Proč Apple věří, že je lídrem v oblasti umělé inteligence, a proč se podle kritiků mýlí

![]()
Machine learning (ML) a umělá inteligence (AI) jsou nyní součástí téměř všech funkcí iPhonu, ale Apple tyto technologie nevyzdvihuje tak jako někteří jeho konkurenti. Chtěl jsem více porozumět přístupu společnosti Apple , a tak jsem strávil hodinu rozhovorem se dvěma vedoucími pracovníky společnosti Apple o strategii společnosti – a o důsledcích všech nových funkcí založených na AI a ML na soukromí.
Historicky nemá společnost Apple v této oblasti na veřejnosti pověst lídra. Částečně je to proto, že lidé si AI spojují s digitálními asistenty a recenzenti často označují Siri za méně užitečnou než Google Assistant nebo Amazon Alexa. A v případě ML mnoho technologických nadšenců tvrdí, že více dat znamená lepší modely – ale Apple není známý sběrem dat stejným způsobem jako například Google.
Přesto Apple do většiny zařízení, která dodává, zahrnul specializovaný hardware pro úlohy strojového učení. Funkce řízené strojovou inteligencí stále častěji dominují keynotům, na nichž vedoucí pracovníci společnosti Apple vystupují na pódium, aby představili nové funkce pro iPhony, iPady nebo hodinky Apple Watch. Uvedení počítačů Mac s křemíkem Apple koncem letošního roku přinese řadu stejných prvků strojové inteligence i do notebooků a stolních počítačů společnosti.
V návaznosti na oznámení křemíku Apple jsem dlouze hovořil s Johnem Giannandreou, senior viceprezidentem společnosti Apple pro strategii strojového učení a umělé inteligence, a také s Bobem Borchersem, viceprezidentem pro produktový marketing. Popsali mi filozofii společnosti Apple v oblasti umělé inteligence, vysvětlili, jak strojové učení podporuje některé funkce, a vášnivě obhajovali strategii společnosti Apple v oblasti AI/ML.
Jaká je strategie společnosti Apple v oblasti umělé inteligence?
Jannandrea i Borchers nastoupili do společnosti Apple v posledních několika letech; každý z nich dříve pracoval ve společnosti Google. Borchers se po určité době odchodu do Applu skutečně vrátil; do roku 2009 byl vrchním ředitelem marketingu pro iPhone. A o Giannandreaově přeběhnutí ze společnosti Google do Applu v roce 2018 se široce informovalo; předtím byl šéfem oddělení umělé inteligence a vyhledávání ve společnosti Google.
Google a Apple jsou zcela odlišné společnosti. Google má pověst společnosti, která se podílí na výzkumné komunitě v oblasti umělé inteligence a v některých případech ji i vede, zatímco Apple dělal většinu své práce za zavřenými dveřmi. To se v posledních letech změnilo, protože strojové učení pohání řadu funkcí v zařízeních Apple a Apple zvýšil svou angažovanost v komunitě AI.
„Když jsem nastoupil do Applu, byl jsem už uživatelem iPadu a miloval jsem tužku,“ řekl mi Giannandrea (který kolegům říká „J.G.“). „Takže jsem sledoval softwarové týmy a říkal jsem: ‚Dobře, kde je tým pro strojové učení, který pracuje na rukopisu? A nemohl jsem ho najít.“ Ukázalo se, že tým, který hledal, neexistuje – což ho podle jeho slov překvapilo vzhledem k tomu, že strojové učení je dnes jedním z nejlepších nástrojů, které jsou pro tuto funkci k dispozici.
