být ideálním řešením pro zvládnutí mikroburstového provozu. Mezi další řešení patří vylepšení hardwaru, například použití hardwaru s rychlostí 10 Gb/s, komprese dat nebo dokonce použití kvality služby.
Najít hlavní příčinu longtailů může být obtížné.
Hlavní příčinu longtailových latencí může být obtížné najít, protože jsou efemérní a mohou unikat výkonnostním metrikám. Většina výkonnostních metrik, které zde ve společnosti LinkedIn shromažďujeme, má granularitu 1 sekundy a některé 1 minuty. Pokud to však vezmeme v úvahu, longtailové latence, které trvají 30 ms, mohou být snadno přehlédnuty měřeními s granularitou dokonce 1 000 ms (1 sekunda). Nejen to, dlouhé zpoždění může být způsobeno různými problémy v hardwaru nebo softwaru a v komplexním distribuovaném systému může být poměrně obtížné zjistit jeho příčinu. Příkladem příčin může být využití hardwarových prostředků, které se potýká s férovostí, sporností a nasyceností, nebo problémy s datovými vzory, jako je vícenásobné rozložení uzlů nebo výkonní uživatelé, kteří způsobují longtail latence pro své pracovní zátěže.
Shrneme-li to, důrazně doporučujeme pamatovat na tyto čtyři kroky naší metodiky pro budoucí vyšetřování:
- Mějte kontrolované a zjednodušené prostředí.
- Získejte podrobná měření latence od konce ke konci.
- Eliminujte a experimentujte.
- Prototypujte a ověřujte.
Naučení
- Dlouhá latence není jen šum! Může být způsobena různými skutečnými důvody a požadavky na 99. percentilu mohou ovlivnit zbytek velkého distribuovaného systému.
- Nepodceňujte 99. percentil problémů s latencí jako výkonné uživatele; jak se budou výkonní uživatelé množit, budou se množit i problémy.
- Zajištění sázky, i když je to obecně dobrá strategie, kdy systém posílá stejný požadavek dvakrát v naději na jednu rychlou odezvu, nepomůže, když jsou longtailové latence způsobeny aplikací. Ve skutečnosti jen zhoršuje systém tím, že do něj přidává další provoz, což by v našem případě způsobilo více mikroburstů. Kdybychom tuto strategii zavedli bez důkladné analýzy, byli bychom zklamáni, protože by se zhoršil výkon systému a bylo by zbytečné vynaložit značné úsilí na zavedení takového řešení.
- Přístupy rozptylu/sběru mohou snadno způsobit mikroburzy využití šířky pásma a způsobit zpoždění ve frontě na úrovni milisekund.
- Měření na subsekundové granularitě je nezbytné.
- Někdy jsou vylepšení hardwaru nákladově nejefektivnějším způsobem, jak pomoci zmírnit problémy, ale do té doby stále existují zajímavá zmírnění, která mohou vývojáři provést, například komprese dat nebo selektivní výběr odesílaných nebo používaných dat.
Nakonec nejdůležitějším poznatkem, který jsme si odnesli, bylo dodržování metodiky. Metodiky udávají směr vyšetřování, zejména když se věci stanou nepřehlednými nebo začnou připomínat cestu Středozemí.
Poděkování
Rád bych poděkoval Andrewovi Carterovi za jeho práci a spolupráci během vyšetřování a Stevenu Callisterovi za poskytování provozní podpory a zpětné vazby. Rovněž děkuji Badrimu Sridharanovi, Haricharanovi Ramachandrovi, Riteshovi Maheshwarimu a Zhenyun Zhuangovi za jejich zpětnou vazbu a návrhy k tomuto spisu.