Pozor? Pozor!
Pozornost je v posledních letech v komunitě hlubokého učení poměrně populární pojem a užitečný nástroj. V tomto příspěvku se podíváme na to, jak byla pozornost vynalezena, a na různé mechanismy a modely pozornosti, jako je transformátor a SNAIL.
Pozornost je do jisté míry motivována tím, jak věnujeme vizuální pozornost různým oblastem obrazu nebo korelujeme slova v jedné větě. Vezměme si jako příklad obrázek shiba inu na obr. 1.

Obr. 1. Shiba Inu v pánském oblečení. Zásluhu na původní fotografii má Instagram @mensweardog.
Lidská vizuální pozornost nám umožňuje zaměřit se na určitou oblast s „vysokým rozlišením“ (tj. podívejte se na špičaté ucho ve žlutém rámečku) a zároveň vnímat okolní obraz v „nízkém rozlišení“ (tj. co teď zasněžené pozadí a oblečení?), a podle toho pak upravit ohnisko nebo provést inferenci. Při daném malém kousku obrazu poskytují pixely ve zbytku nápovědu, co by se tam mělo zobrazit. Očekáváme, že ve žlutém poli uvidíme špičaté ucho, protože jsme viděli psí nos, další špičaté ucho vpravo a Shibovy záhadné oči (věci v červených polích). Svetr a deka dole by však nebyly tak užitečné jako tyto psí rysy.
Podobně můžeme vysvětlit vztah mezi slovy v jedné větě nebo blízkém kontextu. Když vidíme „jíst“, očekáváme, že se brzy setkáme se slovem jídlo. Barevný výraz popisuje jídlo, ale pravděpodobně ne tolik přímo se slovem „jíst“.
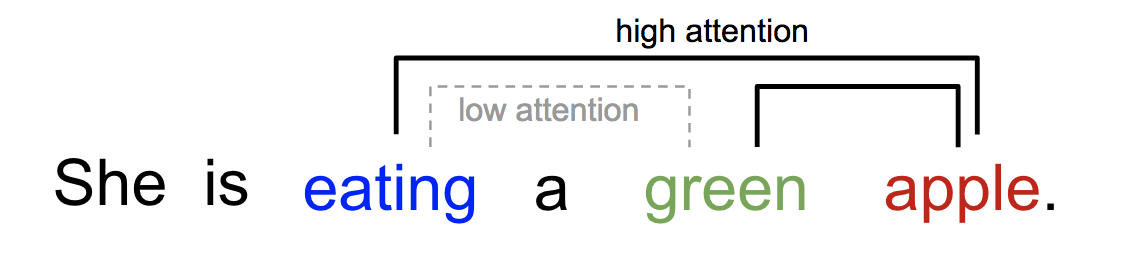
Obr. č. 2. Jedno slovo se „věnuje“ jiným slovům v téže větě různě.
Zjednodušeně řečeno, pozornost v hlubokém učení lze obecně interpretovat jako vektor vah důležitosti: abychom mohli předpovědět nebo odvodit jeden prvek, například pixel v obrázku nebo slovo ve větě, odhadneme pomocí vektoru pozornosti, jak silně koreluje (nebo se „věnuje“, jak jste se mohli dočíst v mnoha článcích) s jinými prvky, a součet jejich hodnot vážených vektorem pozornosti považujeme za aproximaci cíle.
- Co je špatně na modelu Seq2Seq?“
- Zrozený pro překlad
- Definice
- Rodina mechanismů pozornosti
- Souhrn
- Self-Attention
- Měkká vs. tvrdá pozornost
- Globální vs. lokální pozornost
- Neurální Turingovy stroje
- Čtení a zápis
- Mechanismy pozornosti
- Pointer Network
- Transformátor
- Klíč, hodnota a dotaz
- Vícehlavá samopozornost
- Enkodér
- Dekodér
- Úplná architektura
- SNAIL
- Self-Attention GAN
Co je špatně na modelu Seq2Seq?“
Model seq2seq se zrodil v oblasti modelování jazyka (Sutskever, et al. 2014). Obecně řečeno, jeho cílem je transformovat vstupní sekvenci (zdrojovou) na novou (cílovou), přičemž obě sekvence mohou být libovolně dlouhé. Příklady transformačních úloh zahrnují strojový překlad mezi více jazyky, a to buď textovými, nebo zvukovými, generování dialogů s otázkami a odpověďmi, nebo dokonce rozbor vět do gramatických stromů.
Model seq2seq má obvykle architekturu kodér-dekodér, kterou tvoří:
- Kodér zpracovává vstupní sekvenci a komprimuje informace do kontextového vektoru (známého také jako vektor vložené věty nebo „myšlenkový“ vektor) pevné délky. Očekává se, že tato reprezentace bude dobrým shrnutím významu celé zdrojové sekvence.
- Dekodér je inicializován kontextovým vektorem, aby mohl emitovat transformovaný výstup. V dřívějších pracích se jako počáteční stav dekodéru používal pouze poslední stav sítě kodéru.
Kodér i dekodér jsou rekurentní neuronové sítě, tj. používají jednotky LSTM nebo GRU.
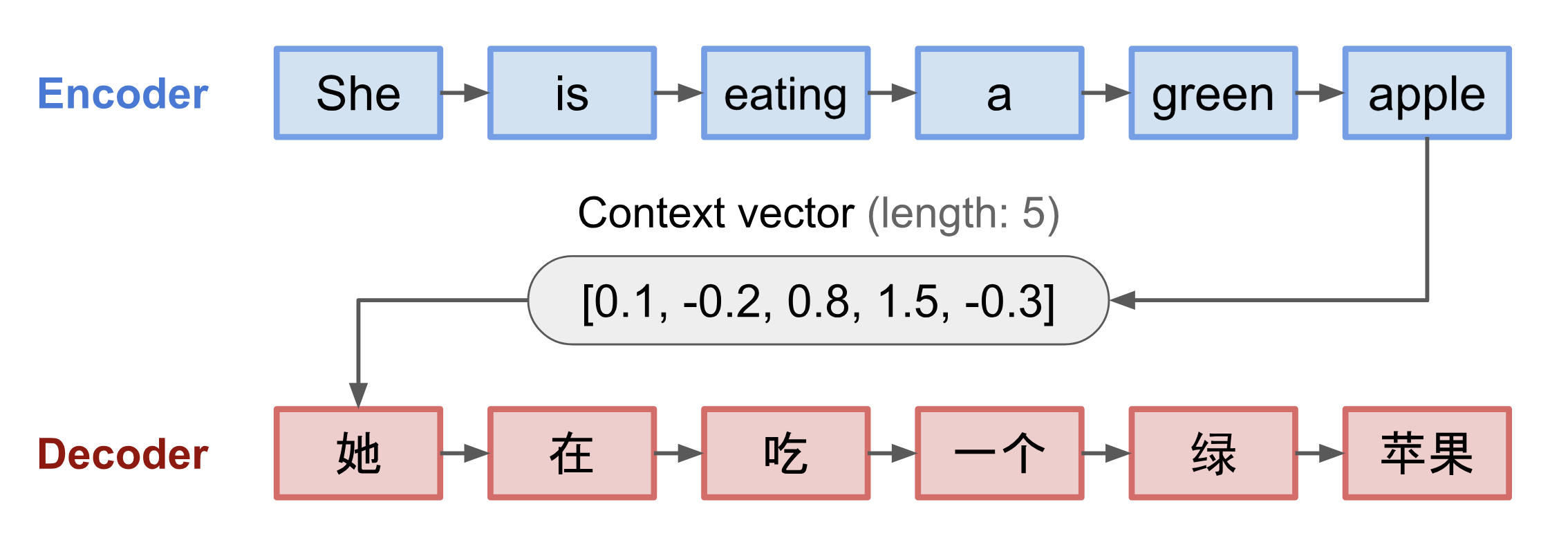
Obr. 3. Rekurentní neuronové sítě. Model kodéru a dekodéru, který překládá větu „jí zelené jablko“ do čínštiny. Vizualizace kodéru i dekodéru se odvíjí v čase.