„Věděl jsem, že existuje tolik strojového učení, které by měl Apple dělat, že mě překvapilo, že se ve skutečnosti nedělá všechno. A to se v posledních dvou až třech letech dramaticky změnilo,“ řekl. „Opravdu upřímně si myslím, že neexistuje žádný kout systému iOS nebo zkušeností společnosti Apple, který by v příštích několika letech neproměnilo strojové učení.“
Ptal jsem se Giannandrea, proč má pocit, že Apple je pro něj to pravé místo. Jeho odpověď byla dvojnásob výstižným shrnutím strategie společnosti v oblasti umělé inteligence:
Myslím si, že Apple vždy stál na tomto průsečíku kreativity a technologie. A myslím si, že když přemýšlíte o vytváření chytrých zážitků, je opravdu zásadní mít vertikální integraci, a to až dolů od aplikací přes rámce až po křemík… Myslím, že je to cesta, a myslím, že to je budoucnost počítačových zařízení, která máme, je to, že jsou chytrá, a že, že chytrá jaksi zmizí.“
Borchers se také přidal a dodal: „To je jednoznačně náš přístup, u všeho, co děláme, který je: ‚Zaměřme se na to, jaký je přínos, ne na to, jak jste se tam dostali. A v nejlepších případech se to stává automatickým. Zmizí to… a vy se prostě soustředíte na to, co se stalo, na rozdíl od toho, jak se to stalo.“
Když znovu mluvil o příkladu s rukopisem, Giannandrea uvedl, že Apple má nejlepší předpoklady k tomu, aby „vedl odvětví“ při vytváření funkcí a produktů založených na strojové inteligenci:
Vytvořili jsme tužku, vytvořili jsme iPad, vytvořili jsme software pro obojí. Jsou to prostě jedinečné možnosti, jak odvést opravdu, opravdu dobrou práci. V čem odvádíme opravdu, opravdu dobrou práci? Umožnit někomu dělat si poznámky a být produktivní se svými kreativními myšlenkami na digitálním papíře. Zajímá mě, jak se tyto zkušenosti budou používat ve světě ve velkém měřítku.“
Dal to do kontrastu se společností Google. „Google je úžasná společnost a pracují v ní opravdu skvělí technologové,“ řekl. „Ale jejich obchodní model je v zásadě jiný a nejsou známí tím, že by dodávali spotřebitelské zážitky, které používají stovky milionů lidí.“
Jak dnes Apple využívá strojové učení?
Apple má ve zvyku ve svých nedávných marketingových prezentacích připisovat strojovému učení zásluhy za zlepšení některých funkcí iPhonu, Apple Watch nebo iPadu, ale málokdy jde do detailů – a většina lidí, kteří si iPhone koupí, se na tyto prezentace stejně nikdy nedívala. Srovnejte to například s Googlem, který umělou inteligenci staví do centra většiny svých sdělení pro zákazníky.
V softwaru a zařízeních Applu se strojové učení používá na mnoha místech, většina z nich je nová teprve posledních pár let.
Strojové učení pomáhá softwaru iPadu rozlišovat mezi náhodným přitlačením dlaně na obrazovku při kreslení tužkou Apple Pencil a záměrným přitlačením, jehož cílem je zadat vstup. Používá se ke sledování návyků uživatelů při používání, aby se optimalizovala výdrž baterie a nabíjení zařízení, a to jak kvůli zlepšení doby, kterou mohou uživatelé strávit mezi jednotlivými nabíjeními, tak kvůli ochraně dlouhodobé životaschopnosti baterie. Používá se k doporučování aplikací.
Pak je tu Siri, což je snad jediná věc, kterou každý uživatel iPhonu okamžitě vnímá jako umělou inteligenci. Strojové učení řídí několik aspektů Siri, od rozpoznávání řeči až po pokusy Siri nabízet užitečné odpovědi.
Zkušení majitelé iPhonů si také mohou všimnout, že strojové učení stojí za schopností aplikace Fotky automaticky třídit obrázky do předem připravených galerií nebo že vám přesně nabídne fotografie kamarádky jménem Jane, když její jméno zadáte do vyhledávacího pole aplikace.
V jiných případech si možná jen málo uživatelů uvědomí, že za prací stojí strojové učení. Například váš iPhone může pořídit několik snímků v rychlém sledu pokaždé, když klepnete na tlačítko spouště. Algoritmus vycvičený ML pak analyzuje každý snímek a může složit to, co považuje za nejlepší části každého snímku, do jednoho výsledku.

Součástí telefonů jsou už dlouho procesory obrazového signálu (ISP) pro digitální zlepšování kvality fotografií v reálném čase, ale Apple tento proces v roce 2018 urychlil tím, že ISP v iPhonu úzce spolupracuje s Neural Enginem, nedávno přidaným procesorem společnosti zaměřeným na strojové učení.
Požádal jsem Giannandrea, aby vyjmenoval některé způsoby, jak Apple ve svém softwaru a produktech z poslední doby využívá strojové učení. Uvedl nepřeberný seznam příkladů:
Je tu celá řada nových zážitků, které jsou poháněny strojovým učením. A jsou to věci jako překlad jazyka nebo diktování v zařízení nebo naše nové funkce týkající se zdraví, jako je spánek a mytí rukou, a věci, které jsme v minulosti vydali v oblasti zdraví srdce a podobně. Myslím, že v systému iOS je stále méně a méně míst, kde nepoužíváme strojové učení.
Je těžké najít část prostředí, kde se neprovádí nějaké prediktivní . Třeba predikce aplikací nebo predikce klávesnice, nebo moderní fotoaparáty smartphonů dělají za scénou spoustu strojového učení, aby zjistily to, čemu se říká „saliency“, což je něco jako, co je nejdůležitější část obrazu? Nebo když si představíte, že děláte rozmazání pozadí, děláte portrétní režim.
Všechny tyto věci využívají základní funkce strojového učení, které jsou zabudované do jádra platformy Apple. Takže je to skoro jako: „Najděte mi něco, kde nepoužíváme strojové učení.“
Borchers také jako důležitý příklad uvedl funkce přístupnosti. „Ty jsou díky tomu zásadně zpřístupněny a umožněny,“ řekl. „Věci jako schopnost detekce zvuku, která pro tuto konkrétní komunitu mění pravidla hry, jsou možné díky investicím v průběhu času a zabudovaným schopnostem.“
Dále jste si mohli všimnout, že aktualizace softwaru a hardwaru společnosti Apple v posledních několika letech kladou důraz na funkce rozšířené reality. Většina těchto funkcí je možná díky strojovému učení. Per Giannandrea:
Strojové učení se v rozšířené realitě hodně používá. Těžkým problémem je tam to, čemu se říká SLAM, tedy Simultaneous Localization And Mapping. Takže se snažíte pochopit, že když máte iPad s lidarovým skenerem a pohybujete se, co vidí? A sestavit 3D model toho, co vlastně vidí.
To dnes využívá hluboké učení a musíte být schopni to dělat v zařízení, protože to chcete být schopni dělat v reálném čase. Nemělo by smysl, kdybyste mávali iPadem a pak to třeba museli dělat v datovém centru. Takže obecně bych řekl, že o tom přemýšlím tak, že zejména hluboké učení nám dává možnost přejít od surových dat k sémantice těchto dat.“
Úlohy strojového učení provádí Apple stále častěji lokálně v zařízení, na hardwaru, jako je Apple Neural Engine (ANE), nebo na speciálně navržených GPU (grafických procesorech) společnosti. Giannandrea a Borchers tvrdili, že právě díky tomuto přístupu se strategie společnosti Apple mezi konkurencí odlišuje.
Proč to dělat v zařízení?
Jannandrea i Borchers v našem rozhovoru přesvědčivě argumentovali, že funkce, které jsme právě probrali, jsou možné díky – nikoli navzdory – tomu, že se veškerá práce provádí lokálně v zařízení.