Kritickou a zjevnou nevýhodou této konstrukce kontextového vektoru s pevnou délkou je neschopnost zapamatovat si dlouhé věty. Často zapomene první část, jakmile dokončí zpracování celého vstupu. K vyřešení tohoto problému se zrodil mechanismus pozornosti (Bahdanau et al., 2015).
Zrozený pro překlad
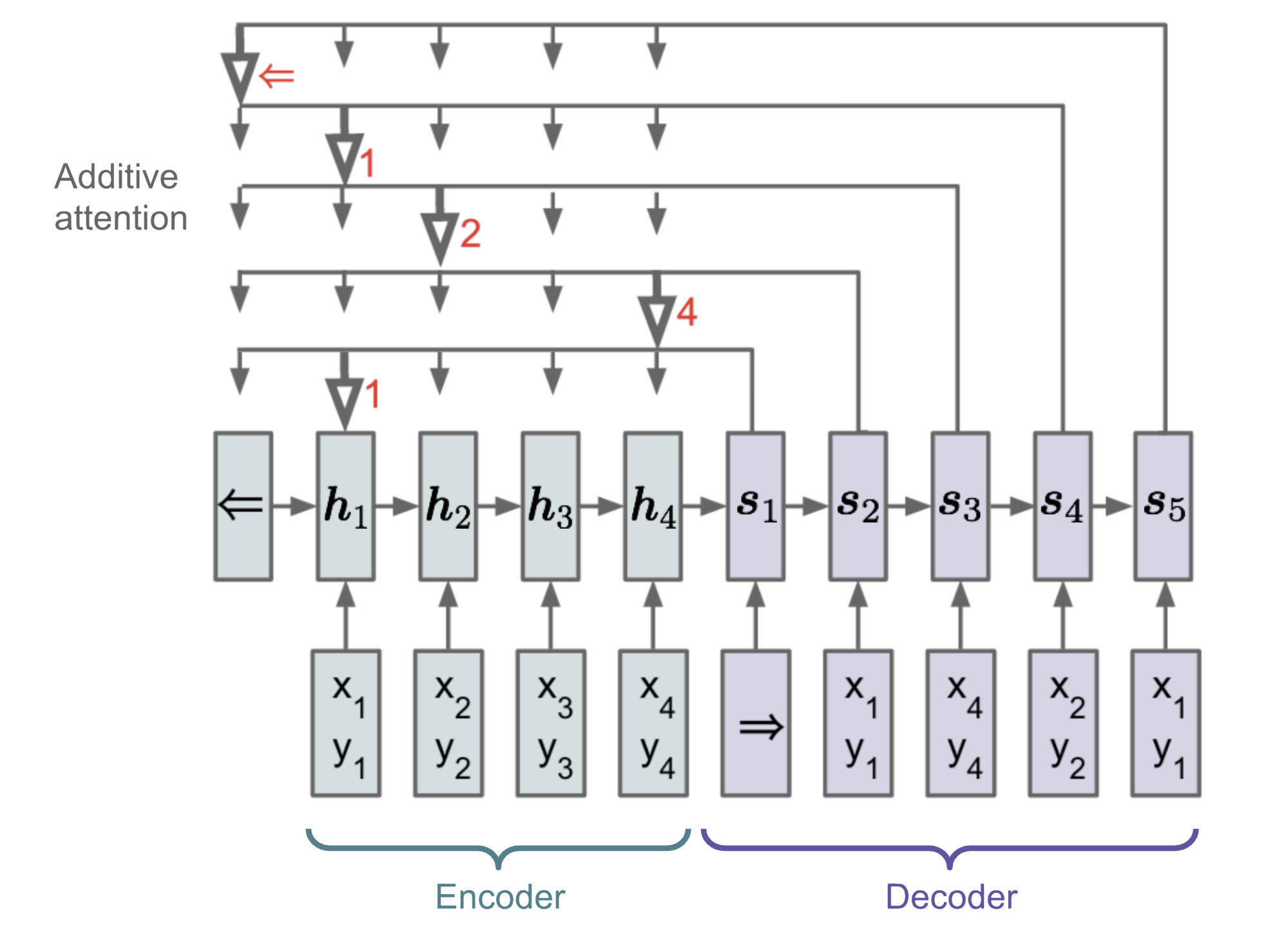
Mechanismus pozornosti se zrodil, aby pomohl zapamatovat si dlouhé zdrojové věty v neuronovém strojovém překladu (NMT). Namísto sestavování jediného kontextového vektoru z posledního skrytého stavu kodéru spočívá tajná omáčka vynalezená pozorností ve vytváření zkratek mezi kontextovým vektorem a celým zdrojovým vstupem. Váhy těchto zkratkových spojení jsou přizpůsobitelné pro každý výstupní prvek.
Když má kontextový vektor přístup k celé vstupní sekvenci, nemusíme se obávat zapomínání. Zarovnání mezi zdrojem a cílem je naučené a řízené kontextovým vektorem. Kontextový vektor v podstatě spotřebovává tři informace:
- skryté stavy kodéru;
- skryté stavy dekodéru;
- zarovnání mezi zdrojem a cílem.
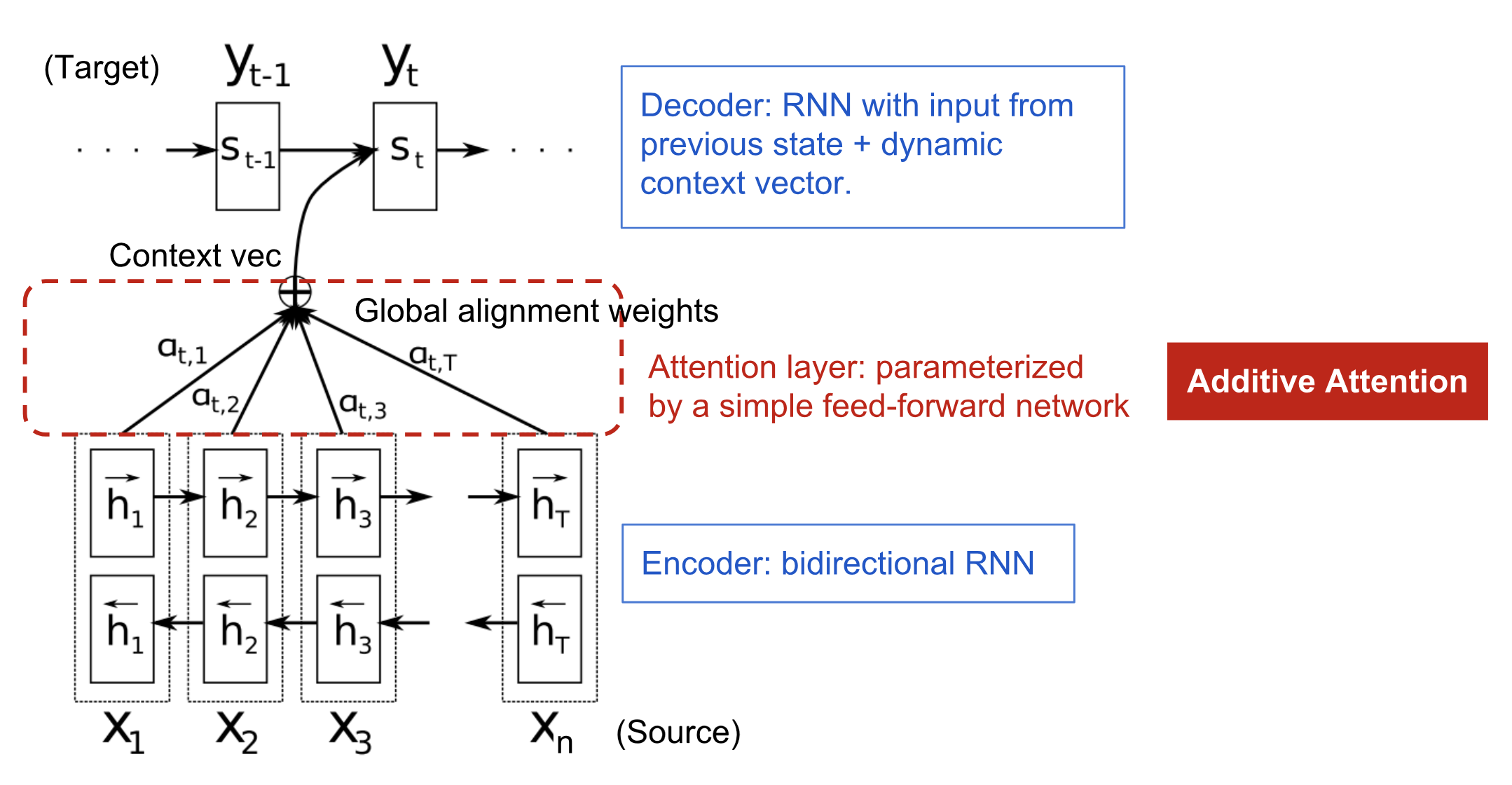
Obr. 4. Model kodér-dekodér s aditivním mechanismem pozornosti v Bahdanau et al., 2015.