Existuje běžné vyprávění, které strojové učení redukuje na myšlenku, že více dat znamená lepší modely, což zase znamená lepší uživatelské zkušenosti a produkty. Je to jeden z důvodů, proč pozorovatelé často ukazují na Google, Amazon nebo Facebook jako na pravděpodobné vládce kohouta umělé inteligence; tyto společnosti provozují obrovské stroje na sběr dat, částečně proto, že provozují a mají naprostý přehled o tom, co se stalo klíčovou digitální infrastrukturou pro velkou část světa. Podle tohoto měřítka je Apple některými považován za společnost, která si pravděpodobně nepovede tak dobře, protože její obchodní model je jiný a veřejně se zavázala omezit sběr dat.
Když jsem tyto pohledy přednesl Giannandreaovi, neudržel se:
Ano, chápu, že toto vnímání větších modelů v datových centrech je nějak přesnější, ale ve skutečnosti je to špatně. Je to vlastně technicky špatně. Je lepší provozovat model v blízkosti dat, než je přesouvat. A ať už se jedná o údaje o poloze – jako co děláte – údaje o cvičení – co dělá akcelerometr ve vašem telefonu – je prostě lepší být blízko zdroje dat, a tak je také zachováno soukromí.
Borchers i Giannandrea opakovaně poukazovali na důsledky ochrany soukromí při této práci v datovém centru, ale Giannandrea řekl, že lokální zpracování je také o výkonu.
„Jednou z dalších velkých věcí je latence,“ řekl. „Pokud něco posíláte do datového centra, je opravdu těžké dělat něco se snímkovou frekvencí. Proto máme v obchodě s aplikacemi spoustu aplikací, které dělají věci, jako je odhad pózy, například zjišťují, jak se člověk pohybuje, a identifikují, kde má například nohy a ruce. To je API na vysoké úrovni, které nabízíme. To je užitečné pouze tehdy, když to můžete dělat v podstatě se snímkovou frekvencí.“
Uvedl další příklad spotřebitelského využití:
Fotíte a chvíli před tím, než pořídíte fotografii fotoaparátem, fotoaparát vidí vše v reálném čase. Může vám pomoci při rozhodování o tom, kdy fotografii pořídit. Kdybyste toto rozhodnutí chtěli učinit na serveru, museli byste na server posílat každý jednotlivý snímek, abyste se mohli rozhodnout, jak fotografii pořídit. To nedává smysl, že? Takže je prostě spousta zážitků, které byste chtěli vytvořit a které je lepší udělat na okrajovém zařízení.
Na otázku, jak se Apple rozhoduje, kdy něco udělat na zařízení, odpověděl Giannandrea jednoduše: „Když můžeme dosáhnout nebo překonat kvalitu toho, co bychom mohli udělat na serveru.“
Oběma vedoucím pracovníkům společnosti Apple navíc připadá vlastní křemík společnosti Apple – konkrétně křemík Apple Neural Engine (ANE), který je součástí iPhonů od iPhonu 8 a iPhonu X – jako předpoklad pro toto zpracování na zařízení. Neural Engine je osmijádrový neuronový procesor (NPU), který Apple navrhl tak, aby zvládal určité druhy úloh strojového učení.
„Je to několikaletá cesta, protože před pěti lety nebyl k dispozici hardware, který by to zvládl na hraně,“ řekl Giannandrea. „Design ANE je zcela škálovatelný. V iPadu je větší ANE než v telefonu, než v hodinkách Apple Watch, ale vrstva API CoreML pro naše aplikace a také pro aplikace vývojářů je v podstatě stejná v celé řadě produktů.“
Když Apple veřejně mluvil o Neural Engine, společnost sdílela čísla o výkonu, například 5 bilionů operací za sekundu v čipu A12 z roku 2018. O architektuře čipu se však konkrétněji nevyjádřila. Na slajdech v prezentacích Applu je to doslova černá skříňka.

Vzhledem k tomu jsem chtěl vědět, zda Giannandrea osvětlí, jak Neural Engine funguje pod kapotou, ale odmítl jít do větších podrobností. Místo toho řekl, že vývojáři aplikací mohou vše, co potřebují vědět, získat z CoreML – rozhraní API pro vývoj softwaru, které vývojářům poskytuje přístup ke schopnostem strojového učení iPhonu.
Vývojářské rozhraní API CoreML velmi jasně popisuje druhy modelů strojového učení, runtime modely, které podporujeme… Máme stále větší sadu jader, která podporujeme. A na CoreML se zaměříte z některé z populárních věcí pro strojové učení, jako je PyTorch nebo TensorFlow, a pak v podstatě zkompilujete svůj model a předáte ho CoreML.
Úkolem CoreML je zjistit, kde se má tento model spustit. Může se stát, že správné bude spustit model na ANE, ale také může být správné spustit model na GPU nebo spustit model na CPU. A náš procesor má optimalizace i pro strojové učení.
Během našeho rozhovoru oba vedoucí pracovníci poukazovali jak na aplikace vývojářů třetích stran, tak na vlastní aplikace společnosti Apple. Strategie zde nespočívá pouze v pohonu služeb a funkcí vytvořených společností Apple, ale v otevření alespoň části těchto schopností široké komunitě vývojářů. Apple spoléhá na vývojáře při inovaci svých platforem již od prvního otevření App Store v roce 2008. Společnost si často půjčuje nápady, se kterými tito vývojáři přišli, když aktualizuje své vlastní, interně vytvořené aplikace.
Zařízení Apple samozřejmě nejsou jediná, která mají zabudované čipy pro strojové učení. Například společnosti Samsung, Huawei a Qualcomm obsahují NPU ve svých systémech na čipu. A také Google nabízí vývojářům rozhraní API pro strojové učení. Přesto se strategie a obchodní model společnosti Google výrazně liší. Telefony s Androidem neumějí zdaleka tak širokou škálu úloh strojového učení řešit lokálně.
Macy s křemíkem Apple
Těžištěm mého rozhovoru s Giannandreou a Borchersem nebylo velké oznámení, které společnost učinila na konferenci WWDC před několika týdny – chystané uvedení Maců s křemíkem Apple. Když jsem však spekuloval, že jedním z mnoha důvodů, proč Apple navrhuje Macy s vlastními čipy, by mohlo být začlenění Neural Engine, Borchers řekl:
Poprvé budeme mít společnou platformu, křemíkovou platformu, která může podporovat to, co chceme dělat my a co chtějí dělat naši vývojáři…. Tato schopnost odemkne některé zajímavé věci, které nás napadnou, ale pravděpodobně ještě důležitější bude, že odemkne spoustu věcí pro další vývojáře, kteří budou postupovat.

Giannandrea uvedl jeden konkrétní příklad, jak budou na Macu využity nástroje a hardware pro strojové učení od Applu:
Nevím, jestli jste viděli tu ukázku v pořadu State of the Union, ale v podstatě šlo o to: mít k dispozici video, projít ho snímek po snímku nebo po snímcích a provést detekci objektů. A na našem křemíku to můžete dělat více než o řád rychleji než na starší platformě.
A pak řeknete: „No, to je zajímavé. Proč je to užitečné?“ Představte si editor videa, kde byste měli vyhledávací pole a mohli byste říct: „Najdi mi pizzu na stole“. A ono by se to na ten snímek prostě vyčistilo… To jsou typy zkušeností, se kterými podle mě budou lidé přicházet. Velmi si přejeme, aby vývojáři tyto rámce používali a prostě nás překvapili tím, co s tím vlastně dokážou udělat.
Apple na své vývojářské konferenci řekl, že od konce tohoto roku plánuje dodávat počítače Mac s vlastním křemíkem.
A co soukromí?
Soukromí bylo v posledních několika letech ve sděleních Applu uživatelům na prvním místě. Znovu a znovu se o něm mluví na keynote a v marketingových materiálech, připomíná se jím celý systém iOS a často se objevuje v rozhovorech – což byl i tento případ.