Definice
\\\\mathbf{y}. &= \end{aligned}\]
(Proměnné vyznačené tučně znamenají, že se jedná o vektory; totéž platí pro vše ostatní v tomto příspěvku.)
Kodér je obousměrná RNN (nebo jiné nastavení rekurentní sítě podle vašeho výběru) s dopředným skrytým stavem \(\overrightarrow{\boldsymbol{h}}_i\) a zpětným \(\overleftarrow{\boldsymbol{h}}_i\). Jednoduchá konkatenace dvou představuje stav kodéru. Motivací je zahrnout do anotace jednoho slova jak předcházející, tak následující slovo.
\^\top, i=1,\bodky,n\]\\)\]
kde jak \(\mathbf{v}_a\), tak \(\mathbf{W}_a\) jsou váhové matice, které se mají naučit v modelu zarovnání.
Matrice skóre zarovnání je pěkný vedlejší produkt, který explicitně ukazuje korelaci mezi zdrojovými a cílovými slovy.

Obr. 5. Matice zarovnání textu „L’accord sur l’Espace économique européen a été signé en août 1992“ (francouzsky) a jeho českého překladu „Dohoda o Evropském hospodářském prostoru byla podepsána v srpnu 1992“. (Zdroj obrázku: Obr. 3 v Bahdanau et al., 2015)
Podívejte se na tento pěkný tutoriál od týmu Tensorflow, kde najdete další návod k implementaci.
Rodina mechanismů pozornosti
Pomocí pozornosti již nejsou závislosti mezi zdrojovými a cílovými sekvencemi omezeny mezilehlou vzdáleností! Vzhledem k velkému zlepšení pomocí pozornosti ve strojovém překladu se brzy rozšířila do oblasti počítačového vidění (Xu et al. 2015) a lidé začali zkoumat různé další formy mechanismů pozornosti (Luong, et al., 2015; Britz et al., 2017; Vaswani, et al., 2017).
Souhrn
Níže je uvedena souhrnná tabulka několika populárních mechanismů pozornosti a odpovídajících funkcí skóre zarovnání:
Níže je uveden souhrn širších kategorií mechanismů pozornosti:
| Název | Definice | Citace |
|---|---|---|
| Samostatná pozornost(&) | Srovnávání různých pozic stejné vstupní sekvence. Teoreticky může samo-pozornost přijmout jakoukoli výše uvedenou skórovací funkci, ale stačí nahradit cílovou posloupnost stejnou vstupní posloupností. | Cheng2016 |
| Globální/měkká | Zohledňující celý vstupní stavový prostor. | Xu2015 |
| Lokální/Tvrdý | Attending to the part of input state space; i.e. a patch of the input image. | Xu2015; Luong2015 |
(&) Also, referred to as „intra-attention“ in Cheng et al., 2016 a některých dalších pracích.
Self-Attention
Self-attention, známá také jako intra-attention, je mechanismus pozornosti vztahující různé pozice jedné sekvence za účelem výpočtu reprezentace téže sekvence. Ukázalo se, že je velmi užitečná při strojovém čtení, abstraktní sumarizaci nebo vytváření popisu obrazu.
Příspěvek o síti dlouhodobé krátkodobé paměti používal sebe-pozornost ke strojovému čtení. V níže uvedeném příkladu nám mechanismus sebepozorování umožňuje naučit se korelaci mezi aktuálními slovy a předchozí částí věty.

Obr. 6. Na základě tohoto mechanismu se můžeme naučit korelaci mezi aktuálními slovy a předchozí částí věty. Aktuální slovo je vyznačeno červeně a velikost modrého stínu označuje úroveň aktivace. (Zdroj obrázku: Cheng et al., 2016)
Měkká vs. tvrdá pozornost
V článku Ukaž, zúčastni se a řekni je mechanismus pozornosti aplikován na obrázky pro generování titulků. Obrázek je nejprve zakódován pomocí CNN za účelem extrakce rysů. Poté dekodér LSTM spotřebuje konvoluční rysy, aby vytvořil popisná slova jedno po druhém, přičemž váhy jsou naučeny pomocí pozornosti. Vizualizace vah pozornosti jasně ukazuje, kterým oblastem obrazu model věnuje pozornost, aby vyprodukoval určité slovo.

Obr. 7. „Žena hází v parku frisbee“. (Zdroj obrázku: Obr. 6(b) v Xu et al. 2015)
Tento článek poprvé navrhl rozlišení mezi „měkkou“ a „tvrdou“ pozorností podle toho, zda má pozornost přístup k celému obrazu nebo pouze k políčku:
- Měkká pozornost: váhy zarovnání jsou naučené a umístěné „měkce“ přes všechna políčka ve zdrojovém obrazu; v podstatě stejný typ pozornosti jako v Bahdanau et al. 2015.
- Pro: model je hladký a diferencovatelný.
- Proti: nákladné, když je zdrojový vstup velký.
- Hard Attention: vybírá vždy jen jednu skvrnu obrazu, které se má věnovat pozornost.
- Pro: méně výpočtů při inferenci.
- Proti: model je nediferencovatelný a k trénování vyžaduje složitější techniky, jako je redukce rozptylu nebo posilovací učení. (Luong, et al., 2015)
Globální vs. lokální pozornost
Luong, et al., 2015 navrhli „globální“ a „lokální“ pozornost. Globální pozornost je podobná měkké pozornosti, zatímco lokální je zajímavou směsí mezi tvrdou a měkkou pozorností, vylepšením oproti tvrdé pozornosti, aby byla rozlišitelná: model nejprve předpovídá jedinou zarovnanou pozici pro aktuální cílové slovo a okno se středem kolem zdrojové pozice se pak použije k výpočtu kontextového vektoru.