„Lidé se obávají umělé inteligence ve velkém, protože nevědí, co to je,“ řekl mi Giannandrea. „Myslí si, že je schopnější, než je, nebo přemýšlejí o tomto sci-fi pohledu na AI, a máte vlivné lidi jako Bill Gates a Elon Musk a další, kteří říkají, že je to nebezpečná technologie.“
Podle něj je humbuk kolem AI ze strany jiných velkých technologických společností pro marketingové úsilí těchto společností negativní, nikoliv pozitivní, „protože lidé se této technologie obávají.“
V tomto případě nemusí být termín „AI“ užitečný. Evokuje zákeřné syntetické padouchy z popkultury, jako je Skynet nebo HAL 9000. Většina odborníků na aplikovanou umělou inteligenci vám však řekne, že tento temný výsledek je daleko od reality. Technika řízená strojovým učením s sebou nese mnohá rizika – například zdědí a posílí lidské předsudky – ale to, že by se stala darebákem a násilně zaútočila na lidstvo, se nezdá být v blízké budoucnosti pravděpodobné.
Strojové učení ve skutečnosti nečiní stroje inteligentními stejným způsobem, jako jsou lidé. Z tohoto a dalších důvodů mnozí odborníci na umělou inteligenci (včetně Giannandrea) navrhují alternativní termíny jako „strojová inteligence“, které nevedou paralely s lidskou inteligencí.
Ať už je pojmenování jakékoliv, strojové učení s sebou může přinést velmi reálné a aktuální nebezpečí: narušení soukromí uživatelů. Některé společnosti agresivně shromažďují osobní údaje uživatelů a odesílají je do datových center, což zdůvodňují strojovým učením a tréninkem.
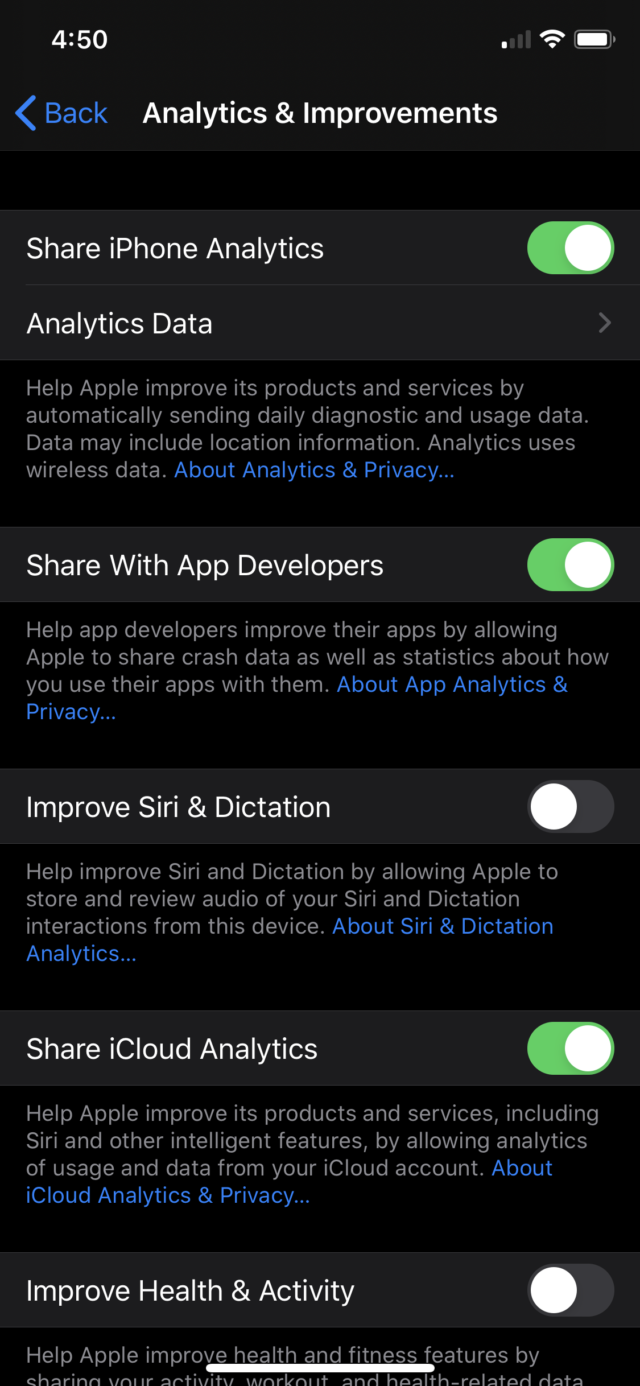
Jak bylo uvedeno výše, společnost Apple provádí velkou část tohoto shromažďování a zpracování lokálně v zařízení uživatele. Giannandrea toto rozhodnutí výslovně spojil s obavami o ochranu soukromí. „Myslím, že k tomu zaujímáme velmi jasné stanovisko, které zní, že tuto pokročilou technologii strojového učení budeme v co největším počtu případů provádět ve vašem zařízení a že data neopustí vaše zařízení,“ řekl. „Máme velmi jasné stanovisko, proč si myslíme, že naše zařízení jsou bezpečnější nebo lepší nebo by měla být důvěryhodnější.“
Jako konkrétní příklad této filozofie v praxi použil převod textu na řeč:
Pokud řeknete něco jako: „Přečti mi moje zprávy od Boba.“
Pokud řeknete něco jako: „Přečti mi mé zprávy od Boba. Syntéza textu na řeč probíhá v zařízení, v Neural Engine – kombinaci Neural Engine a CPU. A kvůli tomu jsme nikdy neviděli obsah vaší zprávy od Boba, protože ji přečte váš telefon – nepřečtou ji servery. Takže obsah té zprávy se nikdy nedostal na server…
Takže to je skvělý příklad pokročilé technologie, která vlastně zlepšuje jak užitek pro uživatele, protože hlas je syntetizován v zařízení, takže i když jste odpojeni, stále to bude fungovat. Ale také příběh o ochraně soukromí. Ve skutečnosti je to opravdu těžké. Na to, aby moderní vysoká kvalita byla syntetizována v zařízení, které si můžete strčit do kapsy, bylo vynaloženo hodně opravdu náročného inženýrství.
Jistě, v mnoha případech musíte pro strojové učení použít nějaká uživatelská data. Jak přesně tedy Apple používá uživatelská data, která zpracovává? Giannandrea vysvětlil:
Všeobecně řečeno, modely vytváříme dvěma způsoby. Jeden spočívá v tom, že shromažďujeme a označujeme data, což je vhodné za mnoha a mnoha okolností. A pak je tu případ, kdy žádáme uživatele, aby nám darovali svá data. Nejvýraznějším příkladem je Siri, kde při nastavení iPhonu říkáme: „Chtěli byste pomoci vylepšit Siri?“
To je případ, kdy je nám darováno určité množství dat a velmi malé procento z nich pak může být použito pro trénink. Ale u mnoha a mnoha věcí, o kterých tu mluvíme – řekněme u rukopisu – můžeme shromáždit dostatek dat k tomu, abychom tento model vycvičili tak, aby pracoval v podstatě s rukopisem každého člověka, aniž bychom museli použít jakákoli data od spotřebitelů.“
Některé z těchto výzev s žádostí o použití vašich dat byly přidány nedávno. Loni v létě se objevila zpráva, že Siri nahrává, co uživatelé říkají po náhodné aktivaci; dodavatelé, kteří měli za úkol zajišťovat kvalitu funkcí Siri, některé z těchto nahrávek slyšeli.
Apple na to reagoval závazkem, že zvukové záznamy týkající se Siri bude ukládat až poté, co se uživatelé výslovně rozhodnou Siri vylepšit sdílením nahrávek (toto chování bylo zavedeno v systému iOS 13.2), a poté převedl veškeré zajišťování kvality do vlastních rukou. Zeptal jsem se, co Apple dělá s těmito daty jinak, než dělali dodavatelé. Giannandrea odpověděl:
Máme spoustu ochranných opatření. Například existuje proces identifikace, zda byl zvuk určen pro asistenta, který je zcela oddělený od procesu skutečné kontroly zvuku. Takže interně děláme spoustu věcí, abychom zajistili, že nezachytíme – a pak vlastně nezahodíme – žádný náhodný zvuk.