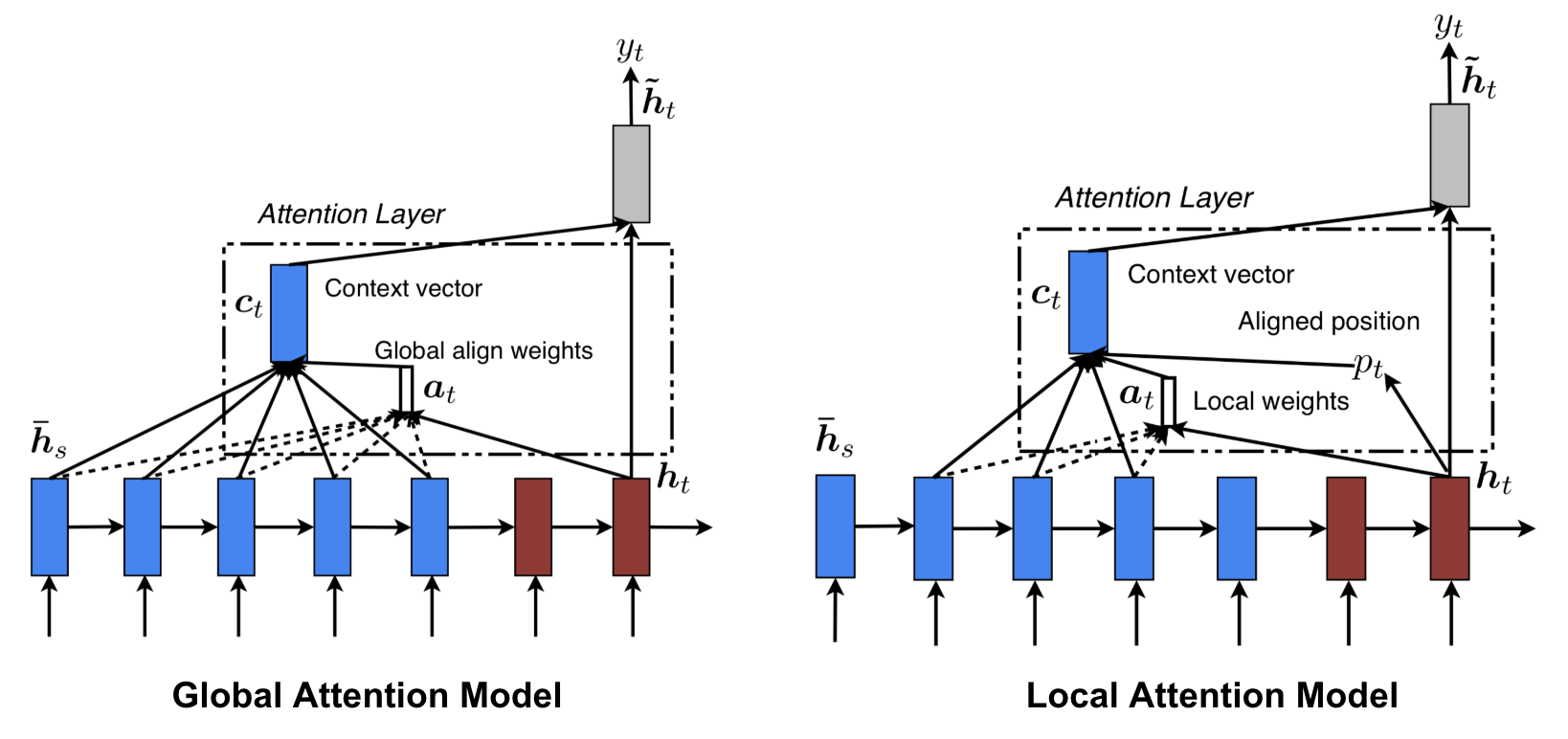
Obr. 8. Globální vs. lokální pozornost (zdroj obrázku: obr. 2 & 3 v Luong, et al., 2015)
Neurální Turingovy stroje
Alan Turing v roce 1936 navrhl minimalistický model výpočtu. Skládá se z nekonečně dlouhé pásky a hlavy pro interakci s páskou. Páska má na sobě nespočet buněk, z nichž každá je vyplněna symbolem: V každé z nich je symbol 0, 1 nebo prázdný (“ „). Operační hlava může číst symboly, upravovat symboly a pohybovat se po pásce doleva/doprava. Teoreticky může Turingův stroj simulovat jakýkoli počítačový algoritmus bez ohledu na to, jak složitý nebo nákladný postup to může být. Nekonečná paměť dává Turingovu stroji výhodu, že je matematicky neomezený. V reálných moderních počítačích však nekonečná paměť není realizovatelná, a pak uvažujeme o Turingově stroji pouze jako o matematickém modelu výpočtu.

Obr. 9. Jak vypadá Turingův stroj: páska + hlava, která s páskou manipuluje. (Zdroj obrázku: http://aturingmachine.com/)
Neurální Turingův stroj (NTM, Graves, Wayne & Danihelka, 2014) je modelová architektura pro spojení neuronové sítě s externí pamětí. Paměť napodobuje pásku Turingova stroje a neuronová síť řídí operační hlavy pro čtení z pásky nebo zápis na pásku. Paměť v NTM je však konečná, a proto pravděpodobně vypadá spíše jako „neuronový von Neumannův stroj“.
NTM obsahuje dvě hlavní součásti, řídicí neuronovou síť a paměťovou banku. Řadič: má na starosti provádění operací na paměti. Může to být jakýkoli typ neuronové sítě, feed-forward nebo rekurentní. paměť: uchovává zpracované informace. Je to matice o velikosti \(N \krát M\), která obsahuje N řádků vektorů a každý z nich má rozměry \(M\).
V jedné iteraci aktualizace kontrolér zpracovává vstup a odpovídajícím způsobem komunikuje s paměťovou bankou, aby vytvořil výstup. Interakci zajišťuje sada paralelních čtecích a zapisovacích hlav. Operace čtení i zápisu jsou „rozmazány“ tím, že se měkce věnují všem adresám paměti.
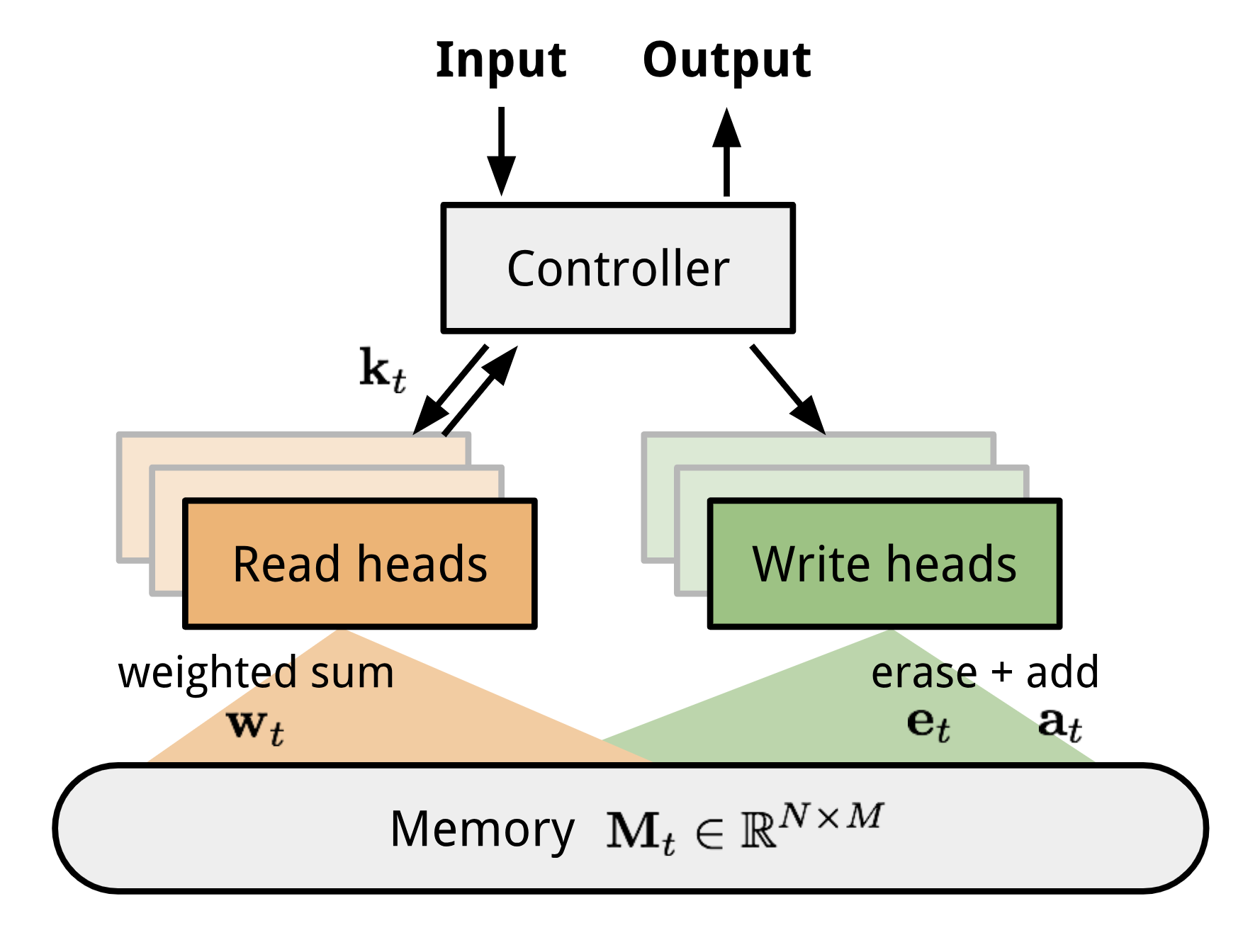
Obrázek 10. Architektura neuronového Turingova stroje.