Ale pokud nejste ochotni skutečně zajistit kvalitu, podle vašeho názoru, funkce, pak nikdy nezlepšíte náhodné nahrávky. Jak víte, strojové učení vyžaduje, abyste jej neustále zlepšovali. Takže jsme ve skutečnosti přepracovali mnoho našich pracovních postupů a procesů současně s tím, jak jsme tuto práci přenesli dovnitř. Jsem si velmi jistý, že máme jeden z nejlepších procesů pro zlepšování asistenta způsobem, který zachovává soukromí.“
Je jasné, že se Apple snaží prosazovat ochranu soukromí jako klíčovou funkci svých zařízení; z Giannandrea to vyznělo jako opravdové přesvědčení. Mohlo by to ale také Applu pomoci na trhu, protože jeho největší konkurent v oblasti mobilních zařízení má mnohem horší výsledky v oblasti ochrany soukromí, a to ponechává prostor, protože uživatelé se stále více zajímají o dopady umělé inteligence na soukromí.
Během našeho rozhovoru se Giannandrea i Borchers vraceli ke dvěma bodům strategie Applu: 1) je výkonnější provádět úlohy strojového učení lokálně a 2) je to „šetrnější k soukromí“ – tuto konkrétní formulaci Giannandrea v našem rozhovoru několikrát zopakoval.
Uvnitř černé skříňky
Po dlouhé době, kdy se na funkcích umělé inteligence pracovalo převážně v utajení, se důraz společnosti Apple na strojové učení v posledních několika letech výrazně rozšířil.
Společnost pravidelně publikuje, sponzoruje akademickou sféru, má stipendia, sponzoruje laboratoře, jezdí na konference o AI/ML. Nedávno obnovila blog o strojovém učení, kde sdílí některé výsledky svého výzkumu. Také nabírá inženýry a další lidi z oblasti strojového učení – včetně samotného Giannandrey, který se do ní pustil už před dvěma lety.
ReklamaNevede výzkumnou komunitu tak jako Google, ale Apple se snaží, aby vedl alespoň v tom, že přináší plody strojového učení více uživatelům.
Vzpomínáte, jak Giannandrea řekl, že ho překvapilo, že se strojové učení nepoužívá pro psaní rukou pomocí tužky? Dále se věnoval tvorbě týmu, který to dokázal. A v tandemu s dalšími týmy pokročili s rukopisem založeným na strojovém učení – základním kamenem iPadOS 14.
„V Applu máme spoustu úžasných odborníků na strojové učení a dál je najímáme,“ řekl Gianandrea. „Zjistil jsem, že je velmi snadné přilákat do Applu lidi světové úrovně, protože v našich produktech je stále zřejmější, že strojové učení má zásadní význam pro zážitky, které chceme pro uživatele vytvářet.“
Po krátké pauze dodal: „Největší problém mám asi s tím, že mnoho našich nejambicióznějších produktů jsou ty, o kterých nemůžeme mluvit, a tak je trochu prodejní problém někomu říct: ‚Pojď pracovat na nejambicióznější věci vůbec, ale nemůžu ti říct, co to je.'“
ReklamaPokud lze věřit velkým technologickým společnostem a investicím rizikového kapitálu, umělá inteligence a strojové učení budou v příštích letech jen všudypřítomnější. Ať už to dopadne jakkoli, Giannandrea a Borchers jasně řekli jednu věc: strojové učení se nyní podílí na většině toho, co Apple se svými produkty dělá, a na mnoha funkcích, které spotřebitelé denně používají. A vzhledem k tomu, že Neural Engine se od letošního podzimu objeví i v počítačích Mac, role strojového učení ve společnosti Apple pravděpodobně dále poroste.