Čtení a zápis
\
kde \(w_t(i)\) je \(i\)-tý prvek v \(\mathbf{w}_t\) a \(\mathbf{M}_t(i)\) je \(i\)-tý řádkový vektor v paměti.
\ &\scriptstyle{\text{; erase}}\\mathbf{M}_t(i) &= \tilde{\mathbf{M}}_t(i) + w_t(i) \mathbf{a}_t &\scriptstyle{\text{; add}}\end{aligned}\]
Mechanismy pozornosti
V neuronovém Turingově stroji závisí způsob generování rozdělení pozornosti \(\mathbf{w}_t\) na adresovacích mechanismech:
Adresování podle obsahu
Adresování podle obsahu vytváří vektory pozornosti na základě podobnosti mezi klíčovým vektorem \(\mathbf{k}_t\) extrahovaným řadičem ze vstupních a paměťových řádků. Skóre pozornosti založené na obsahu se vypočítá jako kosinová podobnost a poté se normalizuje pomocí softmaxu. Kromě toho NTM přidává násobitel síly \(\beta_t\), aby zesílil nebo zeslabil ohnisko distribuce.
\)= \frac{\exp(\beta_t \frac{\mathbf{k}_t \cdot \mathbf{M}_t(i)}{\|\mathbf{k}_t\| \cdot \|\mathbf{M}_t(i)\|})}{\sum_{j=1}^N \exp(\beta_t \frac{\mathbf{k}_t \cdot \mathbf{M}_t(j)}{\|\mathbf{k}_t\| \cdot \|\mathbf{M}_t(j)\|})}\]
Interpolace
Poté se použije skalár interpolačního hradla \(g_t\) ke smíchání nově vytvořeného obsahu.na základě vektoru pozornosti s váhami pozornosti v posledním časovém kroku:
\
Adresování na základě polohy
Adresování na základě polohy sčítá hodnoty na různých pozicích ve vektoru pozornosti vážené váhovým rozdělením přes přípustné celočíselné posuny. Je ekvivalentní 1-d konvoluci s jádrem \(\mathbf{s}_t(.)\), které je funkcí pozičního posunu. Existuje více způsobů, jak toto rozdělení definovat. Pro inspiraci viz obr. 11.
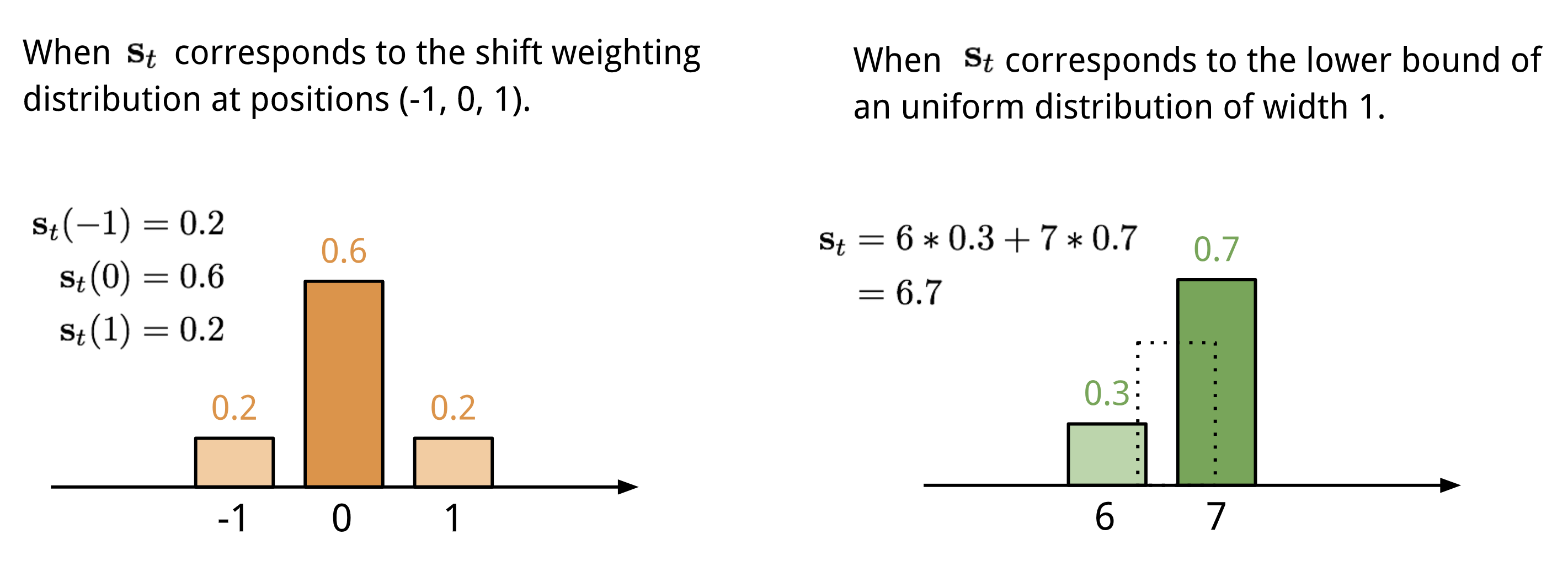
Obr. 11. Dva způsoby znázornění rozložení vah posunu \(\mathbf{s}_t\).
Nakonec je rozložení pozornosti rozšířeno o zostřující skalár \(\gamma_t \geq 1\).
\
Kompletní proces generování vektoru pozornosti \(\mathbf{w}_t\) v časovém kroku t je znázorněn na obr. 12. Na obr. 12 je znázorněn proces generování vektoru pozornosti \(\mathbf{w}_t\). Všechny parametry vytvořené regulátorem jsou pro každou hlavu jedinečné. Pokud by paralelně existovalo více čtecích a zapisovacích hlav, regulátor by produkoval více sad.
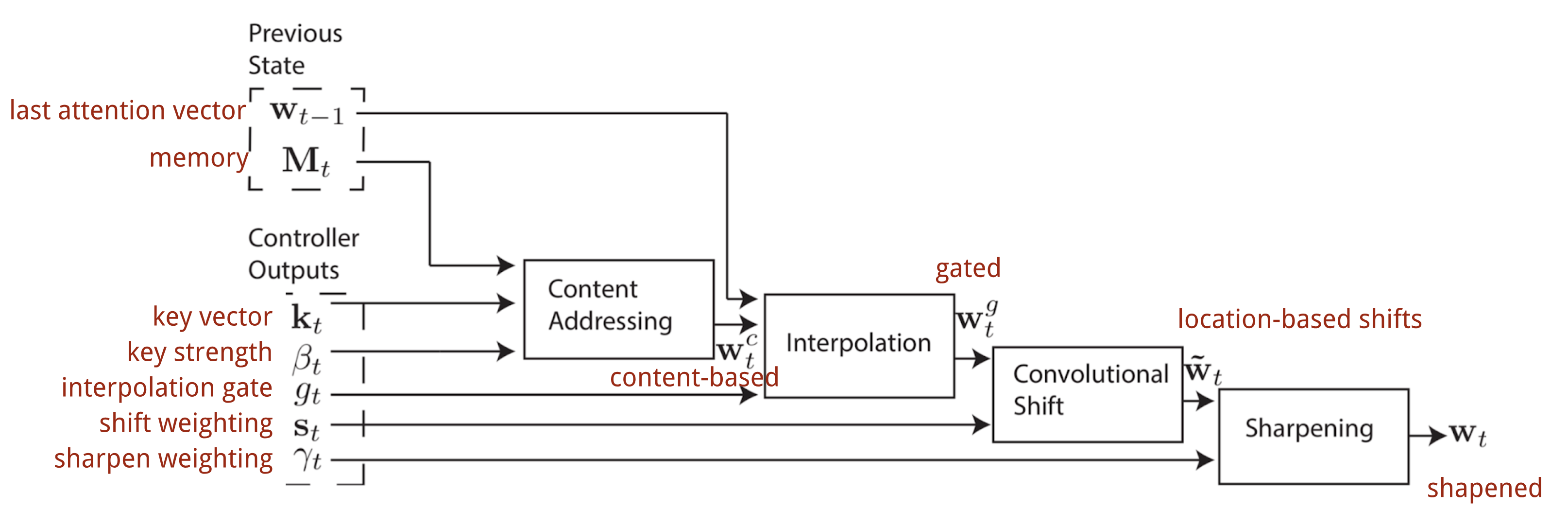
Obr. 12. Vývojový diagram adresovacích mechanismů v neuronovém Turingově stroji. (Zdroj obrázku: Graves, Wayne & Danihelka, 2014)
Pointer Network
V úlohách, jako je třídění nebo obchodní cestující, jsou vstupem i výstupem sekvenční data. Bohužel je nelze snadno řešit klasickými modely seq-2-seq nebo NMT, protože diskrétní kategorie výstupních prvků nejsou předem určeny, ale závisí na proměnné velikosti vstupu. K řešení tohoto typu problémů je navržena síť ukazatelů (Ptr-Net; Vinyals a kol. 2015): Když výstupní prvky odpovídají pozicím ve vstupní posloupnosti. Namísto použití pozornosti ke smíchání skrytých jednotek kodéru do kontextového vektoru (viz obr. 8) uplatňuje Pointer Net pozornost nad vstupními prvky, aby v každém kroku dekodéru vybral jeden z nich jako výstupní.
Obr. 13. V případě, že se jedná o skryté jednotky kodéru, je možné je použít jako výstupní prvky. Architektura modelu Pointer Network. (Zdroj obrázku: Vinyals, et al. 2015)
\))\end{aligned}\]
Mechanismus pozornosti je zjednodušený, protože Ptr-Net nemíchá stavy kodéru do výstupu pomocí vah pozornosti. Výstup tak reaguje pouze na pozice, ale nikoli na obsah vstupu.
Transformátor
„Attention is All you Need“ (Vaswani a kol., 2017) je bezpochyby jedním z nejpůsobivějších a nejzajímavějších článků roku 2017. Představil mnoho vylepšení měkké pozornosti a umožnil provádět modelování seq2seq bez jednotek rekurentní sítě. Navržený model „transformátoru“ je zcela postaven na mechanismech vlastní pozornosti bez použití sekvenčně zarovnané rekurentní architektury.
Tajný recept se nese v jeho modelové architektuře.
Klíč, hodnota a dotaz
Transformátor využívá škálovaný bodový součin pozornosti: výstupem je vážený součet hodnot, kde váha přiřazená každé hodnotě je určena bodovým součinem dotazu se všemi klíči:
\
Vícehlavá samopozornost
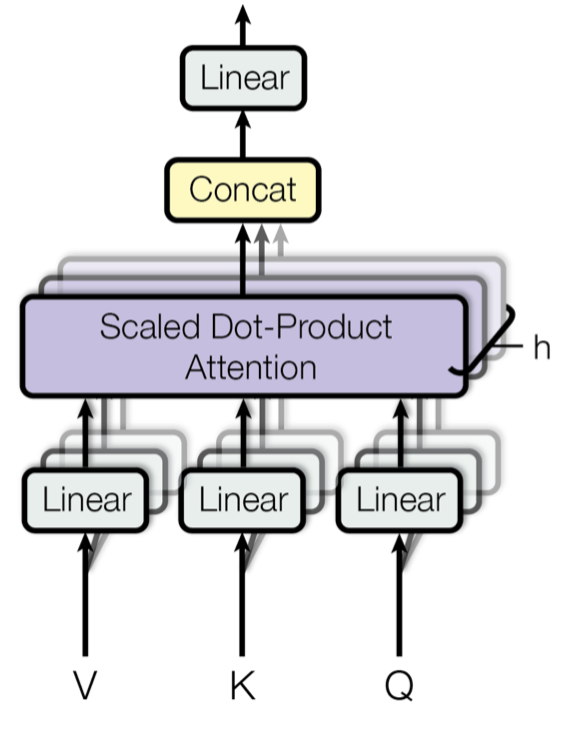
Obr. 14. Výstupem je vážený součet hodnot, kde váha přiřazená každé hodnotě je určena bodovým součinem dotazu se všemi klíči. Vícehlavý škálovaný mechanismus bodového součinu pozornosti. (Zdroj obrázku: Obr. 2 v Vaswani, et al., 2017)
Místo toho, aby se pozornost počítala pouze jednou, prochází mechanismus s více hlavami škálovanou bodově-produktovou pozorností vícekrát paralelně. Nezávislé výstupy pozornosti se jednoduše spojí a lineárně transformují do očekávaných rozměrů. Předpokládám, že motivace je v tom, že ensemblování vždycky pomůže? 😉 Podle článku „vícehlavá pozornost umožňuje modelu společně se věnovat informacím z různých reprezentačních podprostorů na různých pozicích. U jedné hlavy pozornosti tomu brání průměrování.“
\\\mathbf{W}^O \\\text{kde hlava}_i &= \text{Attention}(\mathbf{Q}\mathbf{W}^Q_i, \mathbf{K}\mathbf{W}^K_i, \mathbf{V}\mathbf{W}^V_i)\end{aligned}\]
kde \(\mathbf{W}^Q_i\), \(\mathbf{W}^K_i\), \(\mathbf{W}^V_i\) a \(\mathbf{W}^O\) jsou matice parametrů, které se mají naučit.
Enkodér
![]()
Obr. 15. Enkodér transformátoru. (Zdroj obrázku: Vaswani a kol, 2017)
Kodér vytváří reprezentaci založenou na pozornosti se schopností vyhledat konkrétní část informace z potenciálně nekonečně rozsáhlého kontextu.
- Soubor N=6 identických vrstev.
- Každá vrstva má vícehlavou vrstvu s vlastní pozorností a jednoduchou polohově plně propojenou feed-forward síť.
- Každá podvrstva přijímá reziduální spojení a normalizaci vrstvy. výstupem všech podvrstev jsou data stejného rozměru \(d_\text{model} = 512\).
Dekodér
![]()
Obr. 16. Výstupní vrstva je složena z několika vrstev. Dekodér transformátoru. (Zdroj obrázku: Vaswani, et al., 2017)
Dekodér je schopen načítat ze zakódované reprezentace.
- Skládá se z N = 6 identických vrstev
- Každá vrstva má dvě podvrstvy vícehlavých mechanismů pozornosti a jednu podvrstvu plně propojené feed-forward sítě.
- Podobně jako u kodéru každá podvrstva přijímá zbytkové spojení a normalizaci vrstvy.
- První podvrstva vícehlavé pozornosti je upravena tak, aby se zabránilo všímání si pozic v následujících pozicích, protože při předpovídání aktuální pozice nechceme nahlížet do budoucnosti cílové sekvence.
Úplná architektura
Nakonec zde máme úplný pohled na architekturu transformátoru:
- Zdrojové i cílové sekvence nejprve procházejí vrstvami vkládání, aby vznikla data stejného rozměru \(d_\text{model} =512\).
- Pro zachování informace o poloze se použije kódování polohy založené na sinusoidě a sečte se s výstupem vkládání.
- K finálnímu výstupu dekodéru se přidá vrstva softmax a lineární vrstva.
![]()
Obr. 17.
![]()
Výstupní vrstva dekodéru je tvořena vrstvou softmax. Úplná architektura modelu transformátoru. (Zdroj obrázku: Obr. 1 & 2 v Vaswani, et al., 2017.)
Zkusit implementovat model transformátoru je zajímavá zkušenost, zde je můj: lilianweng/transformer-tensorflow. Pokud vás to zajímá, přečtěte si komentáře v kódu.
SNAIL
Transformátor nemá žádnou rekurentní ani konvoluční strukturu, dokonce i s pozičním kódováním přidaným do vkládacího vektoru je sekvenční pořadí začleněno jen slabě. U problémů citlivých na polohovou závislost, jako je učení s posilováním, to může být velký problém.
Problém s polohováním v modelu transformátoru částečně vyřešil jednoduchý neuronový metaučitel pozornosti (SNAIL) (Mishra a kol., 2017), který kombinuje mechanismus vlastní pozornosti v transformátoru s časovými konvolucemi. Ukázalo se, že je dobrý jak v úlohách učení s dohledem, tak v úlohách učení s posilováním.
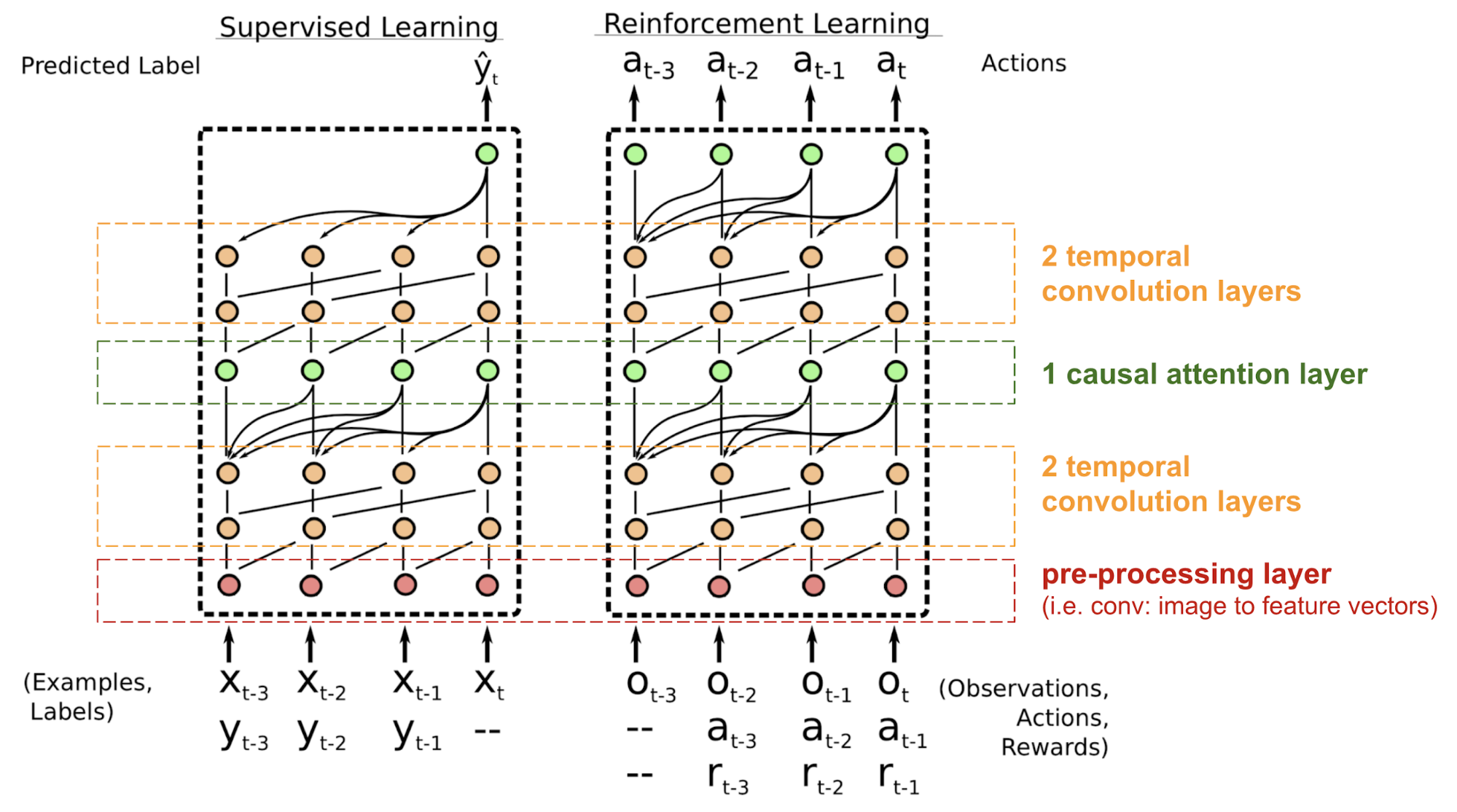
Obr. 18. Ukázalo se, že je dobrý jak v úlohách učení s dohledem, tak v úlohách učení s posilováním. Architektura modelu SNAIL (zdroj obrázku: Mishra et al., 2017)
SNAIL se zrodil v oblasti metaučení, což je další velké téma hodné samostatného příspěvku. Ale zjednodušeně řečeno, od meta-learningového modelu se očekává, že bude zobecnitelný na nové, neokoukané úlohy v podobném rozložení. Pokud vás to zajímá, přečtěte si tento pěkný úvod.
Self-Attention GAN
Self-Attention GAN (SAGAN; Zhang et al., 2018) přidává do GAN vrstvy s vlastní pozorností, aby generátor i diskriminátor mohly lépe modelovat vztahy mezi prostorovými oblastmi.
Klasický DCGAN (Deep Convolutional GAN) představuje diskriminátor i generátor jako vícevrstvé konvoluční sítě. Reprezentační kapacita sítě je však omezena velikostí filtru, protože funkce jednoho pixelu je omezena na malou lokální oblast. Aby bylo možné propojit regiony vzdálené od sebe, musí se rysy rozředit vrstvami konvolučních operací a není zaručeno, že budou zachovány závislosti.
Jelikož je (měkká) samopozornost v kontextu vidění navržena tak, aby se explicitně naučila vztah mezi jedním pixelem a všemi ostatními pozicemi, a to i regiony vzdálenými od sebe, může snadno zachytit globální závislosti. Proto se očekává, že síť GAN vybavená samopozorností bude lépe zvládat detaily, hurá!
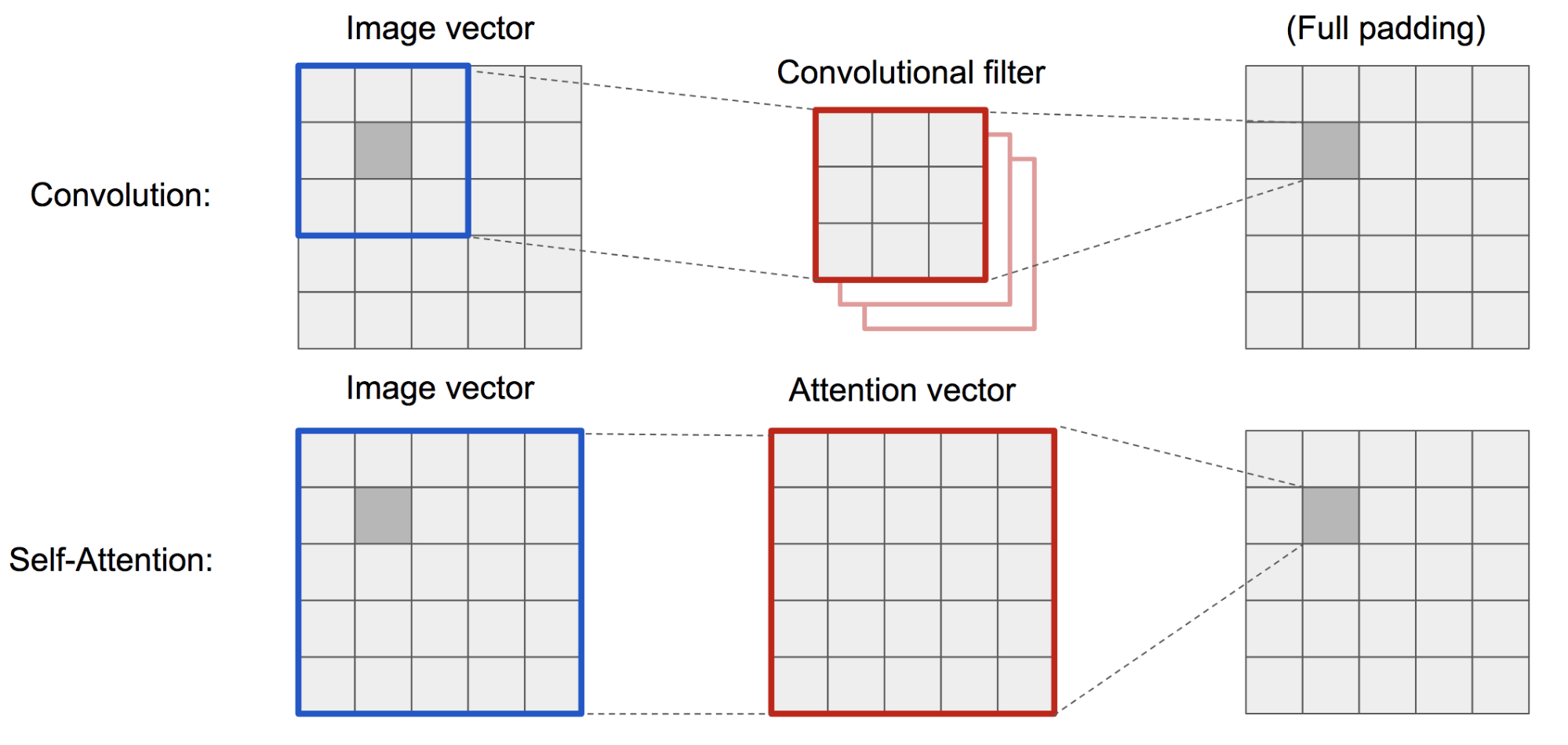
Obr. 19. Konvoluční operace a samopozornost mají přístup k oblastem velmi rozdílných velikostí.
SAGAN využívá nelokální neuronovou síť k aplikaci výpočtu pozornosti. Konvoluční mapy obrazových prvků \(\mathbf{x}\) se větví na tři kopie, které odpovídají pojmům klíč, hodnota a dotaz v transformátoru:
- Klíč: \(f(\mathbf{x}) = \mathbf{W}_f \mathbf{x}\)
- Dotaz: \(g(\mathbf{x}) = \mathbf{W}_g \mathbf{x}\)
- Hodnota: \(h(\mathbf{x}) = \mathbf{W}_h \mathbf{x}\)
Poté použijeme bodový součin pozornosti pro výstup map rysů vlastní pozornosti:
\
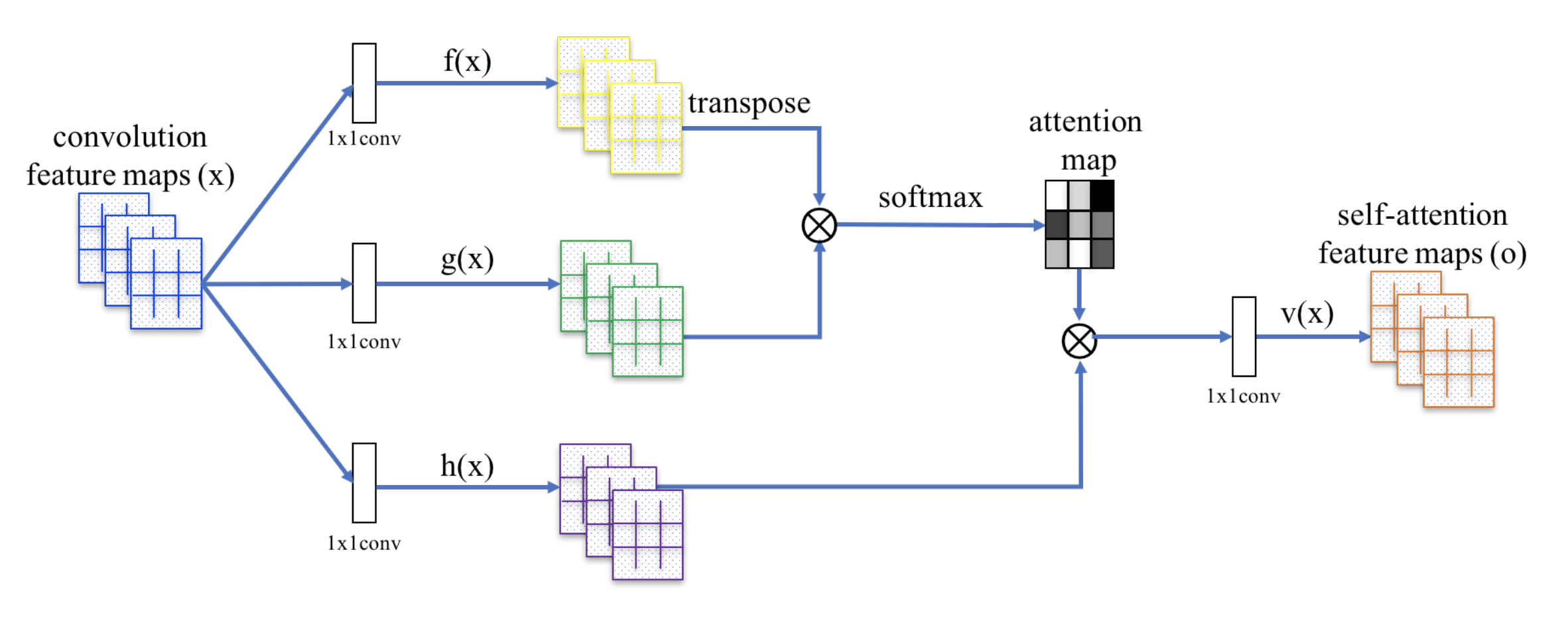
Obr. 20. Mechanismus sebepozorování v systému SAGAN. (Zdroj obrázku: Obr. 2 v publikaci Zhang et al., 2018)
Výstup vrstvy pozornosti je navíc vynásoben parametrem měřítka a přidán zpět k původní vstupní mapě rysů:
\
Při postupném zvyšování parametru měřítka \(\gamma\) z 0 během tréninku je síť nastavena tak, aby se nejprve spoléhala na podněty v lokálních oblastech a poté se postupně naučila přiřazovat větší váhu oblastem, které jsou vzdálenější.

Obr. 21. Síť SAGAN je nastavena tak, aby se nejprve spoléhala na podněty v lokálních oblastech a poté se postupně naučila přiřazovat větší váhu oblastem, které jsou vzdálenější. Příklady obrázků 128×128 generovaných systémem SAGAN pro různé třídy. (Zdroj obrázku: částečný obr. 6 v Zhang et al., 2018)
Citace:
Pokud si v tomto příspěvku všimnete chyb a omylů, neváhejte mě kontaktovat na e-mailové adrese a já je velmi rád ihned opravím!
Uvidíme se v dalším příspěvku 😀
„Pozornost a paměť v hlubokém učení a NLP“. – 3. 1. 2016 Denny Britz
„Neural Machine Translation (seq2seq) Tutorial“
Dzmitry Bahdanau, Kyunghyun Cho a Yoshua Bengio. „Neuronový strojový překlad společným učením zarovnávání a překladu“. ICLR 2015.
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel a Yoshua Bengio. „Show, attend and tell: Neurální generování popisků k obrázkům s vizuální pozorností.“ ICML, 2015.
Ilya Sutskever, Oriol Vinyals a Quoc V. Le. „Učení od sekvence k sekvenci pomocí neuronových sítí“. NIPS, 2014.
Thang Luong, Hieu Pham, Christopher D. Manning. „Efektivní přístupy k neuronovému strojovému překladu založenému na pozornosti“. EMNLP 2015.
Denny Britz, Anna Goldie, Thang Luong a Quoc Le. „Masivní průzkum architektur neuronového strojového překladu“. ACL 2017.
Ashish Vaswani a kol. „Attention is all you need.“ (Pozornost je vše, co potřebujete). NIPS 2017.
Jianpeng Cheng, Li Dong a Mirella Lapata. „Dlouhá krátkodobá paměť – sítě pro strojové čtení“. EMNLP 2016.
Xiaolong Wang a kol. „Nelokální neuronové sítě“. CVPR 2018
Nikhil Mishra, Mostafa Rohaninejad, Xi Chen a Pieter Abbeel. „A simple neural attentive meta-learner“. ICLR 2018.
„WaveNet: A Generative Model for Raw Audio“ – 8. září 2016, DeepMind.
Oriol Vinyals, Meire Fortunato a Navdeep Jaitly. „Ukazovací sítě.“ NIPS 2015.
Alex Graves, Greg Wayne a Ivo Danihelka. „Neural turing machines.“ arXiv preprint arXiv:1410.5401 (2014).